机器真的会学习吗
该讲初步介绍了机器学习的概念、分类、及其应用场景
机器学习定义
机器学习领域的创始人Arthur Samuel(亚瑟·塞缪尔)早在1959年就给机器学习(Machine Learning,ML)下了定义:机器学习是这样的一个研究领域,它能让计算机不依赖确定的编码指令来自主的学习工作。
机器学习方法分类
有监督学习(supervised learning)
-
数据集中的样本带有标签,有明确目标
-
目标:找到样本到标签的最佳映射
-
应用场景:垃圾邮件分类、病理切片分类、客户流失预警、客户风险评估、房价预测等
-
典型方法
- 回归模型:线性回归、岭回归、LASSO和回归样条等
- 分类模型:逻辑回归、K近邻、决策树、支持向量机等
无监督学习(unsupervised learning)
-
根据数据本身的分布特点,挖掘反映数据的内在特性
-
数据集中的样本没有标签,没有明确目标
-
主要用于聚类、降维、排序、密度估计、关联规则挖掘
-
应用场景(这里主要例举了聚类的应用):
1、基因表达水平聚类:根据不同基因表达的时序特征进行聚类,得到基因表达处于信号通路上游还是下游的信息
2、篮球运动员划分:根据球员相关数据,将其划分到不同类型(或者不同等级)的运动员阵营中
强化学习(reinforcement learning)
- 智慧决策的过程,通过过程模拟和观察来不断学习、提高决策能力,例如:AlphaGo
- 强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为
- 基本概念:
- agent:智能体
- envirment:环境
- state:状态
- action:行动
- reward: 奖励
- 策略:Π(a|s)
- 目标:求解最大化效用的最优策略
- 附上原理图:
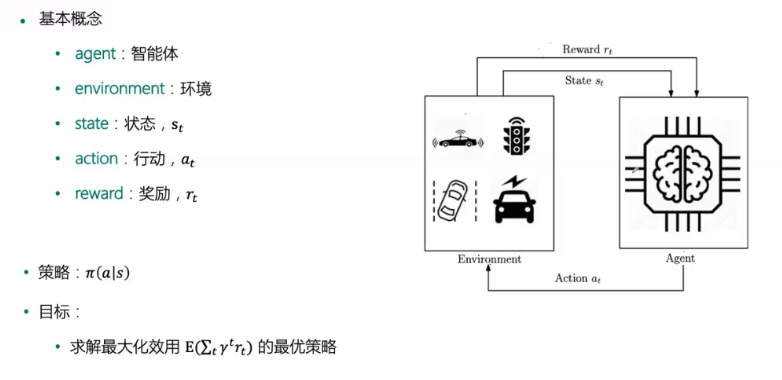
机器学习中的基本概念
- 数据集:一组样本的集合
- 样本:数据集的一行。一个样本包含一个或多个特征,此外还可能包含一个标签
- 特征:在进行预测时使用的输入变量,即数学中我们经常定义的自变量X
- 训练集:用于训练模型的数据集
- 测试集:用于测试模型的数据集
- 模型:建立数据的输入x和输出y之间的映射关系 y = f(x)
- 损失函数:L(yi ,f(xi)) 例如,对回归问题可以定义为(f(xi)-yi)2

机器建模遇到的问题及解决办法
欠拟合
- 欠拟合:模型训练过程中,可能训练样本被提取的特征比较少,导致训练出来的模型不能很好地匹配,表现得很差,甚至样本本身都无法高效的识别。
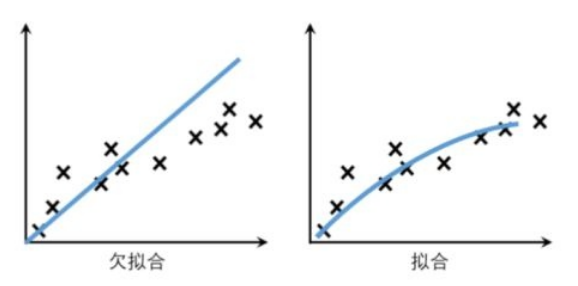
欠拟合解决办法: 欠拟合基本上都会发生在训练刚开始的时候,经过不断训练之后欠拟合应该不怎么考虑了。但是如果真的还是存在的话 先增加 增加网络复杂度或在模型中增加特征
过拟合
- 过度拟合:模型过于复杂(例如参数过多),导致所选模型对已知数据预测得很好,但对未知数据预测很差,即我们常说的数据泛化差
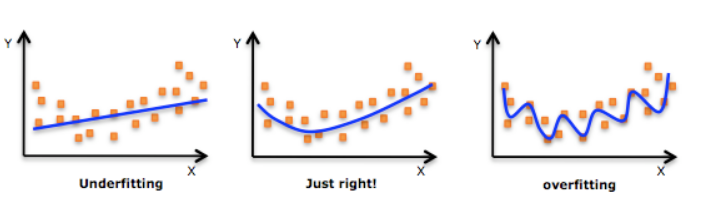
- 导致过拟合原因:
- 训练数据集样本单一,样本不足
- 训练数据中噪声干扰过大
- 模型过于复杂
过拟合解决办法:正则化、交叉验证、K折交叉验证
正则化
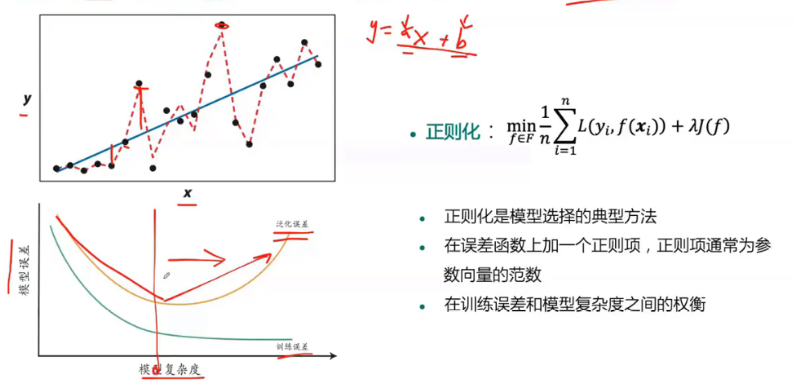
交叉验证
基本想法是重复地使用数据。将数据集划随机切分,将切分的数据集组合为训练集和测试集,在此基础上反复训练,测试和模型选择
K折交叉验证
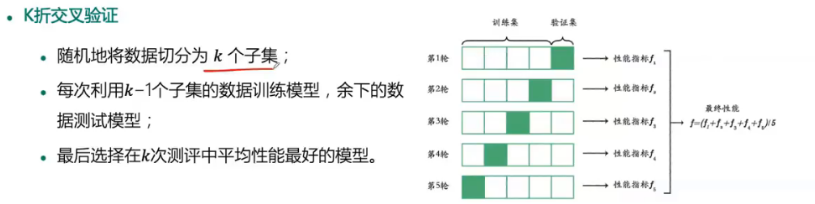
数学结构
数据的数学结构是我们处理数据的前提
度量结构之K近邻
- 随机选定一个样本点,通过计算数据之间的距离进行分类
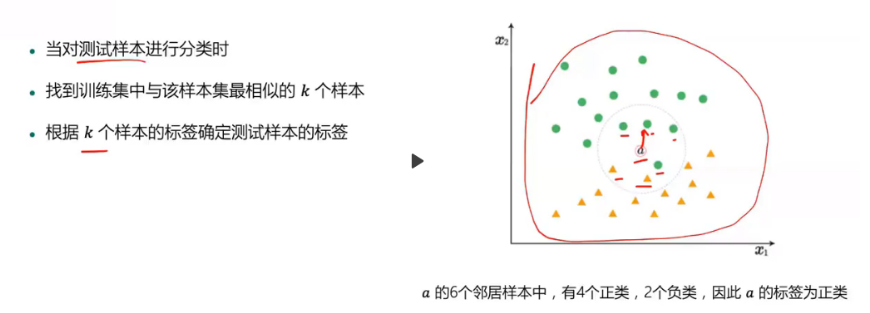
-
k的选择
K的数量不同,分类结果可能也不同
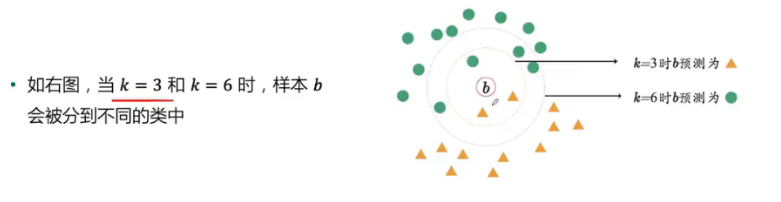
- K近邻:提高计算速度

网络结构
有些数据本身就呈现出网络结构或者适合网络结构,比如社交
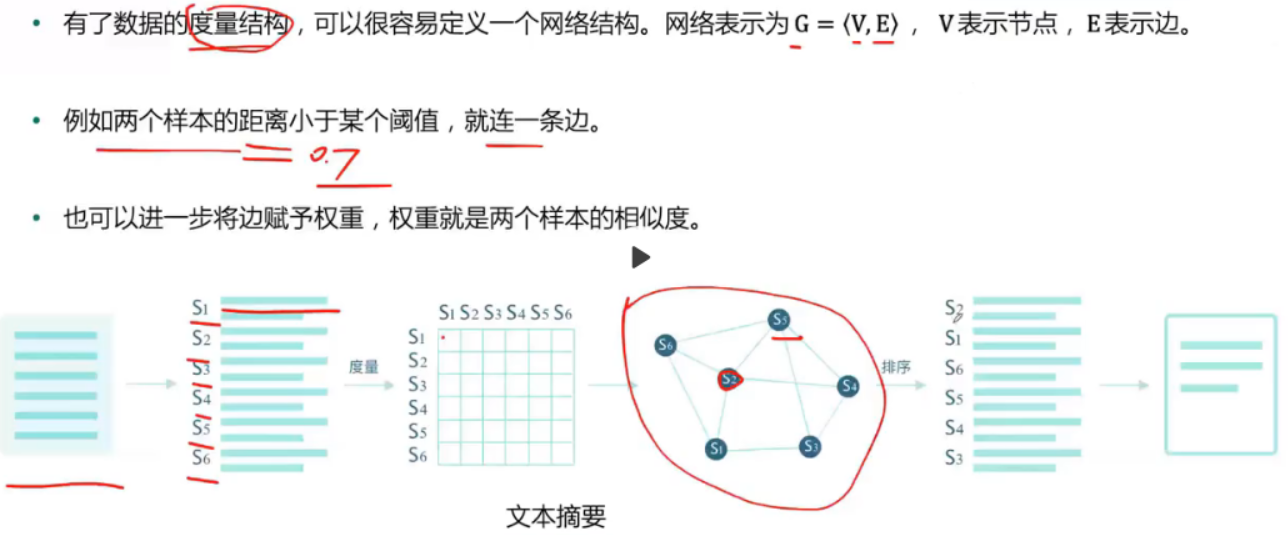
- 网络结构之PageRank算法

其他数学结构

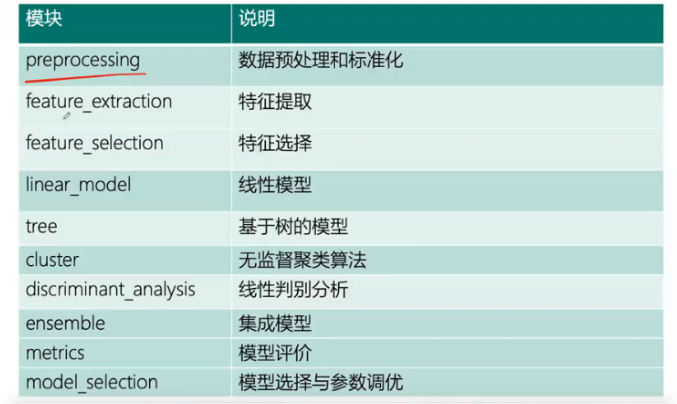
Scikit-learn
- 主要模块