Resampling methods are an indispensable tool in modern statistics.
In this chapter, we discuss two of the most commonly used resampling methods, cross-validation and the bootstrap.
For example,cross-validation can be used to estimate the test error associated with a given statistical learning method in order to evaluate its performance, or to select the appropriate level of flexibility.
The bootstrap is used in several contexts, most commonly model to provide a measure of accuracy of a parameter estimate or of a given selection statistical learning method.
5.1 Cross-Validation
In this section, we instead consider a class of methods that estimate the test error rate by holding out a subset of the training observations from thefitting process, and then applying the statistical learning method to those held out observations.
5.1.1The Validation Set Approach
Suppose that we would like to estimate the test error associated with fitting a particular statistical learning method on a set of observations. The validation set approach, displayed in Figure 5.1, is a very simple strategy validation for this task.
这种方法首先随机地把可获得的观测集分为两部分:一个训练集(training set)和一个验证集( validation set,或者说保留集( hold-out set) 。模型在训练集上拟合,然后用拟合的模型来预测验证集中观测的响应变量。最后得到的验证集错误率——通常用均方误差作为定量响应变量的误差度量——提供了对于测试错误率的一个估计
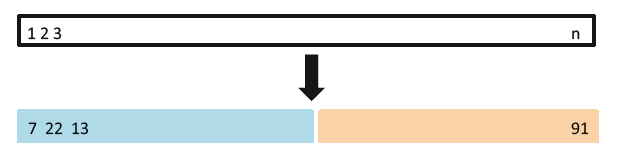
FIGURE 5.1. A schematic display of the validation set approach. A set of n observations are randomly
split into a training set (shown in blue, containing observations 7, 22, and 13, among others) and a
validation set (shown in beige, and containing observation 91, among others). The statistical learning
method is fit on the training set, and its performance is evaluated on the validation set
验证集方法原理简单但有两个潜在的缺陷:
- 测试错误率的验证法估计的波动很大,这取决于具体哪些观测被包括在训练集中,哪些观测被包括在验证集中。
- 在验证法中,只有一部分观测,验证集错误率可能会高估在整个数据集上拟合模型所得到的测试错误率。
5.1.2 Leave-One-Out Cross-Validation(留一交叉验证法LOOCV)
和验证法很相似,但这种方法尝试去解决验证法的缺陷。
LOOCV也将观测集分为两类,但只留下一个单独的观测值(x1, y1)作为验证集,剩下的观测{(x2, y2), . . . , (xn, yn)}作为训练集
The LOOCV estimate for the test MSE is the average of these n test error estimates:
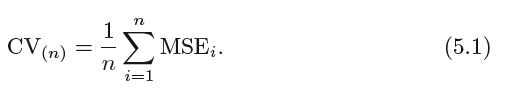
LOOCV的原理如下图所示:
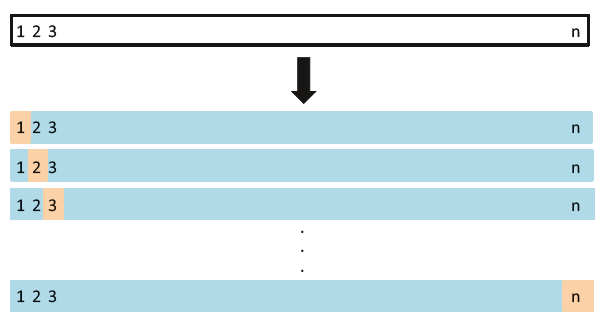
FIGURE 5.3. A schematic display of LOOCV
相对于验证集方法,LOOCV的优势如下:
- 偏差更小,LOOCV 方法比验证集方法更不容易高估测试错误率
- 第二,由于训练集和验证集分割的随机性,反复运用时会产生不同的结果,多次运用LOOCV 方法总会得到相同的结果:这是因为LOOCV 方法在训练集和验证集的分割上不存在随机性。
5.1.3 k-Fold Cross-Validation(k折交叉验证)
This approach involves randomly k-fold CV dividing the set of observations into k groups, or folds, of approximately equal size. The first fold is treated as a validation set, and the method is fit on the remaining k − 1 folds. The mean squared error, MSE1, is then computed on the observations in the held-out fold. This procedure is repeated k times; each time, a different group of observations is treated as a validation set. This process results in k estimates of the test error, MSE1,MSE2, . . . ,MSEk. The k-fold CV estimate is computed by averaging these values,
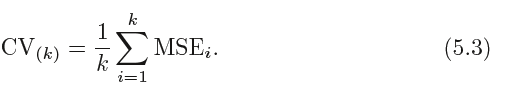

5.1.4 Bias-Variance Trade-Off for k-Fold Cross-Validation
当k<n 时, k 折CV 方法相对于LOOCV 方法有计算上的优势。
但LOOCV 方法的方差要比k 折CV 方法的方差大,因为在使用LOOCV方法时,实际上是在平均n个拟合模型的结果,每一个模型都是在几乎相同的观测集上训练的;因此,这些结果相互之间笼高度{正)相关的。相反,在使用k<n 的k 折CV 方法时,由于每个模型的训练集之间的重叠部分相对较小,因此是在平均k个相关性较小的拟合模型的结果。由于许多高度相关的量的均值要比不相关性相对较小的量的均值具有更高的波动性,因此用LOOCV 方法所产生的测试误差估计的方差要比k 折CV 方法所产生的测试误差估计的方差大。
通常来说,考虑到上述因素,使用k 折交叉时一般令k=5 或k =10。因为从经验上来说,这些值使得测试错误率的估计不会有过大的偏差或方差。
5.1.5 Cross-Validation on Classification Problems
在分类问题中,交叉验证法与之前的基本一致,区别仅在于是被误分类的观测的数量来作为衡量测试误差的指标,而不是用均方误差。
分类问题的LOOCV方法的错误率形式为:
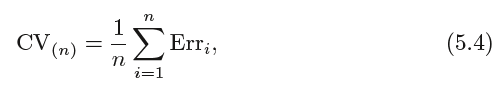
where Erri = I(yi != ˆyi). The k-fold CV error rate and validation set error rates are defined analogously.
5.2 The Bootstrap
The bootstrap is a widely applicable and extremely powerful statistical tool bootstrap that can be used to quantify the uncertainty associated with a given estimator
or statistical learning method.
Suppose that we wish to invest a fixed sum of money in two financial assets that yield returns of X and Y , respectively, where X and Y are random quantities.
We will invest a fraction α of our money in X, and will invest the remaining 1 − α in Y . Since there is variability associated with the returns on these two assets,
we wish to choose α to minimize the total risk, or variance, of our investment. In other words, we want to minimize Var(αX +(1 −α)Y ). One can show that the
value that minimizes the risk is given by
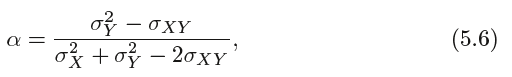
where σ2X= Var(X), σ2Y= Var(Y ), and σXY = Cov(X, Y ).
真实值未知,可以使用过去的值估计:
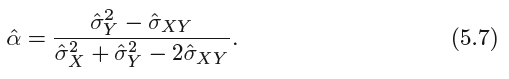


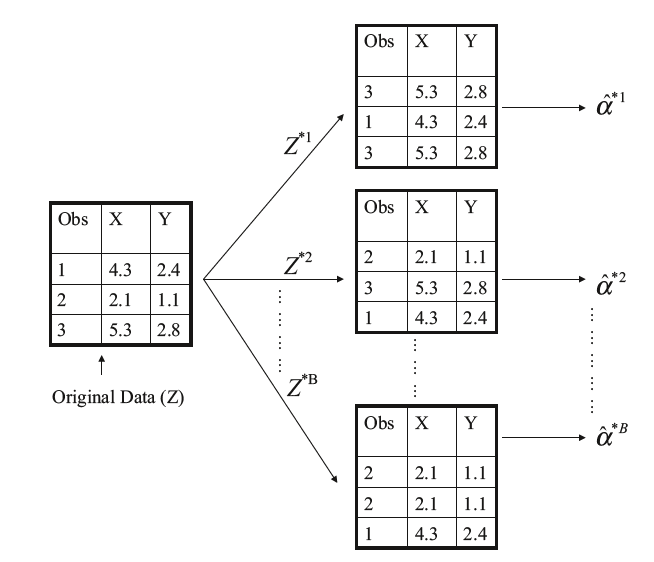
但是在实际中,以上大致地评估SE(ˆα)这个步骤是不能实现的,因为对于真实数据,不能从原始的总体中生成新的样本。
However, the bootstrap approach allows us to use a computer to emulate the process of obtaining new sample sets,
so that we can estimate the variability of ˆα without generating additional samples. Rather than repeatedly obtaining
independent data sets from the population, we instead obtain distinct data sets by repeatedly sampling observations from the original data set.