一、UI自动化测试概述
1.1、为什么需要自动化测试
在学习自动化测试之前,首先需要思考清楚的是为什么需要学习自动化测试,以及今天业界谈的研发效能对测试而言意味着什么?其实这就需要在测试以及
整体研发的角度来思考问题,在今天这样的市场环境中,打造高质量的持续交付产品质量,基本是所有互联网研发团队的测试团队都追求的一个方向。在敏捷流行
的今天,以及新的技术在企业全面的落地,在测试而言,就需要通过测试技术的手段以及质量管理的思维能力,来提升测试效率,和交付满足市场期待的产品质量。
自动化测试是所有测试形式里面在目前而言,是最基础的也是最核心的,因为自动化测试连接了功能测试以及高阶的测试开发的测试技术栈的知识体系。即使初级
的测试同学,也得具备自动化测试的思维能力和技术能力。
1.2、UI自动化测试的必要性
与API自动化测试相比较,UI自动化测试不论是从执行效率还是编程难易度上,都比API自动化测试的成本是比较高的,如果单纯的从技术复杂度上来说,与API
的测试技术栈的体系是一样的,不同的是测试的思维以及背后的思想。但是还是需要比较清楚的是,UI自动化测试在DevOps的体系以及测试流水线上它是非常必要
的,只不过我们需要使用更加正确的姿势来利用好这个技术,比如使用它来验证核心的流程,而抛开更多的非主线的业务。不能单纯的说它的测试执行效率低,就完
全的否定UI自动化测试的价值,这样是很不理性的。在主流的UI自动化测试框架中,Selenium3经过多年的发展,它的技术体系以及生态体系都是非常完善的,能够得
到各大主流浏览器厂商的支持,和完善的document文档,以及与各个编程语言之间的兼容。本文章系列主要是以Python语言为主要的编程语言。当然,课程的整体设
计思考是借鉴我的书籍《Python自动化测试》来思考的,本课程《Selenium3自动化测试实战》主要在进行直播分享。
二、元素属性操作
在UI自动化测试中,最核心最基础的就是首先需要定位到元素的属性,然后就可以针对这个属性进行具体的相关的页面交互操作,比如进行进行关键字的输入,以及
点击的操作等。下面针对这部分进行详细的开展说明。
3.1 解读源码
我们先来看Selenium3的源码体系,当然我们知道元素的方法都是来自by模块中的By类,下面具体显示的是By类的源码,具体如下:
class By(object):
"""
Set of supported locator strategies.
"""
ID = "id"
XPATH = "xpath"
LINK_TEXT = "link text"
PARTIAL_LINK_TEXT = "partial link text"
NAME = "name"
TAG_NAME = "tag name"
CLASS_NAME = "class name"
CSS_SELECTOR = "css selector"从By类里面可以看到,元素属性定位的方式有8种,具体的8种在上面显示的非常详细,但是针对元素具体的方法都是在webdriver的模块里面,这些方法都在该模块
里面。从元素分类的角度而言,元素定位可以分为单个元素定位和多个元素定位,那么也就是从单个元素的方法有8种,多个元素的定位方法也是有8种,总共就16种
方法。这是分类方法的总结思维,在文章的最后我会怎么说利用这两个方法,让我们的元素定位更加简单和优雅,下面具体展示单个元素的方法和单个元素的方法,具
体如下:
def find_element(self, by=By.ID, value=None) -> WebElement:
"""
Find an element given a By strategy and locator.
:Usage:
::
element = driver.find_element(By.ID, 'foo')
:rtype: WebElement
"""
if by == By.ID:
by = By.CSS_SELECTOR
value = '[id="%s"]' % value
elif by == By.TAG_NAME:
by = By.CSS_SELECTOR
elif by == By.CLASS_NAME:
by = By.CSS_SELECTOR
value = ".%s" % value
elif by == By.NAME:
by = By.CSS_SELECTOR
value = '[name="%s"]' % value
return self.execute(Command.FIND_ELEMENT, {
'using': by,
'value': value})['value']
def find_elements(self, by=By.ID, value=None) -> List[WebElement]:
"""
Find elements given a By strategy and locator.
:Usage:
::
elements = driver.find_elements(By.CLASS_NAME, 'foo')
:rtype: list of WebElement
"""
if isinstance(by, RelativeBy):
_pkg = '.'.join(__name__.split('.')[:-1])
raw_function = pkgutil.get_data(_pkg, 'findElements.js').decode('utf8')
find_element_js = "return ({}).apply(null, arguments);".format(raw_function)
return self.execute_script(find_element_js, by.to_dict())
if by == By.ID:
by = By.CSS_SELECTOR
value = '[id="%s"]' % value
elif by == By.TAG_NAME:
by = By.CSS_SELECTOR
elif by == By.CLASS_NAME:
by = By.CSS_SELECTOR
value = ".%s" % value
elif by == By.NAME:
by = By.CSS_SELECTOR
value = '[name="%s"]' % value
# Return empty list if driver returns null
# See https://github.com/SeleniumHQ/selenium/issues/4555
return self.execute(Command.FIND_ELEMENTS, {
'using': by,
'value': value})['value'] or []3.2 常用元素定位实战
3.2.1 单个元素
本实战的都是围绕百度搜索输入框来进行开展,主要是百度大家都是比较熟悉的产品。
3.2.1.1、find_element_by_id
find_element_by_id()的方法主要指的是我们定位元素属性主要是以ID的方式来进行定位,ID一般都是唯一的,当儿开发同学某些时候为了保持这种唯一性,使用了
动态的ID方式,其实解决的思路是非常简单的,那就是xpath的解决思路了。这地方我们还是聚焦于ID的属性定位方式,百度搜索输入框的ID源码具体为:
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
这是百度搜索输入框的input输入框的源代码部分,从源代码我们就可以得到它的ID是kw,下面我们结合具体的代码来进行操作下,案例代码如下:
#! /usr/bin/env python
# -*- coding:utf-8 -*-
#author:无涯
from selenium import webdriver
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
driver.find_element_by_id('kw').send_keys('无涯 接口测试')
driver.quit()3.2.1.2、find_element_by_name
下来是以name的属性来进行定位和具体的操作,还是从上面的源码得到它的name为wd,调用的方法当然都是find_element_by_name()的方法,按照name的属性
在搜索输入框输入搜索关键字的测试案例实战代码:
#! /usr/bin/env python
# -*- coding:utf-8 -*-
#author:无涯
from selenium import webdriver
import time as t
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
driver.find_element_by_name('wd').send_keys('无涯 接口测试')
t.sleep(3)
driver.quit()3.2.1.3、find_element_by_class_name
下面以class的属性,它使用到的方法为find_element_by_class_name的方式来进行,在属性里面也就是class,还是从上面的HTML的源码里面可以知道,它的class
为s_ipt,下面实现以class的方式来进行,测试实战代码为:
#! /usr/bin/env python
# -*- coding:utf-8 -*-
#author:无涯
from selenium import webdriver
import time as t
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
driver.find_element_by_class_name('s_ipt').send_keys('无涯 接口测试')
t.sleep(3)
driver.quit()3.2.1.4、find_element_by_class_xpath
当一个元素实在在定位不到的时候,也就是id,name,class都不可以的时候,可以使用xpath或者是css的模式,我个人一般推荐可以使用xpath的方式,那么获取
元素属性的xpth怎么获取了,下面为具体说下操作步骤:
1、鼠标到需要操作的元素属性
2、右键,点击Copy,如下图所示:
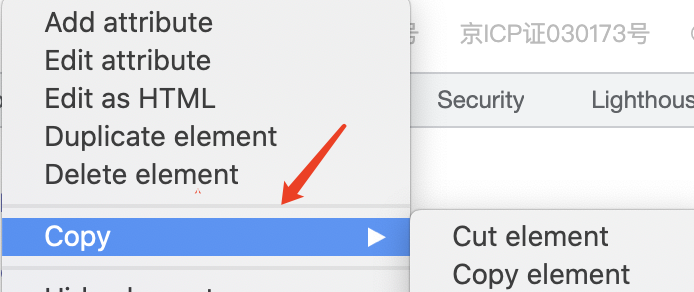
3、点击Copy后,选择Copy Xpath,如下图所示:
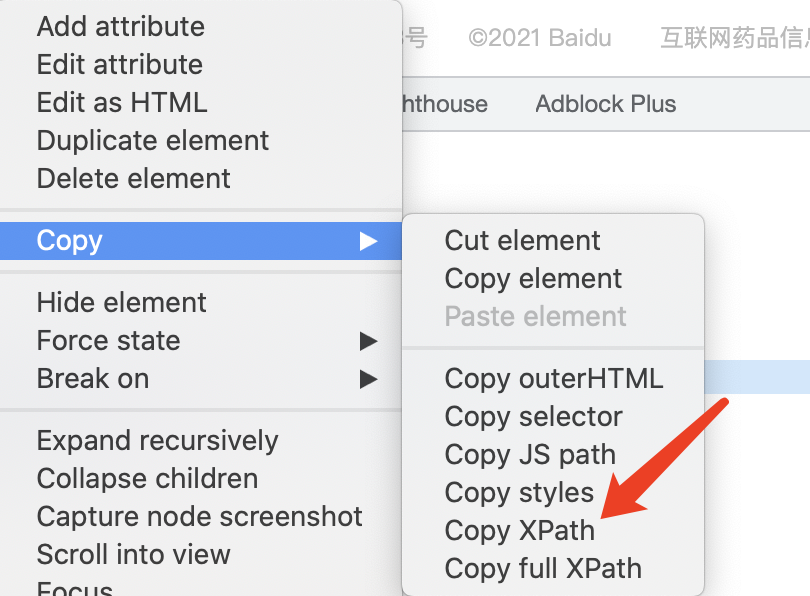
当然如果是动态的ID,获取到的xpath也是错误的,那么这个时候怎么解决问题了?解决的思路就是点击Copy full Xpath,这样获取到的xpath是完整的,就不会
因为动态的ID而导致错误。下面还是以百度搜索输入框,获取到它的xpath为://*[@id="kw"],下面具体显示实战的测试案例代码:
#! /usr/bin/env python
# -*- coding:utf-8 -*-
#author:无涯
from selenium import webdriver
import time as t
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
driver.find_element_by_xpath('//*[@id="kw"]').send_keys('无涯 接口测试')
t.sleep(3)
driver.quit()3.2.1.5、find_element_by_css_selector
使用css的定位操作方式与xpath的操作步骤都是一样的,只不过有点区别的是在点击Copy后,需要点击的是Copy selector,具体如下图所示:
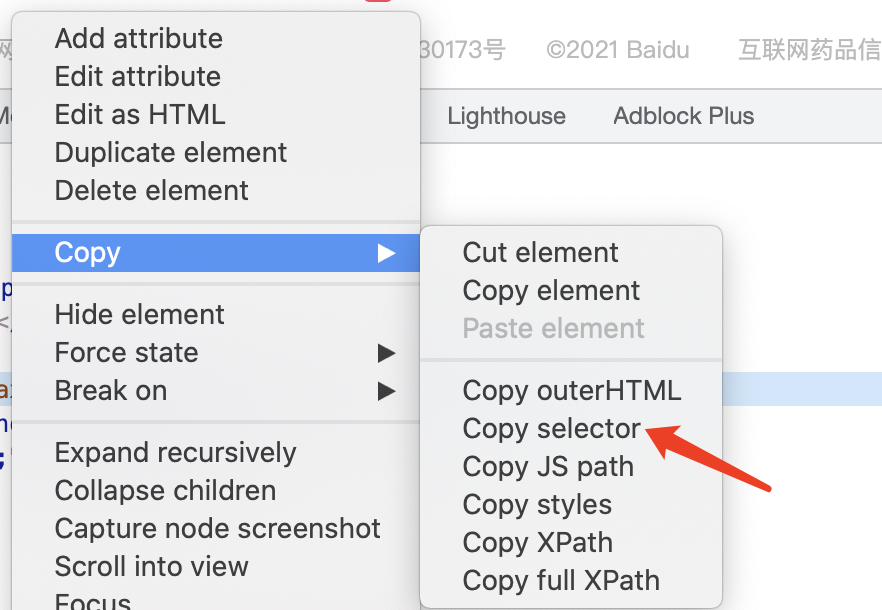
调用的方法为find_element_by_css_selector, 百度搜索输入框获取到它的css为#kw,那么就以css的方式来演示这部分的测试实战代码,代码如下:
#! /usr/bin/env python
# -*- coding:utf-8 -*-
#author:无涯
from selenium import webdriver
import time as t
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
driver.find_element_by_css_selector('#kw').send_keys('无涯 接口测试')
t.sleep(3)
driver.quit()3.2.1.6、find_element_by_link_text
在页面的交互种如果存在超链接,可以使用的方法为find_element_by_link_text,比如在百度首先我们需要点击新闻,那么就可以使用方法来进行定位了
一般而言在a标签里面的,我们都可以理解为超链接,就可以使用该方法来进行具体的操作了,针对点击新闻的超链接测试代码为:
#! /usr/bin/env python
# -*- coding:utf-8 -*-
#author:无涯
from selenium import webdriver
import time as t
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
driver.find_element_by_link_text('新闻').click()
t.sleep(3)
driver.quit()3.2.1.7、find_element_by_partial_link_text
针对超链接定位还有另外一方法它就是find_element_by_partial_link_text,那么把它可以理解为也是针对超链接的定位方式,不过它可以使用模糊匹配
的原则,这个怎么理解了,比如点击新闻,我们只可以使用一个关键字“闻”,下面还是点击新闻的超链接,但是使用模糊的方式,测试代码如下:
#! /usr/bin/env python
# -*- coding:utf-8 -*-
#author:无涯
from selenium import webdriver
import time as t
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
driver.find_element_by_partial_link_text('闻').click()
t.sleep(3)
driver.quit()3.2.1.8、find_element_by_tag_name
tag_name可以理解为是标签,怎么理解了,就是就是百度搜索输入框,它的标签是input,那么针对这种我们可以使用标签的方式来进行,使用到的方法
是find_element_by_tag_name,测试实战代码如下:
#! /usr/bin/env python
# -*- coding:utf-8 -*-
#author:无涯
from selenium import webdriver
import time as t
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
driver.find_element_by_tag_name('input').send_keys('无涯 接口测试')
t.sleep(3)
driver.quit()执行如上的代码,很遗憾出现错误了,具体错误信息为:
Traceback (most recent call last):
File "/Applications/code/Yun/零基础测试/login.py", line 10, in <module>
driver.find_element_by_tag_name('input').send_keys('无涯 接口测试')
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/selenium/webdriver/remote/webelement.py", line 522, in send_keys
'value': keys_to_typing(value)})
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/selenium/webdriver/remote/webelement.py", line 664, in _execute
return self._parent.execute(command, params)
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/selenium/webdriver/remote/webdriver.py", line 344, in execute
self.error_handler.check_response(response)
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/selenium/webdriver/remote/errorhandler.py", line 236, in check_response
raise exception_class(message, screen, stacktrace)
selenium.common.exceptions.ElementNotInteractableException: Message: element not interactable出现问题不要急着问别人,其实仔细看看错误信息,我们是能够独立的解决问题的,出现这个问题说明元素定位找不到,导致错误,那么有可能是定位到的元
素属性是错误,还有一种是我们需要索引的方式来解决。如果是后者,是单个元素定位的方式无法解决的,就是多个元素可以解决的了。
3.2.2 多个元素
针对单个元素定位无法解决的问题,主要核心点获取到的元素属性都一样,比如就以百度搜索输入框为案例,我们使用的是input标签的方式进行,但是
input标签有8个,那么就不是唯一的了,具体如下所示:
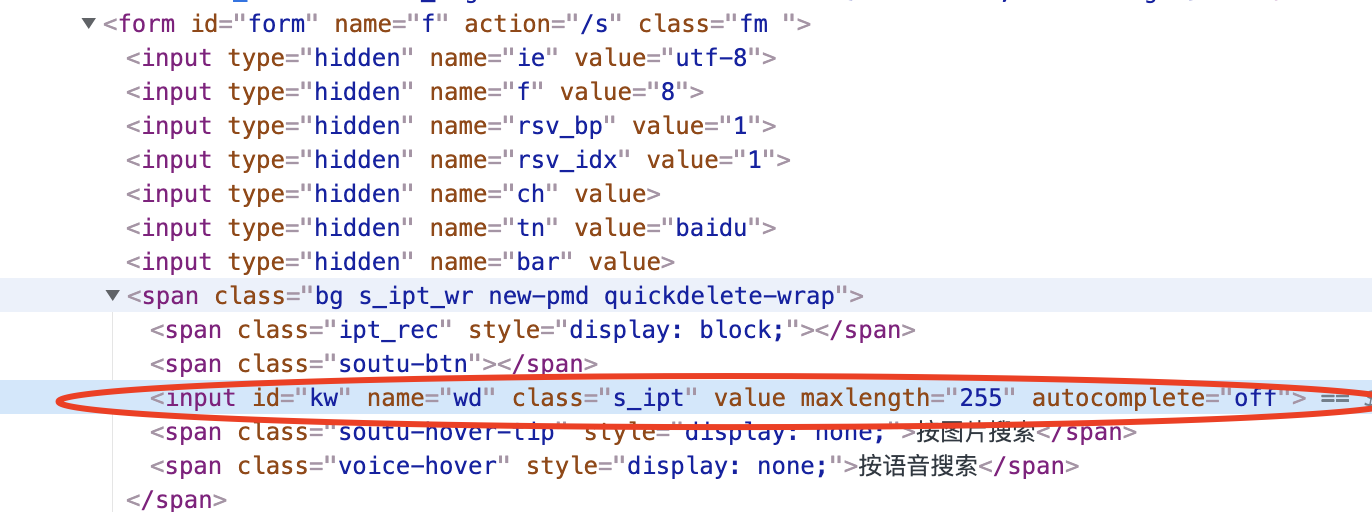
针对这种不是唯一的,我们可以使用多个元素定位的方式来解决,其实多个元素定位的核心思想是获取到的元素属性是一个列表,我们可以使用列表的索引来进
行定位,比如针对标签的方法就是find_elements_by_tag_name(),当然其他的方法其实都是一样的,这里我们先获取到它的属性,然后输出,就可以看到它的数
据是列表,具体案例代码如下:
#! /usr/bin/env python
# -*- coding:utf-8 -*-
#author:无涯
from selenium import webdriver
import time as t
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
so=driver.find_elements_by_tag_name('input')
print(type(so))
t.sleep(3)
driver.quit()我们定位的百度搜索输入框的input是在第八位,那么它的索引就是7,那么针对这部分的操作可以调整下代码,修改后的代码为:
#! /usr/bin/env python
# -*- coding:utf-8 -*-
#author:无涯
from selenium import webdriver
import time as t
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
so=driver.find_elements_by_tag_name('input')
so[7].send_keys('无涯 接口测试')
t.sleep(3)
driver.quit()三、函数式思维
3.1、方法封装
Python是函数式的编程语言也是面向对象的编程,那么什么是函数,其实函数来自数学的思想,模块化的组织思维和把复杂问题简单化的结构化
的思维方式,通俗的理解就是把一组语句的集合通过一个函数名封装起来,要想执行这个函数,只需要调用这个函数名就可以了。函数的优势可以总结为:
-
-
程序变得可扩展
-
根据函数式的思想,我们可以针对元素定位的方法进行封装,这样调用起来会更加简单,其实只所以要封装的思考点是特别的简单,一是利用函数的结构化
的思想,而是让调用的方法更加简洁,如下是常有方法的封装,具体如下:
#! /usr/bin/env python
# -*- coding:utf-8 -*-
#author:无涯
from selenium import webdriver
import time as t
def findID(driver,ID):
return driver.find_element_by_id(ID)
def findName(driver,name):
return driver.find_element_by_name(name)
def findCalssName(driver,className):
return driver.find_element_by_class_name(className)
def findXpath(driver,xpath):
return driver.find_element_by_xpath(xpath)
def findCssSelector(driver,cssSelector):
return driver.find_element_by_css_selector(cssSelector)
def findTagsName(driver,tagName,index):
return driver.find_elements_by_tag_name(tagName)[index]上面我只是封装了部分的方法,其他的方法您可以根据自己的需求进行继续封装,下面我们还是依据之前的代码来调用封装后的代码是否正确,就以
多个元素定位的方式来进行,调整后的代码如下:
#! /usr/bin/env python
# -*- coding:utf-8 -*-
#author:无涯
from selenium import webdriver
import time as t
def findID(driver,ID):
return driver.find_element_by_id(ID)
def findName(driver,name):
return driver.find_element_by_name(name)
def findCalssName(driver,className):
return driver.find_element_by_class_name(className)
def findXpath(driver,xpath):
return driver.find_element_by_xpath(xpath)
def findCssSelector(driver,cssSelector):
return driver.find_element_by_css_selector(cssSelector)
def findTagsName(driver,tagName,index):
return driver.find_elements_by_tag_name(tagName)[index]
if __name__ == '__main__':
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
findTagsName(driver=driver,tagName='input',index=7).send_keys('无涯 接口测试')
t.sleep(3)
driver.quit()执行无任何的问题,但是有警告,具体警告信息为:
/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/selenium/webdriver/remote/webdriver.py:606: UserWarning: find_elements_by_* commands are deprecated. Please use find_elements() instead
warnings.warn("find_elements_by_* commands are deprecated. Please use find_elements() instead")3.2、顶层思维
在3.1的收尾中,有警告的信息,我们可以具体到webdriver.py模块的606行看看警告信息,这部分的源码为:
def find_elements_by_tag_name(self, name):
"""
Finds elements by tag name.
:Args:
- name - name of html tag (eg: h1, a, span)
:Returns:
- list of WebElement - a list with elements if any was found. An
empty list if not
:Usage:
::
elements = driver.find_elements_by_tag_name('h1')
"""
warnings.warn("find_elements_by_* commands are deprecated. Please use find_elements() instead")
return self.find_elements(by=By.TAG_NAME, value=name)很明显,按照官方的意思,后面这种方式逐步的会被替代以及放弃,警告不是错误,但是让人不舒服,那么解决的思路是什么了?还是看官方的警告
代码来分析,根据警告官方更加推荐我们使用(by=By.TAG_NAME, value=name)这种方式来解决,这也是在我开头部分说的,不管元素有多少个方
法,我们只可以分为两个,主要就是单个元素定位和多个元素定位的方法,那么针对上面的封装进行改造,改造成(by=By.TAG_NAME, value=name)
的模式,调整后的代码为:
#! /usr/bin/env python
# -*- coding:utf-8 -*-
#author:无涯
from selenium import webdriver
from selenium.webdriver.common.by import By
import time as t
def findID(driver,ID):
return driver.find_element(By.ID,ID)
def findName(driver,name):
return driver.find_element(By.NAME,name)
def findCalssName(driver,className):
return driver.find_element(By.CLASS_NAME,className)
def findXpath(driver,xpath):
return driver.find_element(By.XPATH,xpath)
def findCssSelector(driver,cssSelector):
return driver.find_element(By.CSS_SELECTOR,cssSelector)
def findTagsName(driver,tagName,index):
return driver.find_elements(By.TAG_NAME,tagName)[index]
if __name__ == '__main__':
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
findTagsName(driver=driver,tagName='input',index=7).send_keys('无涯 接口测试')
t.sleep(3)
driver.quit()再次执行没有任何的错误信息,但是还是感觉封装的方法有点多,没有达到封装的最原始的诉求的,最原始的诉求我更想的是按照分类的思考
点来进行,也就是元素定位只有两个方法,那么如下是封装后的代码,具体如下:
#! /usr/bin/env python
# -*- coding:utf-8 -*-
#author:无涯
from selenium import webdriver
from selenium.webdriver.common.by import By
import time as t
def findElement(driver,*args):
return driver.find_element(*args)
def findElements(driver,*args):
return driver.find_elements(*args)
if __name__ == '__main__':
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
findElements(
driver,
*(By.TAG_NAME,'input'))[7].send_keys('无涯 接口测试')
# findElement(driver,*(By.ID,'kw')).send_keys('无涯 接口测试')
t.sleep(3)
driver.quit()通过如上的代码,可以看到是非常简单,达到了诉求。感谢您的阅读,第十一期《服务端测试开发训练营》开始招生啦,欢迎
扫描二维码咨询。
