影视分析案例
学完了pandas,趁热打铁练习了下电影分析案例,通过练习,巩固了这几天的知识,不过数据分析时没有业务逻辑,基本停留表面,数据分析的过程中也让我感到有些枯燥。
1. 总览数据
import pandas as pd
import matplotlib.pyplot as plt
# 影视分析案例
# 1.加载数据
data = pd.read_csv('movie_metadata.csv')
print('数据的形状:',data.shape)
data.head()
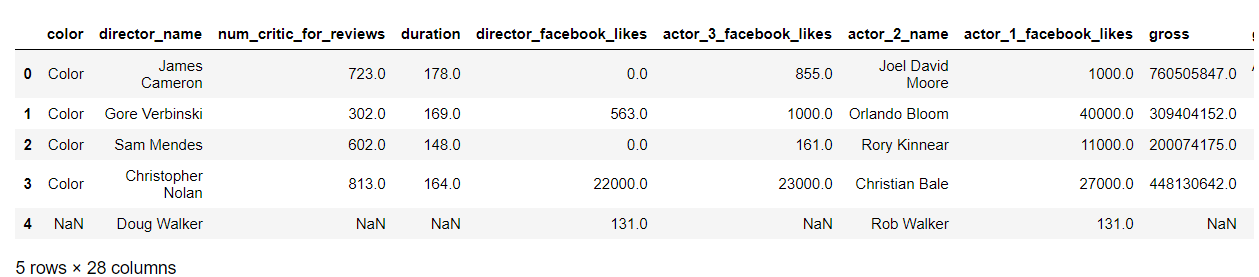
2. 数据处理
# 发现有空值(NaN),处理缺失值
data = data.dropna(how='any')
data.head()
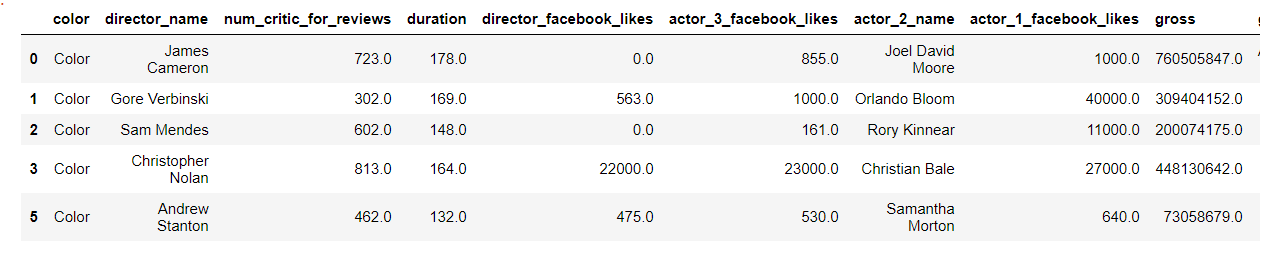
3. 开始分析
3.1 查看票房收入统计
# 任务1、查看票房收入统计
# 1.1 导演 vs 票房总收入
group_director = data.groupby(by='director_name')['gross'].sum()
# 采用降序排列
group_director.sort_values(ascending=False)
数据统计:
director_name
Steven Spielberg 4.114233e+09
Peter Jackson 2.289968e+09
Michael Bay 2.231243e+09
Tim Burton 2.071275e+09
Sam Raimi 2.049549e+09
...
Paul Bunnell 2.436000e+03
Alex Craig Mann 1.332000e+03
Ricki Stern 1.111000e+03
Frank Whaley 7.030000e+02
Ekachai Uekrongtham 1.620000e+02
Name: gross, Length: 1659, dtype: float64
# 主演 vs 票房总收入
group_actor = data.groupby(by='actor_1_name')['gross'].sum()
group_actor.sort_values(ascending=False)
数据统计:
actor_1_name
Johnny Depp 3.714789e+09
Harrison Ford 3.391556e+09
Tom Hanks 3.264559e+09
Tom Cruise 2.987622e+09
J.K. Simmons 2.856407e+09
...
Jim Carter 3.607000e+03
Stephen McHattie 3.478000e+03
Tatyana Ali 2.468000e+03
Kate Maberly 2.436000e+03
Darryl Hunt 1.111000e+03
Name: gross, Length: 1428, dtype: float64
# 导演 + 主演 vs 票房总收入
group_director_actor = data.groupby(by=['director_name','actor_1_name'])['gross'].sum()
group_director_actor.sort_values(ascending=False)
统计结果:
director_name actor_1_name
Joss Whedon Chris Hemsworth 1.705551e+09
Sam Raimi J.K. Simmons 1.485313e+09
Gore Verbinski Johnny Depp 1.250323e+09
George Lucas Natalie Portman 1.165483e+09
Tim Burton Johnny Depp 1.070126e+09
...
Alex Craig Mann Justin Chon 1.332000e+03
Ricki Stern Darryl Hunt 1.111000e+03
Brian Trenchard-Smith David Keith 7.210000e+02
Frank Whaley Lynn Cohen 7.030000e+02
Ekachai Uekrongtham Michael Jai White 1.620000e+02
Name: gross, Length: 3415, dtype: float64
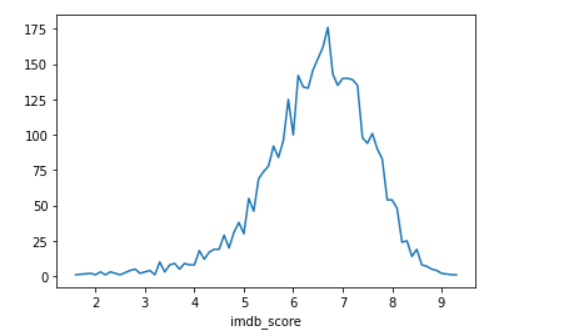
3.2 查看imdb评分统计
# 任务2、查看imdb评分统计
# 2.1 查看 各 imdb 评分的电影个数
imdb = data.groupby('imdb_score')['movie_title'].count()
plt.figure()
imdb.plot()
# plt.savefig('./imdb_scores.png')
plt.show()
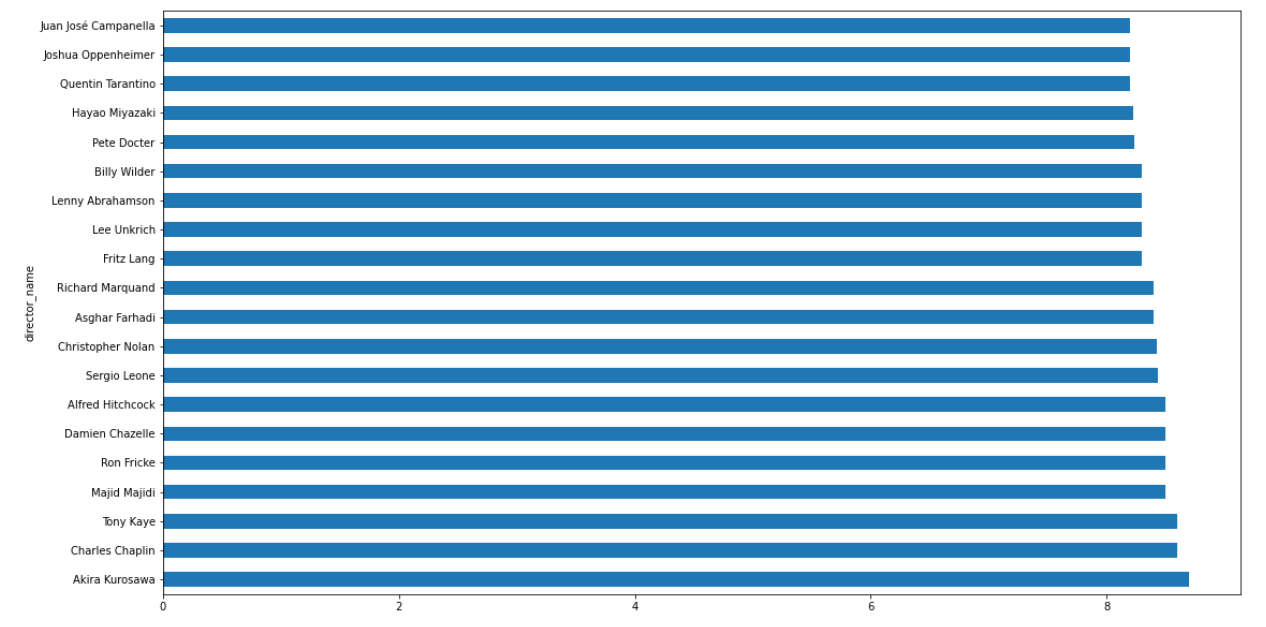
# 2.2 查看mdb评分平均最高的前20导演
director_mean = data.groupby('director_name')['imdb_score'].mean()
top20_imdb_directors = director_mean.sort_values(ascending=False)[:20]
plt.figure(figsize=(18.0,10.0))
# kind = 'barh' 水平条形图
top20_imdb_directors.plot(kind='barh')
# plt.savefig('./top20_imdb_directors.png')
plt.show()
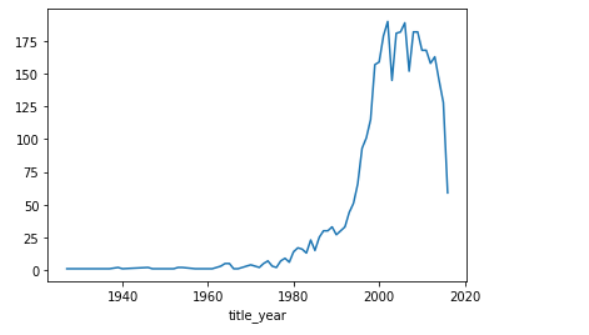
3.3 电影产量年份趋势
# 任务3、电影产量年份趋势
moive_years = data.groupby('title_year')['movie_title'].count()
plt.figure()
moive_years.plot()
# plt.savefig('./moive_year.png')
plt.show()
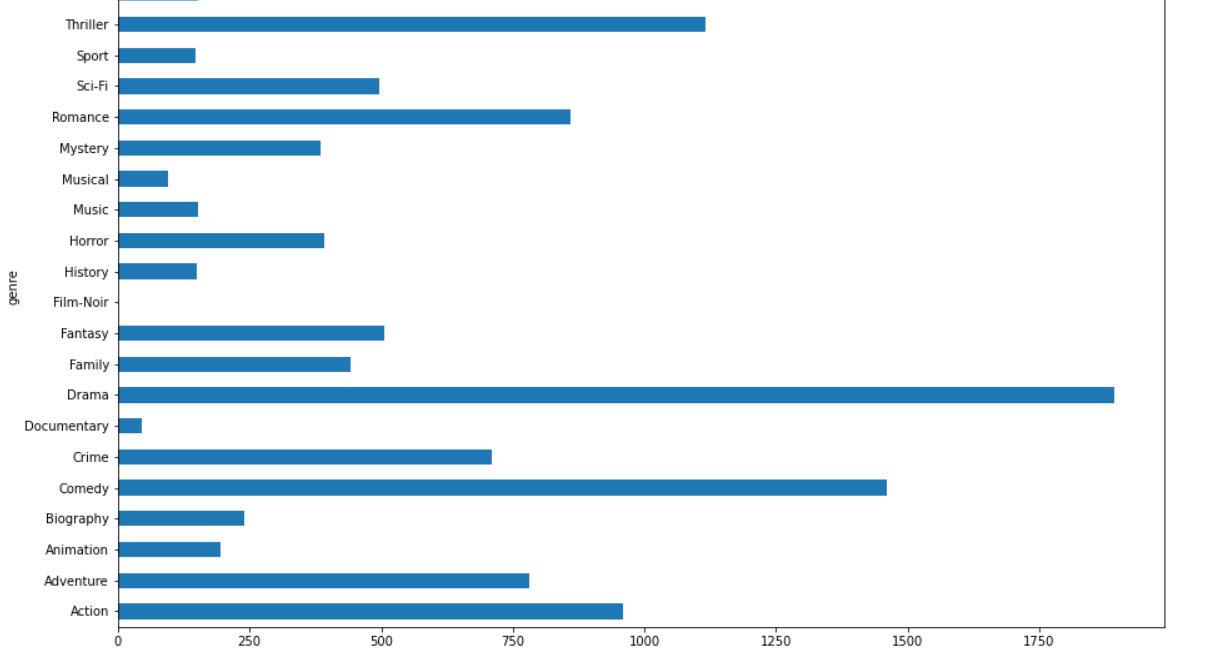
3.4电影类型分析
# 任务4、电影类型分析
# 每个电影可以对应好几种题材,将数据处理为一个电影对应一个类型
genre_data = pd.DataFrame(columns=['genre', 'gross'])
# data.iterrows:使用迭代器的方法读取数据,返回数字索引(int) 和每一行的数据
for i, row_data in data.iterrows():
# 使用split进行切割
genres = row_data['genres'].split('|')
n_genres = len(genres)
dict_obj = {}
# 构建一个空字典,用以保存genre和gross的值
dict_obj['gross'] = [row_data['gross']] * n_genres
# print(dict_obj['gross'])
dict_obj['genre'] = genres
# 将字典转为dataframe类型
genre_df = pd.DataFrame(dict_obj)
# dataframe中的append将gener_df的数据添加到genre_data
genre_data = genre_data.append(genre_df)
# 将最终的数据写入csv文件,进行保存
genre_data.to_csv('./genre_data.csv', index=None)
# 4.1、按题材分类。统计个数
genre_count = genre_data.groupby('genre').size()
plt.figure(figsize=(15.0,10.0))
genre_count.plot(kind='barh')
plt.savefig('./gener_count.png')
plt.show()
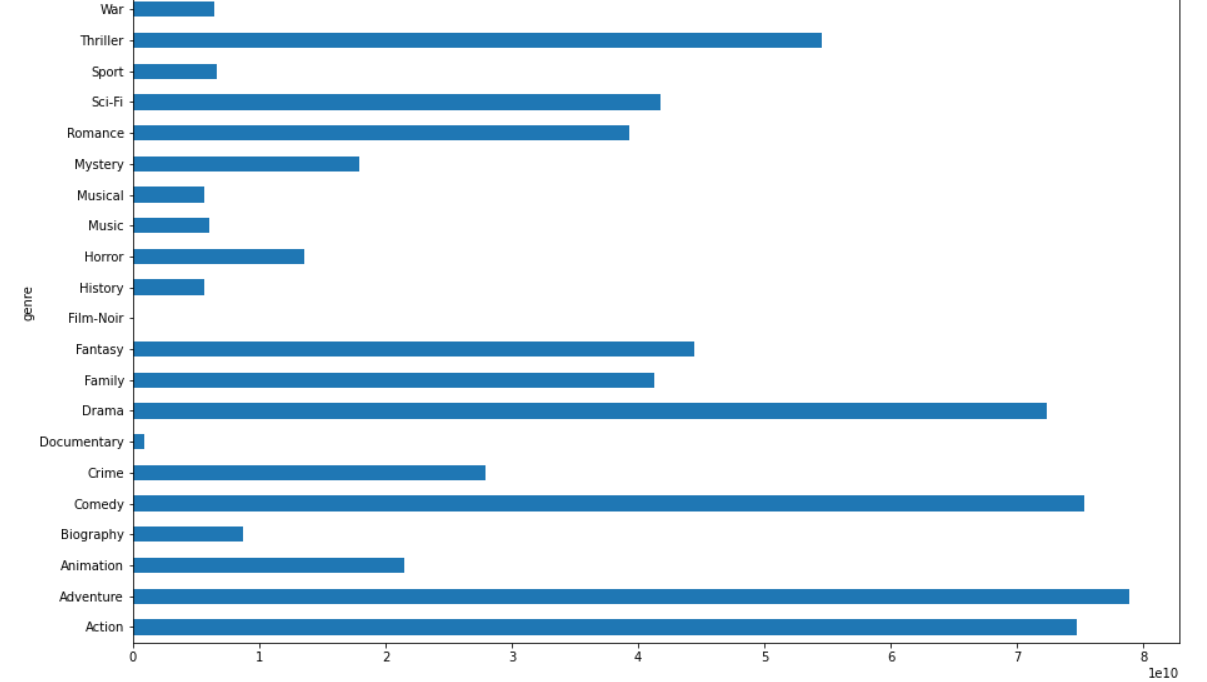
# 4.2 按题材统计票房
genre_gross = genre_data.groupby('genre')['gross'].sum()
plt.figure(figsize=(15.0,10.0))
genre_gross.plot(kind='barh')
plt.savefig('./genre_gross.png')
plt.show()