实时语音通信发展到今天,用户对通话语音质量提出了越来越高的要求。由于终端设备的多样性以及使用场景的差异,声音问题依然存在。传统的音频处理技术从声音信号本身出发,挖掘其时频特性,作出假设,建立物理模型,很多参数都需要人工进行精细化微调,比较费时费力。随着AI技术的发展,凭借着其强大的拟合能力,利用数据驱动,为改善音频体验提供了更多的可能性。
关于理论部分,包括论文有很多,每种想法都存在一些问题,包括工程方面的,如需做落地,效果稳定良好,还需要做很多更多的工作,这里稍微做了下总结,深度学习降噪基本都在这份分享的PPT上面,降噪部分有些文章可能有些不太新了,但是还是有学习参考意义的。
此处就分享几张DNN处理后的样本,增加一下新手的信心,处理非平稳噪声,效果还是非常明显的。
white:
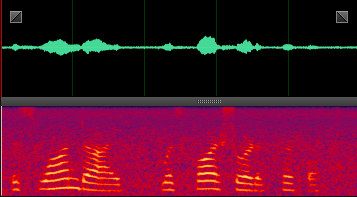
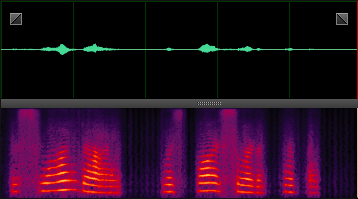
destroyerengine:
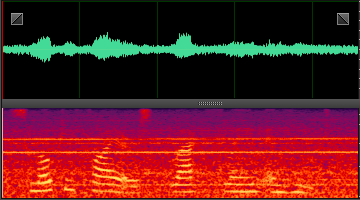
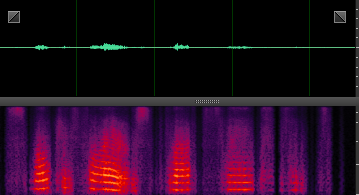
n32:
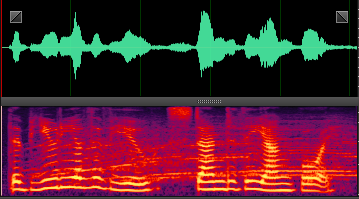
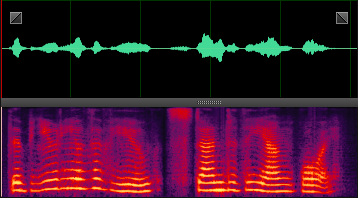
n38
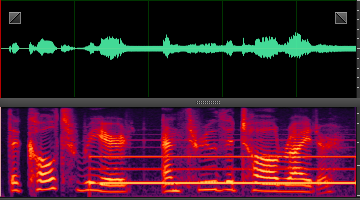
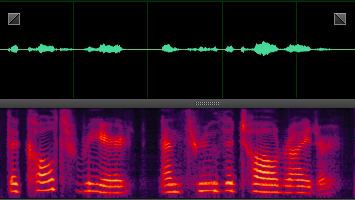
n61:
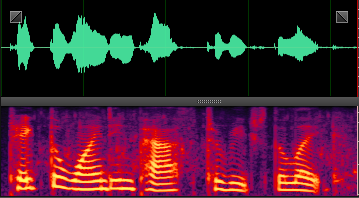

sil:
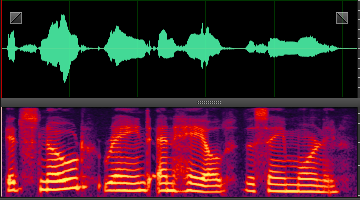
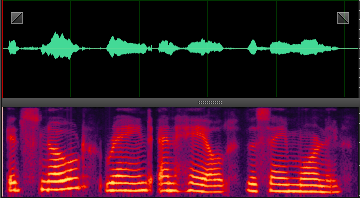
coffee:

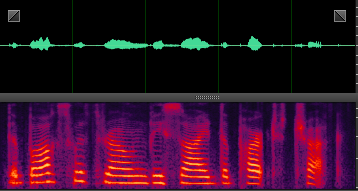
PPT链接地址:
百度云盘
链接: https://pan.baidu.com/s/1vvUiiGtu-HUdZwclBSInZA 提取码: bsc5
实时语音通信的总结和深度学习降噪资料都可以直接在QQ群下载到
QQ群:音频信号处理读书会 485186545
如上群已满,请加新群: 音频处理与机器学习 238816966