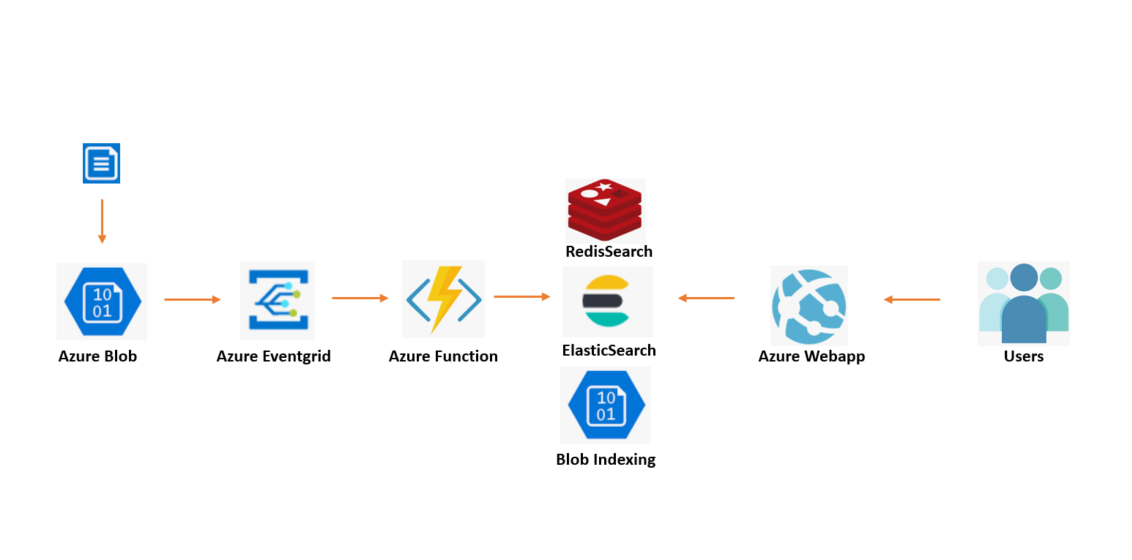
前面我们为大家介绍了 Azure Blob 文件索引检索查询 的几个典型场景,本文为大家来介绍一下 RedisSearch 的方案实现。我们来回顾一下架构图,该方案中选择 RedisSearch 作为索引数据查询引擎作为示例,用户也可以采用相同的架构使用 ElasticSearch 进行搭建。顺便口播一则广告,RedisSearch 功能已经在海外的 Azure Redis Cache Enterprise 版本中支持,该版本为 RedisLabs 发布的 Redis 商业版本,其中包含了很多 Redis 的商业版功能,其中 RedisSearch 插件支持是其中之一。RedisSearch 全面支持检索查询功能,包含模糊搜索,全文检索,丰富的索引数据类型支持,以及灵活的查询检索语法。
目前 Redis Cache Enterprise Tier 已经在海外 Azure Preview 预览,用户可以参考链接进行创建, 此处不做赘述。下面我们主要聚焦 RedisSeach 索引数据的创建和管理逻辑
数据准备: 示例中通过本地的书籍信息样本数据为大家进行介绍,原数据是一个 CSV 文件,文件中包含如下书籍信息

运行环境准备:示例中采用 python 作为示例代码,客户需要环境中安装 redisearch-py 依赖包,并从 Azure Portal 中读取 Redis Cache Enterprise 实例的链接字符串
from redisearch import Client, TextField, NumericField, Query, result import time import datetime import csv redishost = 'input_your_redis_fqdn_here' redisport = 10000 redispassword = 'input_your_redis_accesskey_here'
# Creating a client with a given index name client = Client("searchdemo", host=redishost, port=redisport, password=redispassword) # Creating the index definition and schema client.create_index([TextField('author'), TextField('title'), TextField('publisher'), NumericField('publicationdate', sortable=True)], stopwords=[])
数据索引:通过读取 CSV file 中的数据信息,仿真创建 Blob 并将作者,书名,发行商和发行时间作为索引数据。
with open('demobookdataset.csv', mode='r') as csv_file: csv_reader = csv.DictReader(csv_file) line_count = 0 for row in csv_reader: if line_count == 0: print(f'Column names are {", ".join(row)}') line_count += 1 continue if int(row["publication_date"].split('/')[2]) >= 1970: publishdate = time.mktime(datetime.datetime.strptime(row["publication_date"], "%m/%d/%Y").timetuple()) else: epoch = datetime.datetime(1970, 1, 1) t = datetime.datetime.strptime(row["publication_date"], "%m/%d/%Y") diff = t-epoch publishdate = diff.days * 24 * 3600 + diff.seconds # Indexing a document client.add_document(str(line_count), author = row["authors"], title = row["title"], publisher = row["publisher"], publicationdate = publishdate) line_count += 1
数据检索查询:示例中通过以索引中 author 作为查询值进行检索查询验证,需要注意在 Filter 的查询语句编写语法上需要按照规范进行编写,可以参考查询语法进行定义。
filter = "create_your_filter_here" result = client.search(filter) for item in result.docs: print(item)
RedisSearch 支持丰富的检索查询语法,用户可以灵活的定义查询逻辑,大家可以参考上述的查询语法进行深入的学习来定义自己的场景,这里不做赘述。上述示例通过 Python 代码实现,大家可以按照自己喜好的开发语言进行开发,整个方案关于 EventGrid, Function 的集成这里不再赘述,感兴趣的小伙伴,可以参考我之前的博客Azure NSG Flow Log 引发的自嗨。