之前的文章我们介绍了一下 Python 的 json 模块,本章我们就介绍一下之前根据 Xpath 模块做的爬取《糗事百科》的糗事进行丰富和完善。
在 Xpath 模块的爬取糗百的案例中我们只是爬取了其中的糗事,然后存储到本地,并没有作者姓名,头像等信息,所有我们通过之前介绍的 path 模块讲获取到的完整信息以 json 的形式存储到本地。
我们要爬取的网站链接是 https://www.qiushibaike.com/text/page/1/ 。

我们通过 Xpath Helper 的谷歌插件经过分析获取到我们想要的内容为: //div[contains(@id,"qiushi_tag")]
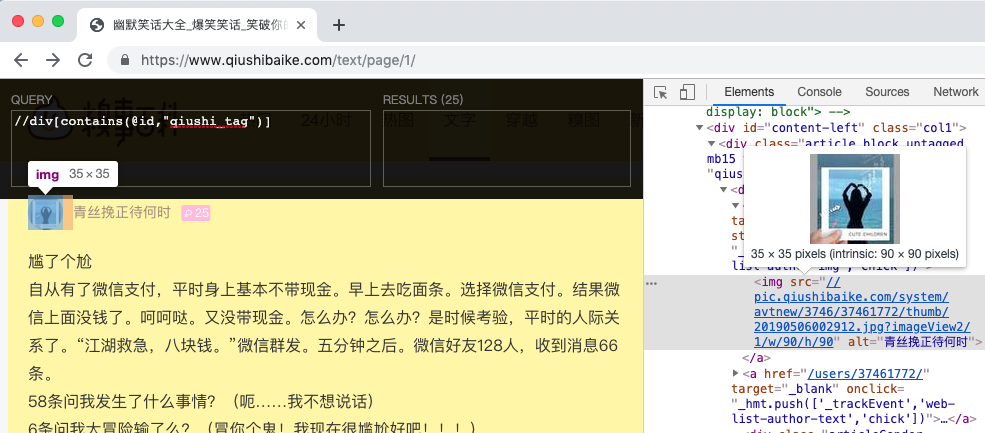
1 import urllib.request 2 from lxml import etree 3 import ssl 4 5 # 取消代理验证 6 ssl._create_default_https_context = ssl._create_unverified_context 7 8 url = "https://www.qiushibaike.com/text/page/1/" 9 # User-Agent头 10 user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36' 11 headers = {'User-Agent': user_agent} 12 req = urllib.request.Request(url, headers=headers) 13 response = urllib.request.urlopen(req) 14 # 获取每页的HTML源码字符串 15 html = response.read().decode('utf-8') 16 # 解析html 为 HTML 文档 17 selector = etree.HTML(html) 18 content_list = selector.xpath('//div[contains(@id,"qiushi_tag")]') 19 print(content_list)
输出结果为:

从上面的输出结果可以看出我们已经拿到了我们想要的数据,并且是一个列表类型,我们对列表进行操作扥别拿到糗事再存储到本地即可。
1 items = {} 2 for site in content_list: 3 imgUrl = site.xpath('./div/a/img/@src')[0] # 头像 4 username = site.xpath('./div/a/img/@alt')[0] # 作者 5 content = site.xpath('.//div[@class="content"]/span[1]/text()') 6 items = { 7 "imgUrl": imgUrl, 8 "username": username, 9 "content": content, 10 } 11 12 with open("qiushi.json", "a") as f: 13 f.write(json.dumps(items, ensure_ascii=False) + ", ")
上面就可以实现一个获取 糗事百科 的糗事的简单爬虫,但是只能爬取单个页面的内容,通过分析 url 我们发现 https://www.qiushibaike.com/text/page/1/ 中最后的 1 即为页码,我们就可以根据这个页码逐一爬取更多页面的内容,最终的代码如下:
1 import urllib.request 2 from lxml import etree 3 import json 4 import ssl 5 6 # 取消代理验证 7 ssl._create_default_https_context = ssl._create_unverified_context 8 9 10 class Spider: 11 def __init__(self): 12 # 初始化起始页位置 13 self.page = 2 14 # 爬取开关,如果为True继续爬取 15 self.switch = True 16 17 def loadPage(self): 18 """ 19 作用:打开页面 20 """ 21 url = "https://www.qiushibaike.com/text/page/" + str(self.page) + "/" 22 # User-Agent头 23 user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36' 24 headers = {'User-Agent': user_agent} 25 req = urllib.request.Request(url, headers=headers) 26 response = urllib.request.urlopen(req) 27 # 获取每页的HTML源码字符串 28 html = response.read().decode('utf-8') 29 # 解析html 为 HTML 文档 30 selector = etree.HTML(html) 31 content_list = selector.xpath('//div[contains(@id,"qiushi_tag")]') 32 # 调用dealPage() 处理糗事里的杂七杂八 33 self.dealPage(content_list) 34 35 def dealPage(self, item_list): 36 """ 37 @brief 处理得到的糗事列表 38 @param item_list 得到的糗事列表 39 @param page 处理第几页 40 """ 41 for site in item_list: 42 # 根据查询发现匿名用户和非匿名用户的标签不一样 43 try: 44 # 非匿名用户 45 imgUrl = site.xpath('./div/a/img/@src')[0] # 头像 46 username = site.xpath('./div/a/img/@alt')[0] # 作者 47 except Exception: 48 # 匿名用户 49 imgUrl = site.xpath('./div/span/img/@src')[0] # 头像 50 username = site.xpath('./div/span/img/@alt')[0] # 作者 51 content = site.xpath('.//div[@class="content"]/span[1]/text()') 52 items = { 53 "imgUrl": "https:" + imgUrl, 54 "username": username, 55 "content": content, 56 } 57 58 self.writePage(items) 59 60 def writePage(self, items): 61 """ 62 @brief 将数据追加写进文件中 63 @param text 文件内容 64 """ 65 myFile = open("./qiushi.json", 'a') # 追加形式打开文件 66 myFile.write(json.dumps(items, ensure_ascii=False) + ", ") 67 myFile.close() 68 69 def startWork(self): 70 """ 71 控制爬虫运行 72 """ 73 # 循环执行,直到 self.switch == False 74 while self.switch: 75 # 用户确定爬取的次数 76 self.loadPage() 77 command = input("如果继续爬取,请按回车(退出输入quit)") 78 if command == "quit": 79 # 如果停止爬取,则输入 quit 80 self.switch = False 81 # 每次循环,page页码自增1 82 self.page += 1 83 print("爬取结束!") 84 85 86 if __name__ == '__main__': 87 # 定义一个Spider对象 88 qiushiSpider = Spider() 89 qiushiSpider.startWork()
程序启动后会在本地生成一个 city.json 的文件,结果如下:
