1.使用make_blobs来生成数据集,然后对数据集进行预处理
#导入数据集生成器 from sklearn.datasets import make_blobs #导入数据集拆分工具 from sklearn.model_selection import train_test_split #导入预处理工具 from sklearn.preprocessing import StandardScaler #导入多层感知器神经网络 from sklearn.neural_network import MLPClassifier #导入画图工具 import matplotlib.pyplot as plt
#生成样本数量200,分类为2,标准差为5的数据集
X,y = make_blobs(n_samples=200,centers=2,cluster_std=5)
#将数据集拆分为训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=38)
#对数据进行预处理
scaler = StandardScaler().fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
#将处理后的数据形态进行打印
print('
')
print('代码运行结果')
print('====================================
')
#将处理后的数据形态进行打印
print('训练数据集:{}'.format(X_train_scaled.shape),' 标签形态:{}'.format(X_test_scaled.shape))
print('
====================================')
print('
')
代码运行结果 ==================================== 训练数据集:(150, 2) 标签形态:(50, 2) ====================================
#训练原始数据集
plt.scatter(X_train[:,0],X_train[:,1])
#经过预处理的训练集
plt.scatter(X_train_scaled[:,0],X_train_scaled[:,1],marker='^',edgecolor='k')
#添加图题
plt.title('training set & scaled training set')
#显示图片
plt.show()
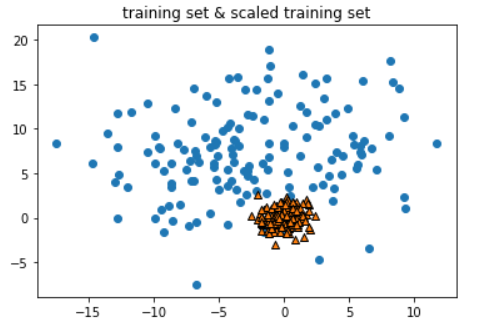
- 这里可以看到,StandardScaler将训练集的数据变得更加"聚拢"
#导入网格搜索
from sklearn.model_selection import GridSearchCV
#设定网格搜索的模型参数字典
params = {'hidden_layer_sizes':[(50,),(100,),(100,100)],'alpha':[0.0001,0.01,0.1]}
#建立网格搜索模型
grid = GridSearchCV(MLPClassifier(max_iter=1600,random_state=38),param_grid=params,cv=3,iid=False)
#拟合数据
grid.fit(X_train_scaled,y_train)
#将结果进行打印
print('
')
print('代码运行结果')
print('====================================
')
print('模型最佳得分:{:.2f}'.format(grid.best_score_),' 模型最佳参数:{}'.format(grid.best_params_))
print('
====================================')
print('
')
代码运行结果
====================================
模型最佳得分:0.81 模型最佳参数:{'alpha': 0.0001, 'hidden_layer_sizes': (50,)}
====================================
#打印模型在测试集中的得分
print('
')
print('代码运行结果')
print('====================================
')
print('测试集得分:{}'.format(grid.score(X_test_scaled,y_test)))
print('
====================================')
print('
')
代码运行结果 ==================================== 测试集得分:0.82 ====================================
- 可以看到这种做法得到的模型分数很高,但是仔细想想这种做法是错误的,我们在交叉验证中,将训练集又拆分成了training fold和validation fold,但用StandardScaler进行预处理的时候,是使用training fold 和 validation fold 一起进行的拟合.这样一来,交叉验证的得分就是不准确的.
2.使用管道模型(Pipeline)
#导入管道模型
from sklearn.pipeline import Pipeline
#建立包含预处理和神经网络的管道模型
pipeline = Pipeline([('scaler',StandardScaler()),('mlp',MLPClassifier(max_iter=1600,random_state=38))])
#用管道模型对训练集进行拟合
pipeline.fit(X_train,y_train)
#打印管道模型的分数
print('使用管道模型的MLP模型评分:{:.2f}'.format(pipeline.score(X_test,y_test)))
使用管道模型的MLP模型评分:0.82
- 我们在管道模型Pipeline中使用了两个方法,一个是用来进行数据预处理的StandardScaler.另一个是最大迭代数为1600的MLP多层感知器神经网络.
3.使用管道模型进行网格搜索
GridSearchCV拆分的训练集和验证集,不是train_test_split拆分的训练集和测试集,而是在train_test_split拆分的训练集上再进行拆分,所得到的的结果
#设置参数字典--------(mlp__是用于指定pipeline中的mlp算法)
params = {'mlp__hidden_layer_sizes':[(50,),(100,),(100,100)],'mlp__alpha':[0.0001,0.001,0.01,0.1]}
#建立包含预处理和神经网络的管道模型
pipeline = Pipeline([('scaler',StandardScaler()),('mlp',MLPClassifier(max_iter=1600,random_state=38))])
#将管道模型加入网格搜索
grid = GridSearchCV(pipeline,param_grid=params,cv=3,iid=False)
#对训练集进行拟合
grid.fit(X_train,y_train)
#打印模型交叉验证分数.最佳参数和测试集得分
print('
')
print('代码运行结果')
print('====================================
')
print('交叉验证最高分:{:.2f}'.format(grid.best_score_))
print('模型最有参数:{}'.format(grid.best_params_))
print('测试集得分:{}'.format(grid.score(X_test,y_test)))
print('
====================================')
print('
')
代码运行结果
====================================
交叉验证最高分:0.80
模型最有参数:{'mlp__alpha': 0.0001, 'mlp__hidden_layer_sizes': (50,)}
测试集得分:0.82
====================================
- 在hidden_layer_sizes和alpha前面都添加了mlp__这样一个前缀,这样做是为了pipeline中有多个算法,我们需要让pipeline知道这个参数是传给哪一个算法的.
#打印管道模型中的步骤
print('
')
print('代码运行结果')
print('====================================
')
print(pipeline.steps)
print('
====================================')
print('
')
代码运行结果
====================================
[('scaler', StandardScaler(copy=True, with_mean=True, with_std=True)), ('mlp', MLPClassifier(activation='relu', alpha=0.0001, batch_size='auto', beta_1=0.9,
beta_2=0.999, early_stopping=False, epsilon=1e-08,
hidden_layer_sizes=(100,), learning_rate='constant',
learning_rate_init=0.001, max_iter=1600, momentum=0.9,
n_iter_no_change=10, nesterovs_momentum=True, power_t=0.5,
random_state=38, shuffle=True, solver='adam', tol=0.0001,
validation_fraction=0.1, verbose=False, warm_start=False))]
====================================
总结 :
除了能够将更多的算法进行整合,实现代码的简洁之外,管道模型还可以避免我们在预处理过程中,使用不当的方式对训练集和验证集进行错误的预处理.通过使用管道模型,可以在网格搜索每次拆分训练集与验证集之前,重新对训练集和验证集进行预处理操作,避免了模型过拟合的情况.
文章引自 : 《深入浅出python机器学习》