简介:介绍生产者消费者模型,及go简单实现的demo。
一、生产者消费者模型
生产者消费者模型:某个模块(函数等〉负责产生数据,这些数据由另一个模块来负责处理(此处的模块是广义的,可以是类、函数、协程、线程、进程等)。产生数据的模块,就形象地称为生产者;而处理数据的模块,就称为消费者。
单单抽象出生产者和消费者,还够不上是生产者消费者模型。该模式还需要有一个缓冲区处于生产者和消费者之间,作为一个中介。生产者把数据放入缓冲区,而消费者从缓冲区取出数据。大概的结构如下图。

假设你要寄一件快递,大致过程如下。.
1.把快递封好——相当于生产者制造数据。
2.把快递交给快递中心——相当于生产者把数据放入缓冲区。
3.邮递员把快递从快递中心取出——相当于消费者把数据取出缓冲区。
这么看,有了缓冲区就有了以下好处:
解耦:降低消费者和生产者之间的耦合度。有了快递中心,就不必直接把快递交给邮寄员,邮寄快递的人不对邮寄员产生任何依赖,如果某一个天邮寄员换人了,对于邮寄快递的人也没有影响。假设生产者和消费者分别是两个类。如果让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖(也就是耦合)。将来如果消费者的代码发生变化,可能会真接影响到生产者。而如果两者都依赖于某个缓冲区,两者之间不直接依赖,耦合度也就相应降低了。
并发:生产者消费者数量不对等,依然能够保持正常通信。由于函数调用是同步的(或者叫阻塞的),在消费者的方法没有返回之前,生产者只好一直等在那边。万一消费者处理数据很慢,生产者只能等着浪费时间。使用了生产者消费者模式之后,生产者和消费者可以是两个独立的并发主体。生产者把制造出来的数据往缓冲区一丢,就可以再去生产下一个数据。基本上不用依赖消费者的处理速度。邮寄快递的人直接把快递扔个快递中心之后就不用管了。
缓存:生产者消费者速度不匹配,暂存数据。如果邮寄快递的人一次要邮寄多个快递,那么邮寄员无法邮寄,就可以把其他的快递暂存在快递中心。也就是生产者短时间内生产数据过快,消费者来不及消费,未处理的数据可以暂时存在缓冲区中。
二、Go语言实现
单向channel最典型的应用是“生产者消费者模型”。channel又分为有缓冲和无缓冲channel。channel中参数传递的时候,是作为引用传递。
1、无缓冲channel
示例代码一实现如下
package main
import "fmt"
func producer(out chan <- int) {
for i:=0; i<10; i++{
data := i*i
fmt.Println("生产者生产数据:", data)
out <- data // 缓冲区写入数据
}
close(out) //写完关闭管道
}
func consumer(in <- chan int){
// 同样读取管道
//for{
// val, ok := <- in
// if ok {
// fmt.Println("消费者拿到数据:", data)
// }else{
// fmt.Println("无数据")
// break
// }
//}
// 无需同步机制,先做后做
// 没有数据就阻塞等
for data := range in {
fmt.Println("消费者得到数据:", data)
}
}
func main(){
// 传参的时候显式类型像隐式类型转换,双向管道向单向管道转换
ch := make(chan int) //无缓冲channel
go producer(ch) // 子go程作为生产者
consumer(ch) // 主go程作为消费者
}
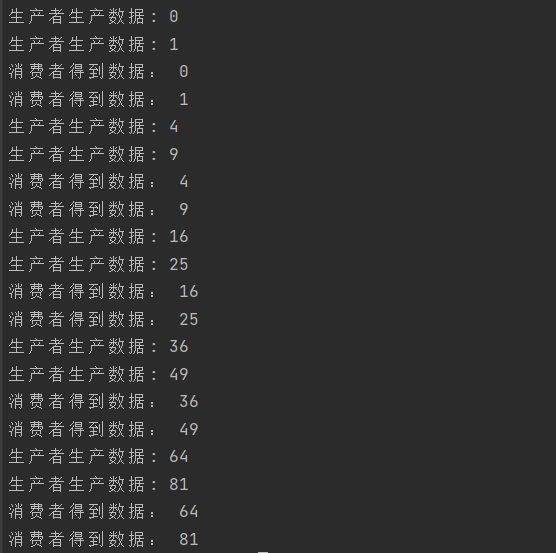
这里使用无缓冲channel,生产者生产一次数据放入channel,然后消费者从channel读取数据,如果没有只能等待,也就是阻塞,直到管道被关闭。所以宏观是生产者消费者同步执行。
另外:这里是只而外开辟一个go程执行生产者,主go程执行消费者,如果也是用一个新的go程执行消费者,就需要阻塞main函数中的go程,否则不等待消费者和生产者执行完毕,主go程退出,程序直接结束,如示例代码三。
生产者每一次生产,消费者也只能拿到一次数据,缓冲区作用不大。结果如下:
2、有缓冲channel
示例代码二如下
package main
import "fmt"
func producer(out chan <- int) {
for i:=0; i<10; i++{
data := i*i
fmt.Println("生产者生产数据:", data)
out <- data // 缓冲区写入数据
}
close(out) //写完关闭管道
}
func consumer(in <- chan int){
// 无需同步机制,先做后做
// 没有数据就阻塞等
for data := range in {
fmt.Println("消费者得到数据:", data)
}
}
func main(){
// 传参的时候显式类型像隐式类型转换,双向管道向单向管道转换
ch := make(chan int, 5) // 添加缓冲区,5
go producer(ch) // 子go程作为生产者
consumer(ch) // 主go程作为消费者
}
有缓冲channel,只修改ch := make(chan int, 5) // 添加缓冲一句,只要缓冲区不满,生产者可以持续向缓冲区channel放入数据,只要缓冲区不为空,消费者可以持续从channel读取数据。就有了异步,并发的特性。
结果如下:
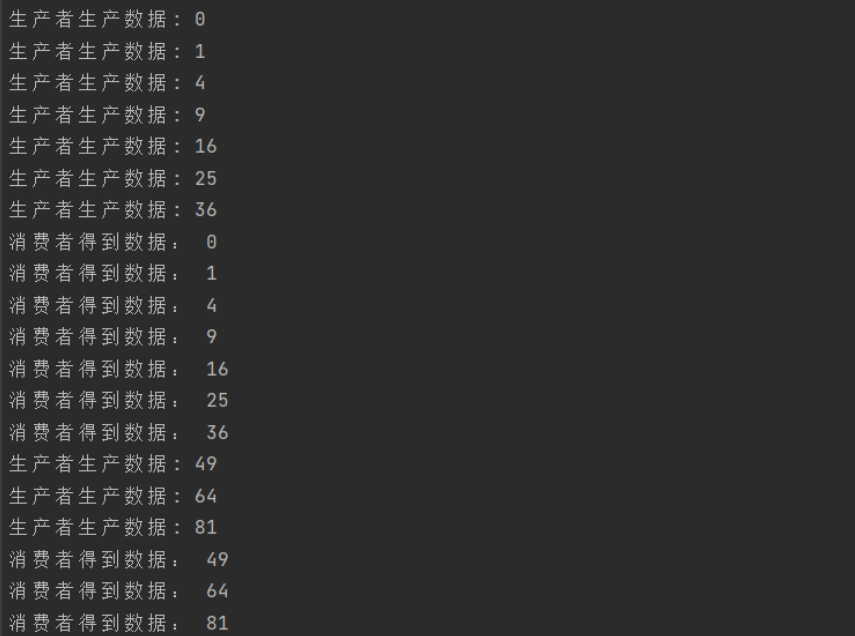
这里之所以终端生产者连续打印了大于缓冲区容量的数据,是因为终端打印属于系统调用也是有延迟的,IO操作的时候,生产者同时向管道写入,请求打印,管道的写入读取与终端输出打印速度不匹配。
三、实际应用
实际应用中,同时访问同一个公共区域,同时进行不同的操作。都可以划分为生产者消费者模型,比如订单系统。
很多用户的订单下达之后,放入缓冲区或者队列中,然后系统从缓冲区中去读来真正处理。系统不必开辟多个线程来对应处理多个订单,减少系统并发的负担。通过生产者消费者模式,将订单系统与仓库管理系统隔离开,且用户可以随时下单(生产数据)。如果订单系统直接调用仓库系统,那么用户单击下订单按钮后,要等到仓库系统的结果返回。这样速度会很慢。
也就是:用户变成了生产者,处理订单管理系统变成了消费者。
代码示例三如下
package main
import (
"fmt"
"time"
)
// 模拟订单对象
type OrderInfo struct {
id int
}
// 生产订单--生产者
func producerOrder(out chan <- OrderInfo) {
// 业务生成订单
for i:=0; i<10; i++{
order := OrderInfo{id: i+1}
fmt.Println("生成订单,订单ID为:", order.id)
out <- order // 写入channel
}
// 如果不关闭,消费者就会一直阻塞,等待读
close(out) // 订单生成完毕,关闭channel
}
// 处理订单--消费者
func consumerOrder(in <- chan OrderInfo) {
// 从channel读取订单,并处理
for order := range in{
fmt.Println("读取订单,订单ID为:", order.id)
}
}
func main() {
ch := make(chan OrderInfo, 5)
go producerOrder(ch)
go consumerOrder(ch)
time.Sleep(time.Second * 2)
}
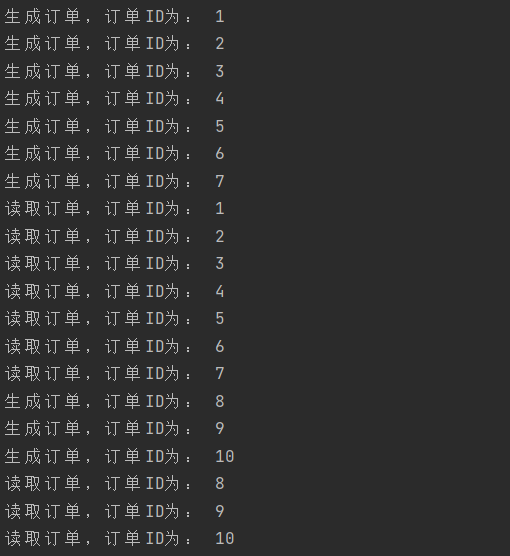
这里如上面逻辑类似,不同的是用一个,OrderInfo结构体模拟订单作为业务处理对象。主线程使用time.Sleep(time.Second * 2)阻塞,否则,程序立即停止。
结果如下: