文章目录
1 线程池七大参数
2 RejectedExecutionHandler--- 四种拒绝策略(官方提供)
3 threadFactory --- 线程工厂相关的注意事项
4 如何自己new一个线程池 --- 简单结合了一下我们的项目
5 实际工作中不允许使用Executors创建线程池的原因
6 如何合理配置最大线程数
1 线程池七大参数
其实线程池的七大参数,我算一直都是比较熟悉的,因为我们现在的好几个项目里,有好几处线程池都是我配置的,而且大多都至少在线上经历了1年多的洗礼了。。。 其实很早之前我就想整理一下这一块的内容的,但是却一直没有付诸于行动!!!
恰巧,最近发现了哔哩哔哩这片知识的蓝海,又有幸看到了尚硅谷周阳老师的公开课,感觉讲的挺好的,本篇文章大多是在此基础上的总结。
线程池七大参数总结如下:
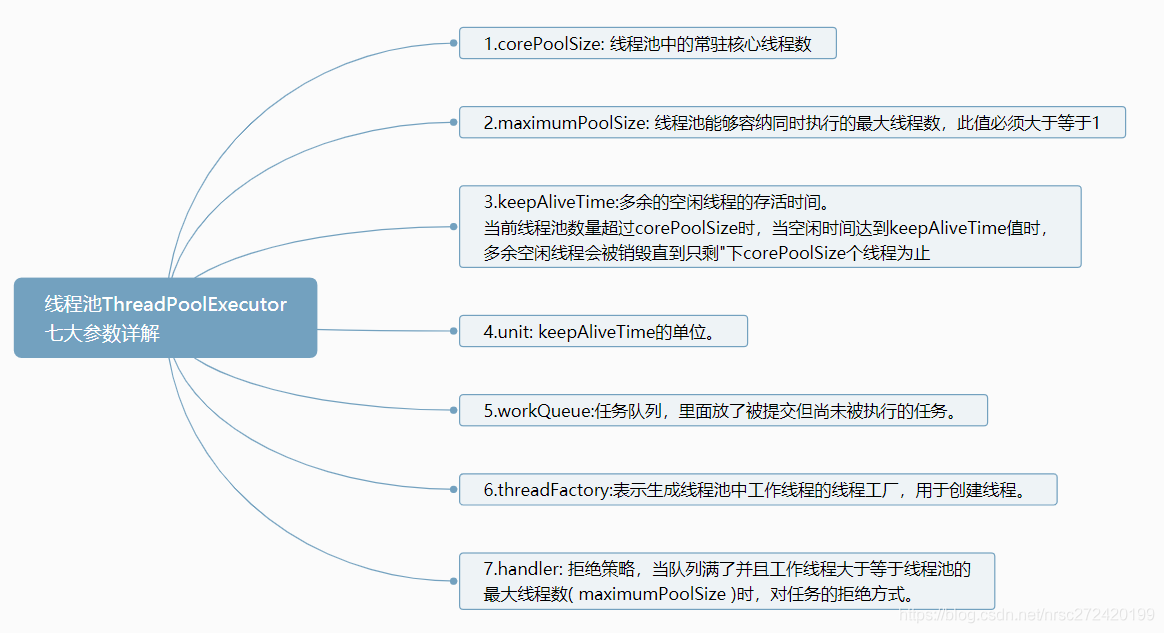
进一步解释如下:
1.在创建了线程池后,等待提交过来的任务请求。
2.当调用execute()方法添加一个请求任务时,线程池会做如下判断:
2.1 如果正在运行的线程数量小于corePoolSize,那么马上创建线程运行这个任务;
2.2 如果正在运行的线程数量大于或等于corePoolSize,那么将这个任务放入队列;
2.3 如果这时候队列满了且正在运行的线程数量还小于maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务;
2.4 如果队列满了且正在运行的线程数量大于或等于maximumPpolSize,那么线程池会启动饱和拒绝策略来执行。
3.当一个线程完成任务时,它会从队列中取下一个任务来执行。
4.当一个线程无事可做超过一定的时间(keepAliveTime) 时,线程池会判断:
如果当前运行的线程数大于corePoolSize,那么这个线程就被停掉。
所以线程池的所有任务完成后它最终会收缩到corePoolSize的大小。
线程池工作的主要流程图如下:
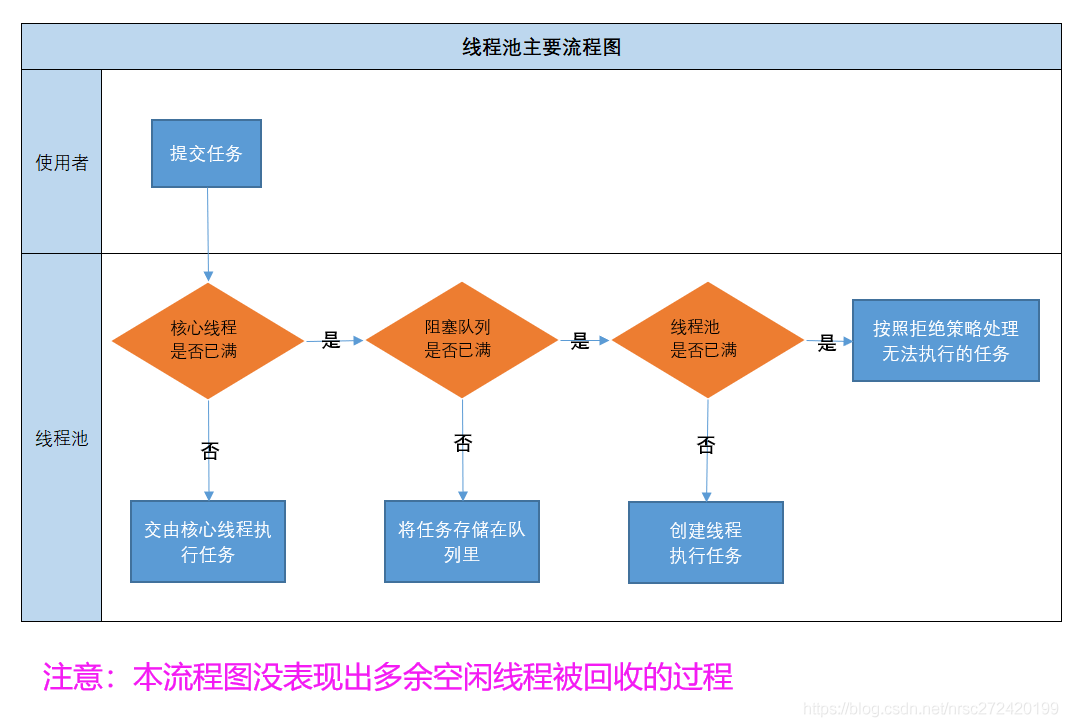
最大可同时存在于线程池中的任务: 最大线程数 + 阻塞队列的长度。 —》这应该很好理解吧。。。
2 RejectedExecutionHandler— 四种拒绝策略(官方提供)
当阻塞队列满了,且没有空闲的工作线程,如果继续提交任务,必须采取一种策略处理该任务,线程池提供了4种策略:
(1)AbortPolicy:直接抛出异常,默认策略;
(2)CallerRunsPolicy:用调用者所在的线程来执行任务;
(3)DiscardOldestPolicy:丢弃阻塞队列中靠最前的任务,并执行当前任务;
(4)DiscardPolicy:直接丢弃任务;
当然也可以根据应用场景实现RejectedExecutionHandler接口,自定义饱和策略(拒绝策略),如记录日志或持久化存储不能处理的任务 —》 我在工作中其实就用到了自定义拒绝策略。
有兴趣的可以用代码进行测试一下,挺简单的。
3 threadFactory — 线程工厂相关的注意事项
Executors工具类里给提供了一个默认的线程工厂 —> defaultThreadFactory,其对线程的命名规则为: “pool-数字-thread-数字”。
但是实际开发中我们常常都不会使用这个默认的 —> 我在项目中就没用。
因为我们完全可以按照自己的业务给每个新建的线程设置一个具有识别度的线程名,这样的话,如果真出现了问题,那肯定就会比较容易问题排查。
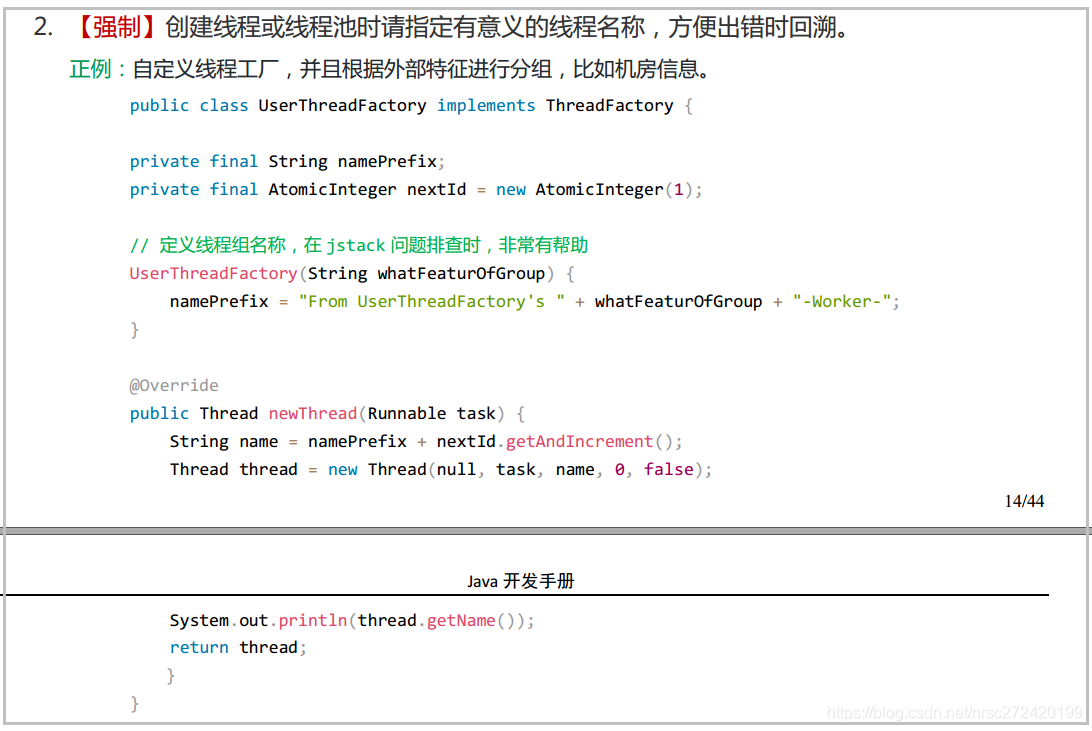
当然还可以更加自由的对线程做更多的设置,比如设置所有的线程为守护线程。我看阿里的《Java开发手册》上甚至都将其作为了【强制】性规约:
4 如何自己new一个线程池 — 简单结合了一下我们的项目
直接上代码了,有兴趣的可以自己测试一下:
package com.nrsc.ch6.tp;
import lombok.extern.slf4j.Slf4j;
import org.junit.Test;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
@Slf4j
public class ThreadPoolDemo {
/***
* 自定义拒绝策略
*/
RejectedExecutionHandler selfRejectedHandler = (r, pool) -> {
//我们的项目,如果将log的级别配置为warn或error级别就会发邮件+微信进行通知
//其实线程池的阻塞队列一般都会配的相对比较大,所以基本不会让任务被拒绝掉 -- 自己的经验
log.warn("方法{}被线程池{}拒绝了,请做及时补偿处理", r.toString(), pool);
};
//定义线程组名称,在jstack问题排查时,非常有帮助
private final String namePrefix = "Contract==";
private final AtomicInteger nextId = new AtomicInteger(1);
/***
* 自定义线程工厂
*/
ThreadFactory threadFactory = (r) -> {
Thread thread = new Thread(r);
thread.setName(namePrefix + nextId.getAndIncrement());
return thread;
};
/***
* 使用自定义的线程工厂 和 拒绝策略
* 实际生产中变量一般写在配置文件里
*/
ThreadPoolExecutor threadPoolExecutor1 = new ThreadPoolExecutor(
3, 5, 3, TimeUnit.SECONDS,
new LinkedBlockingDeque<>(3),
threadFactory,
selfRejectedHandler);
/***
* 使用JDK提供的线程工厂 和 拒绝策略
*/
ThreadPoolExecutor threadPoolExecutor2 = new ThreadPoolExecutor(
3, 5, 3, TimeUnit.SECONDS,
new LinkedBlockingDeque<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
/***
* 自定义的线程工厂 和 拒绝策略 测试
*/
@Test
public void test1() {
for (int i = 1; i <= 10; i++) {
threadPoolExecutor1.execute(() -> {
log.info("当前线程为{}", Thread.currentThread().getName());
});
}
}
/***
* 使用JDK提供的线程工厂 和 拒绝策略
*/
@Test
public void test2() {
for (int i = 1; i <= 10; i++) {
threadPoolExecutor2.execute(() -> {
log.info("当前线程为{}", Thread.currentThread().getName());
});
}
}
}
5 实际工作中不允许使用Executors创建线程池的原因
静态工厂里默认的threadFactory,线程的命名规则是“pool-数字-thread-数字”。
相信很多人在学校里上学时,老师一般都会教你用Executors工具类来创建线程池,当然平常我写博客或者做一些小demo时,也喜欢这么用。
但是只要有过工作经验的,相信肯定都知道,在实际的生产中我们绝对不会这样用。其实原因很简单,如果你懂了阻塞队列的话,再简单搂一眼利用Executors工具类创建线程池的源码,你就会发现具体的原因了。
Executors创建线程池的几个常用方法的源码:
Integer.MAX_VALUE = 2147483647 —> 21亿多。。。。
这里用阿里《JAVA开发手册》中的【强制】性规约来做出工作中不能用Executors创建线程池的具体解释:

6 如何合理配置最大线程数
(1)CPU密集型:
定义:CPU密集型的意思就是该任务需要大量运算,而没有阻塞,CPU一直全速运行。
CPU密集型任务只有在真正的多核CPU上才可能得到加速(通过多线程)。
CPU密集型任务配置尽可能少的线程数。
CPU密集型线程数配置公式:CPU核数+1个线程的线程池
(2)IO密集型:
定义:IO密集型,即该任务需要大量的IO,即大量的阻塞。
在单线程上运行IO密集型任务会导致浪费大量的CPU运算能力浪费在等待。
所以IO密集型任务中使用多线程可以大大的加速程序运行,即使在单核CPU上,这种加速主要利用了被浪费掉的阻塞时间。
第一种配置方式:
由于IO密集型任务线程并不是一直在执行任务,则应配置尽可能多的线程。
配置公式:CPU核数 * 2。
第二种配置方式:
IO密集型时,大部分线程都阻塞,故需要多配置线程数。
配置公式:CPU核数 / 1 – 阻塞系数(0.8~0.9之间)
比如:8核 / (1 – 0.9) = 80个线程数