1、首先需要构建自然语言处理的LTP的框架
(1)需要下载LTP的源码包即c++程序(https://github.com/HIT-SCIR/ltp)下载完解压缩之后的文件为ltp-master
(2)需要下载LTP4j的封装包(https://github.com/HIT-SCIR/ltp4j),下载完解压缩之后的文件为ltp4j-master
(3)需要下载cmake并且安装
(4)需要下载ant用来编译LTP4j,将LTP4j文件编译成ltp.jar文件,最后在myeclipse中引用它
2、首先编译ltp4j-master
直接进入ltp4j-master的文件夹中,运行ant命令,然后就会生成一个
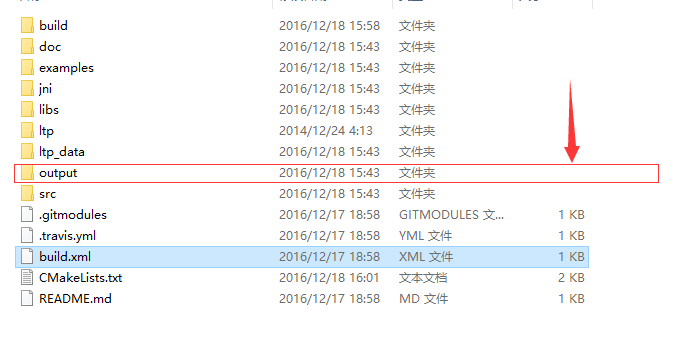
output的文件夹,里边是

jar包就在jar文件夹下。
3、编译ltp-master的c++文件源码
这个不会编译实在太复杂了,所以直接上网找了个编译好的,下了下来。大家可以上以下这个地址中去找去,下载64位已经编译好的动态链接库
http://download.csdn.net/index.php/mobile/source/download/sv2008337/9471357
4、构建java项目,然后进行分词测试
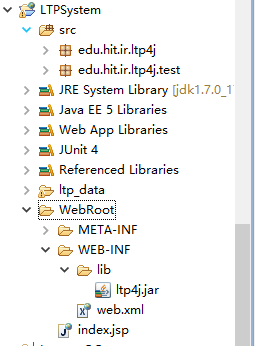
构建的java项目如上图所示,ltp4j.jar文件就是第2步中编译出来的jar包。
edu.hit.ir.ltp4j是从ltp4j-master文件夹中直接拷过来的。
ltp_data文件是分词的词库,据我们经理说现在都是用字典分词来着,所以肯定要有词库的,这个词库在这里是从下边这里拷进来的。
好吧是我从网上下的,这里骗了大家了。
下面来说卡了我时间最长的一步,就是通过jni来调用dlll动态链接库,因为这需要引入动态链接库的library
就是下边这样,在这里配置你的dlll文件库在哪里,在我的电脑中是在,下下张图上边
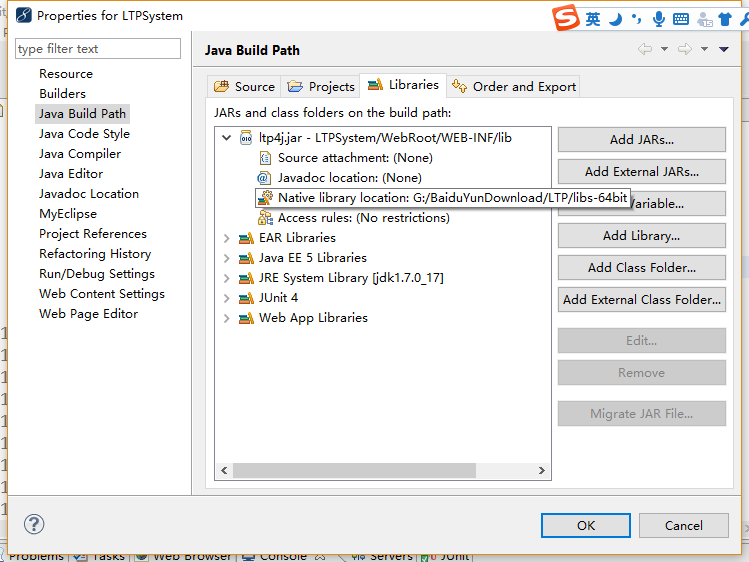
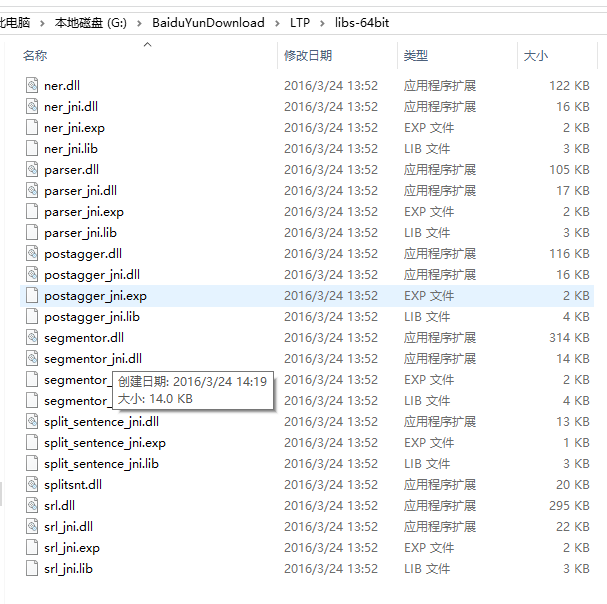
上面这张图也就是我从第3步中从网上下下来的dlll库,直接在java文件中配置就可以了
5、分词测试
经过了上面的准备工作我们就真的可以开始进行分词测试了
(1)分词功能测试
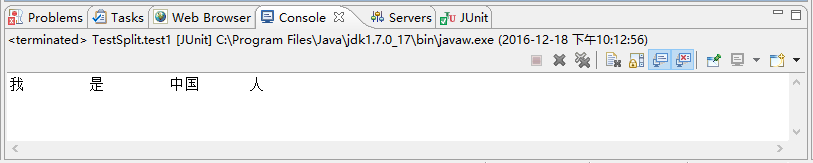
/** * 1,分词功能测试 */ @Test public void test1(){ if(Segmentor.create("ltp_data/cws.model")<0){ System.err.println("load failed"); return; } String sent = "我是中国人"; List<String> words = new ArrayList<String>(); int size = Segmentor.segment(sent,words); for(int i = 0; i<size; i++) { System.out.print(words.get(i)); if(i==size-1) { System.out.println(); } else{ System.out.print(" "); } } Segmentor.release(); }
结果如下所示:
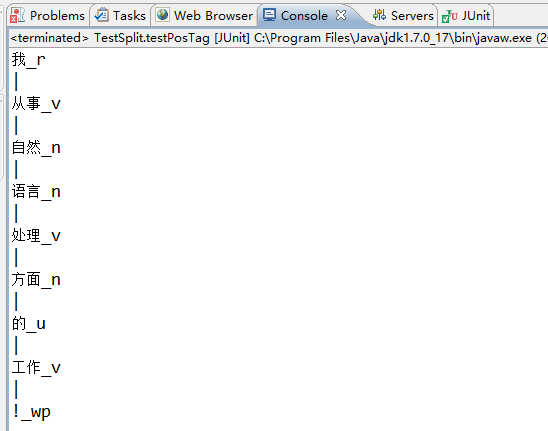
(2)词性标注功能测试
/** * 词性标注功能测试 */ @Test public void testPosTag(){ if(Postagger.create("ltp_data//pos.model")<0){ System.err.println("加载失败!"); return; } List<String> words = new ArrayList<String>(); words.add("我"); words.add("从事"); words.add("自然"); words.add("语言"); words.add("处理"); words.add("方面"); words.add("的"); words.add("工作"); words.add("!"); List<String> postags = new ArrayList<String>(); int size = Postagger.postag(words, postags); for (int i = 0; i < size; i++) { System.out.println(words.get(i)+"_"+postags.get(i)); if(i==size-1){ System.out.println(); }else{ System.out.println("|"); } } Postagger.release(); }
结果如下所示: