import requests import threading
import pymongo from threading import Lock from queue import Queue from lxml import etree # 爬虫类,负责采集数据的,(创建父线程类) class CrawlThread(threading.Thread): def __init__(self, name, pageQueue, dataQueue): # 爬虫类重写父类方法,但是又得调父类的一些方法,所有调用下父类方法 super().__init__() # 实例属性的初始化与赋值爬虫名字 self.threadname = name # 实例属性的初始化与赋值url队列 self.pageQueue = pageQueue # 实例属性的初始化与赋值headers,直接写死 self.headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36' } self.dataQueue = dataQueue def run(self): base_url = 'https://www.xiaohua.com/duanzi?page=%s' while 1: try: # block = True表示堵塞,没有东西时,一直等,只到等到有东西,False相反 page = self.pageQueue.get(block=False) url = base_url%page print('%s正在采集数据'%self.threadname) # 响应数据 response = requests.get(url=url, headers=self.headers) # put方法:Queue.put(item,[block[, timeout]]):将item消息写入队列,block默认值为True self.dataQueue.put(response.text) print('%s提交数据完毕'%self.threadname) except: break # 解析类,负责数据解析,(创建父线程类) class ParseThread(threading.Thread): def __init__(self, name, dataQueue, lock): super().__init__() self.threadname = name self.dataQueue = dataQueue self.lock = lock def run(self): while 1: try: html = self.dataQueue.get(block=False) print('%s正在解析数据'%self.threadname) # 调用方法并传参到具体的解析过程 self.parse(html) print('%s解析数据完毕'%self.threadname) except: break def parse(self, html): # 具体的解析过程 tree = etree.HTML(html) div_list = tree.xpath('//div[@class="one-cont"]') for div in div_list: item = {} author = div.xpath('./div/div/a/i/text()')[0] item['author'] = author # 上锁 with self.lock: self.save(item) def save(self, item): # 建立数据库连接,数据库存储 conn = pymongo.MongoClient('localhost', 27017) db = conn.jokes_dxc_author table = db.xhua table.insert_one(item) def main(): # 实例化队列,存放url pageQueue = Queue() for i in range(1, 101): pageQueue.put(i) # 存放脏数据 dataQueue = Queue() # 创建锁 lock = Lock() # 开启爬虫线程(爬虫名字) crawlList = ['爬虫1号','爬虫2号','爬虫3号'] # 循环赋值爬虫名字 ThreadCrawl = [] for var in crawlList: c = CrawlThread(var, pageQueue, dataQueue) c.start() ThreadCrawl.append(c) for var in ThreadCrawl: var.join() # 开启解析线程 parseList = ['解析一号','解析二号','解析三号'] ThreadParse = [] for var in parseList: p = ParseThread(var, dataQueue, lock) p.start() ThreadParse.append(p) for p in ThreadParse: p.join() if __name__ == '__main__': main()
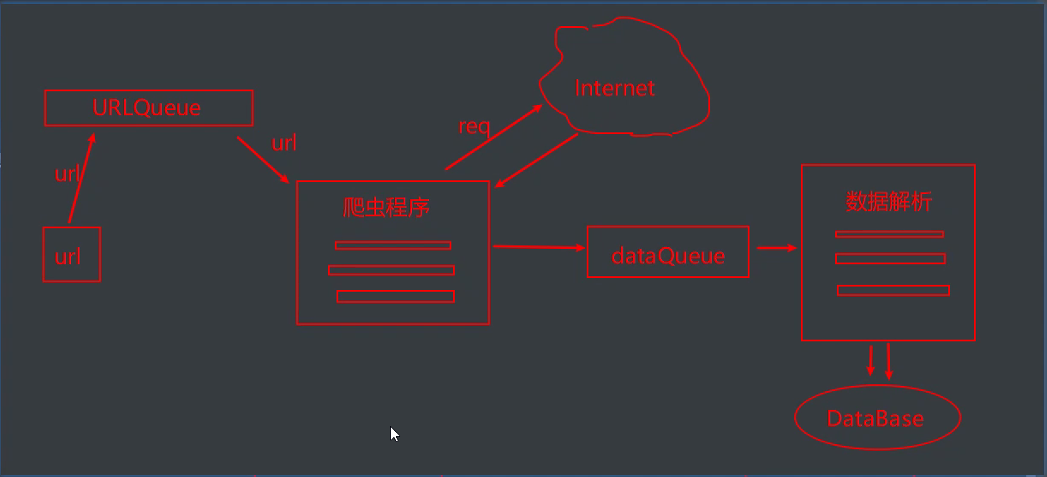
设计思路图: