最近无意间翻看手册,发现 Global Azure 发布了 NSG Flow Log v2,在原有 Log 的基础上增加了 Flow State,Flow Bytes Statistics,Flow Packet Statistics,这些 Telemetry 字段对于从网络层面做运维和运营非常有帮助,比如想做流量分析,分析安全事件等,无限的遐想。
# NSG FLOW LOG v2 Sample Log Data
{
"records": [
{
"time": "2018-11-13T12:00:35.3899262Z",
"systemId": "a0fca5ce-022c-47b1-9735-89943b42f2fa",
"category": "NetworkSecurityGroupFlowEvent",
"resourceId": "/SUBSCRIPTIONS/00000000-0000-0000-0000-000000000000/RESOURCEGROUPS/FABRIKAMRG/PROVIDERS/MICROSOFT.NETWORK/NETWORKSECURITYGROUPS/FABRIAKMVM1-NSG",
"operationName": "NetworkSecurityGroupFlowEvents",
"properties": {
"Version": 2,
"flows": [
{
"rule": "DefaultRule_DenyAllInBound",
"flows": [
{
"mac": "000D3AF87856",
"flowTuples": [
"1542110402,94.102.49.190,10.5.16.4,28746,443,U,I,D,B,,,,",
"1542110424,176.119.4.10,10.5.16.4,56509,59336,T,I,D,B,,,,",
"1542110432,167.99.86.8,10.5.16.4,48495,8088,T,I,D,B,,,,"
]
}
]
},
{
"rule": "DefaultRule_AllowInternetOutBound",
"flows": [
{
"mac": "000D3AF87856",
"flowTuples": [
"1542110377,10.5.16.4,13.67.143.118,59831,443,T,O,A,B,,,,",
"1542110379,10.5.16.4,13.67.143.117,59932,443,T,O,A,E,1,66,1,66",
"1542110379,10.5.16.4,13.67.143.115,44931,443,T,O,A,C,30,16978,24,14008",
"1542110406,10.5.16.4,40.71.12.225,59929,443,T,O,A,E,15,8489,12,7054"
]
}
]
}
]
}
}
]
}
正琢磨着这 Log 该怎么消费,Traffic Analytics 映入眼帘,Azure 真是既当孩子爹又当孩子妈,都已经做好了开箱即用的产品(https://docs.microsoft.com/en-us/azure/network-watcher/traffic-analytics),Traffic Analytics 在 Raw NSG Flow Log 的基础上做了数据属性的扩展,如 IP Geo 信息,IP 服务归属等,但与此同时是以时间开销作为代价,TA 服务对 Raw Log 进行扩展和聚合,聚合和扩展会对日志的实时性带来 1 小时的延迟。另外 TA 服务的分析引擎是基于 Azure Log Analytics 服务做的,客户的定制性也受限要依赖在本身这个服务的能力之上。自嗨不禁开始了,低延迟实时性,属性聚合扩展自主可控,分析引擎开放灵活。
对于 Telemetry 数据来讲通常 Ingest 部分通过流式的方式可以实现低延迟实时性,NSG Flow Log 目前只支持到持久化到 Blob 存储,还不支持原生的 Event Hub 集成,所以第一步流式转换需要自己来做掉。好消息是 NSG Flow Log 采用的是 Block Blob 方式持久化,每一小时生成一个 Blob 日志文件,一小时内会以1分钟为间隔向该 Blob 文件中 Commit Block,所以理论上我们可以把实时性做到1分钟这个数量级。流化的产品选择在 Telemetry 场景下,Event Driven 的方式要好过 Time Schedule 的方式,Event Driven 可以更好的保证处理的实时性,在 Azure 中 Event Grid 可以监测 Blob Storage 的事件,从而触发下游处理流程。处理流程部分我们希望对 Raw Log 的聚合和扩展自主可控,并且可以适配 Event Driven 架构,Azure Function 自然是不二之选,支持事件驱动,多语言支持,并且可以通过 Consumption Model 进行计费。分析引擎方面遵从开放灵活可自定义原则,Log Analytics 服务的引擎其实就是 Azure Data Explorer 服务,通过调用原生引擎可以获得最大的可定制性。将 Log 数据注入分析引擎的时,目前 Azure Data Explore 支持从 Blob 导入数据,也支持从流式消息中心导入,对于 Telemetry 数据实时性的要求,流式消息中心是更适合的选择,这里选择了开箱即用的 Event Hub。展现层可以选择 MS 第一方的 PBI,或者选择开源的 Grafana,Kibana,Data Explorer 都可以适配。下面是整体架构的参考图:
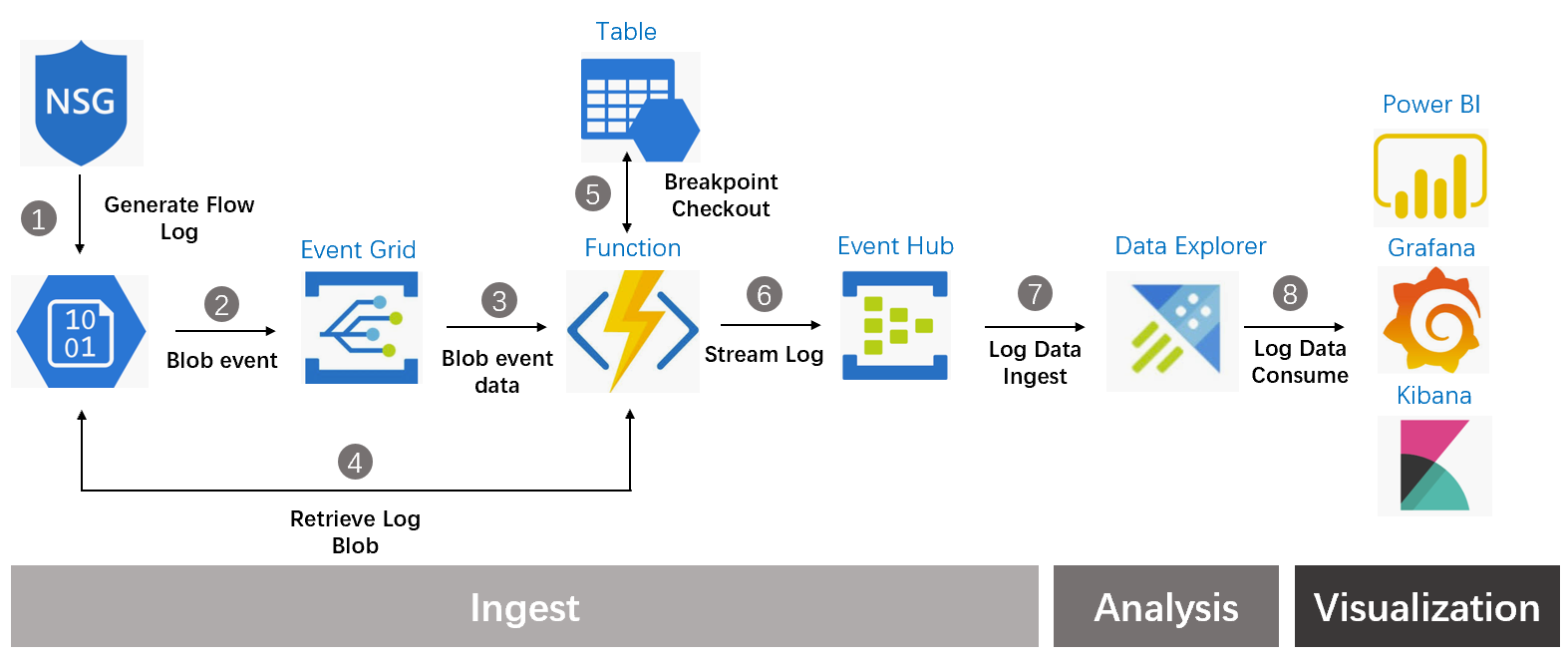
后面几篇文章我会结合上面的架构,分别介绍 1. Event Grid 实现 Blob 事件驱动日志处理,2. Function 日志 ETL 流式处理,3. Data Explorer 数据分析。敬请期待!