爬取电影天堂最新电影,地址https://www.dytt8.net/html/gndy/dyzz/list_23_1.html
1 import requests 2 from lxml import etree 3 4 BASE_DOMAIN = 'https://www.dytt8.net' 5 HEADERS = { 6 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' 7 } 8 9 10 def get_detail_urls(url): 11 response = requests.get(url, headers=HEADERS) 12 text = response.content.decode(encoding='gbk', errors='ignore') 13 html = etree.HTML(text) 14 detail_urls = html.xpath('//table[@class="tbspan"]//a/@href') 15 detail_urls = map(lambda url: BASE_DOMAIN+url, detail_urls) 16 return detail_urls 17 18 19 def get_detail_info(url): 20 movie = {} 21 response = requests.get(url, headers=HEADERS) 22 text = response.content.decode(encoding='gbk', errors='ignore') 23 html = etree.HTML(text) 24 movie['title'] = html.xpath('//div[@class="title_all"]//font/text()')[0] 25 img = html.xpath("//div[@id='Zoom']//img/@src") 26 movie['cover'] = img[0] 27 movie['screenshot'] = img[1] 28 infos = html.xpath('//div[@id="Zoom"]//p/text()') 29 # 提取信息 30 is_actors = False 31 actors = [] 32 for info in infos: 33 # print(info) 34 if info.startswith('◎年 代'): 35 movie['year'] = info.replace("◎年 代", "").strip() 36 elif info.startswith('◎产 地'): 37 movie['country'] = info.replace("◎产 地", "").strip() 38 elif info.startswith('◎类 别'): 39 movie['category'] = info.replace("◎类 别", "").strip() 40 elif info.startswith('◎豆瓣评分'): 41 movie['douban_rating'] = info.replace("◎豆瓣评分", "").strip() 42 elif info.startswith('◎片 长'): 43 movie['duration'] = info.replace("◎片 长", "").strip() 44 elif info.startswith('◎导 演'): 45 movie['director'] = info.replace("◎导 演", "").strip() 46 elif info.startswith('◎主 演'): 47 actors = [info.replace("◎主 演", "").strip()] 48 is_actors = True 49 elif is_actors: 50 if info.startswith('◎'): 51 is_actors = False 52 movie['actors'] = actors 53 continue 54 actors.append(info.strip()) 55 movie['download'] = html.xpath("//div[@id='Zoom']//tbody//a/text()") 56 movie['magnet'] = html.xpath("//div[@id='Zoom']//a/@href")[0] 57 58 return movie 59 60 61 def spider(): 62 base_url = 'https://www.dytt8.net/html/gndy/dyzz/list_23_{}.html' 63 movies = [] 64 for i in range(1, 2): 65 url = base_url.format(i) 66 detail_urls = get_detail_urls(url) 67 for detail_url in detail_urls: 68 # 对详情页提取信息 69 # print(detail_url) 70 movies.append(get_detail_info(detail_url)) 71 print(movies) 72 73 74 if __name__ == '__main__': 75 spider()
学习的视频中代码有几处跟我的有不同,可以学习
一、
其中提取主演的代码不同,如下
for index,info in enumerate(infos): if info.startswith("◎年 代"): info = parse_info(info,"◎年 代") movie['year'] = info # .......省略 elif info.startswith("◎主 演"): info = parse_info(info,"◎主 演") actors = [info] for x in range(index+1,len(infos)): actor = infos[x].strip() if actor.startswith("◎"): break actors.append(actor) movie['actors'] = actors
采用的是index的方式.
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
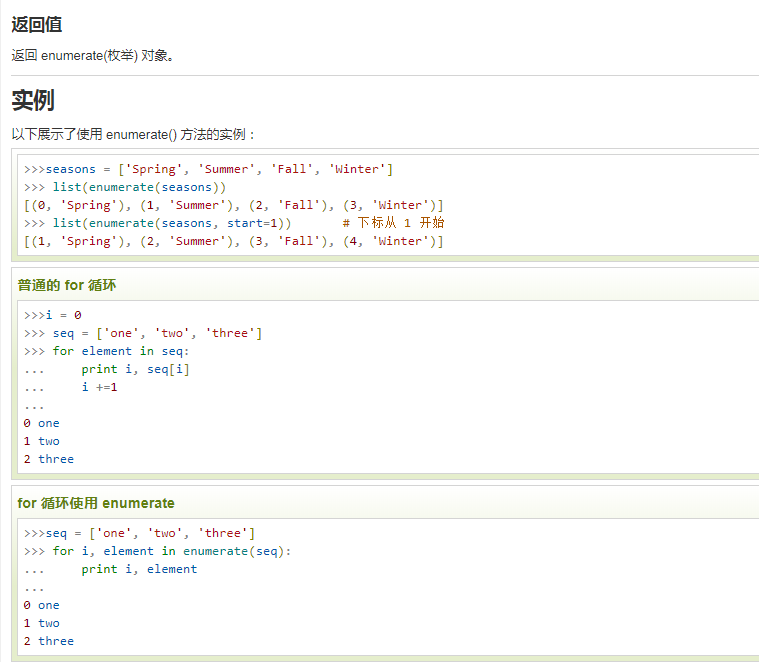
二、
还有
detail_urls = map(lambda url:BASE_DOMAIN+url,detail_urls)
这段代码没怎么用过.记录下.
三、
base_url = 'https://www.dytt8.net/html/gndy/dyzz/list_23_{}.html' for i in range(1, 10): url = base_url.format(i)
以前写的时候没这么写过,都是直接弄成
url = 'https://www.dytt8.net/html/gndy/dyzz/list_23_'+i+'.html'这样.
四、
在自己写代码时有个错误,也需要记录下,在movie的字典赋值的时候,
如下
for info in infos: # print(info) if info.startswith('◎年 代'): year = info.replace("◎年 代", "").strip() elif info.startswith('◎产 地'): country = info.replace("◎产 地", "").strip() elif info.startswith('◎类 别'): category = info.replace("◎类 别", "").strip() elif info.startswith('◎豆瓣评分'): douban_rating = info.replace("◎豆瓣评分", "").strip()
赋值的时候使用
movie = { 'year': year, 'country': country, 'category': category, 'douban_rating': douban_rating }
会报错,因为其中有一个豆瓣评分是不存在的,不会对其赋值,所以movie赋值的时候会错误.
UnboundLocalError: local variable 'douban_rating' referenced before assignment
当然,个人觉得用正则可以更容易解决。
在记录下爬取豆瓣正在上映的电影用xpath的代码
import requests from lxml import etree headers = { 'Referer': 'https://movie.douban.com/', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36' } url = "https://movie.douban.com/cinema/nowplaying/changsha/" response = requests.get(url, headers=headers) text = response.text html = etree.HTML(text) lis = html.xpath("//div[@id='nowplaying']//ul[@class='lists']/li") movies = [] for li in lis: # print(etree.tostring(li, encoding='utf-8').decode('utf-8')) title = li.xpath("@data-title")[0] score = li.xpath("@data-score")[0] duration = li.xpath("@data-duration")[0] director = li.xpath("@data-director")[0] actor = li.xpath("@data-actors")[0] img = li.xpath(".//img/@src")[0] movie = { 'title': title, 'score': score, 'duration': duration, 'director': director, 'actor': actor, 'img': img } movies.append(movie) print(movies)