搜索命令:/正则表达式
替换命令::s/正则表达式/替换字符串/选项
:%s/str1/str2/g 该命令中:表示进入命令行模式,%表示对该文件所有行有效,s表示查找并替换,正则表达式str1表示被替换的内容,字符串str2表示替换后的内容,g表示整行有效
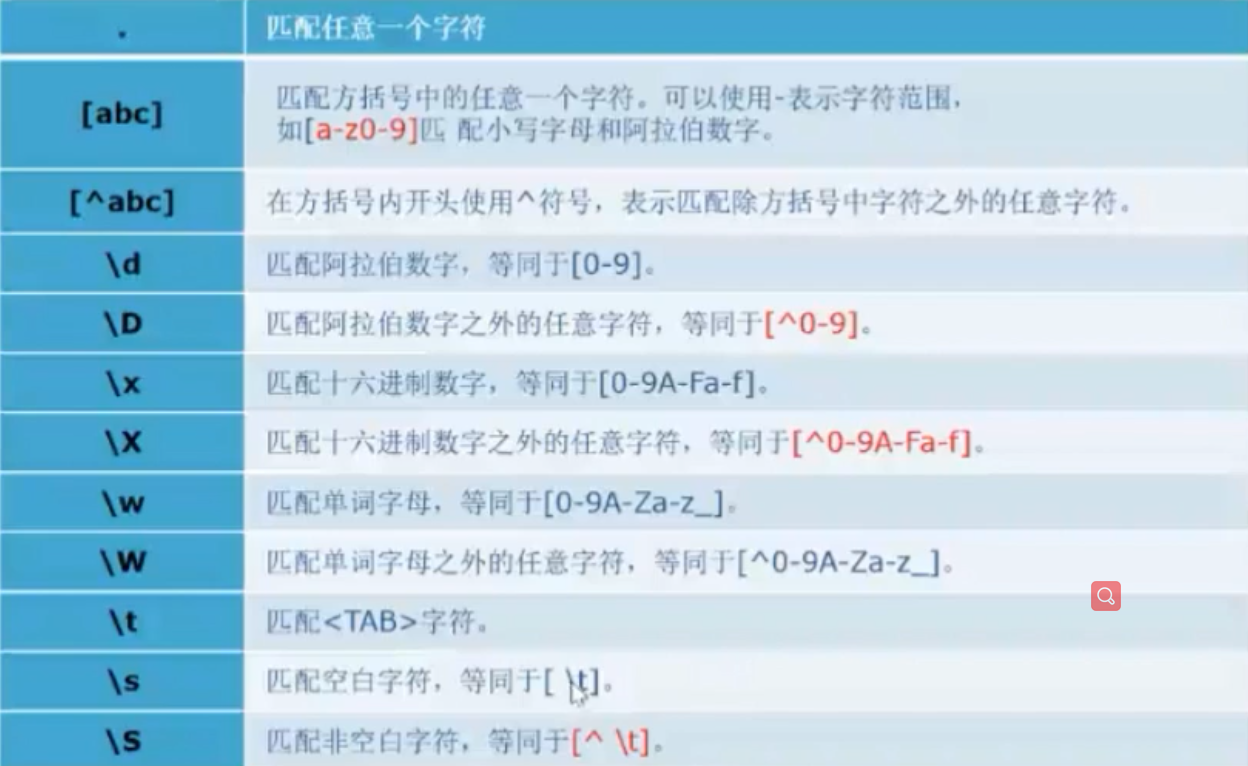
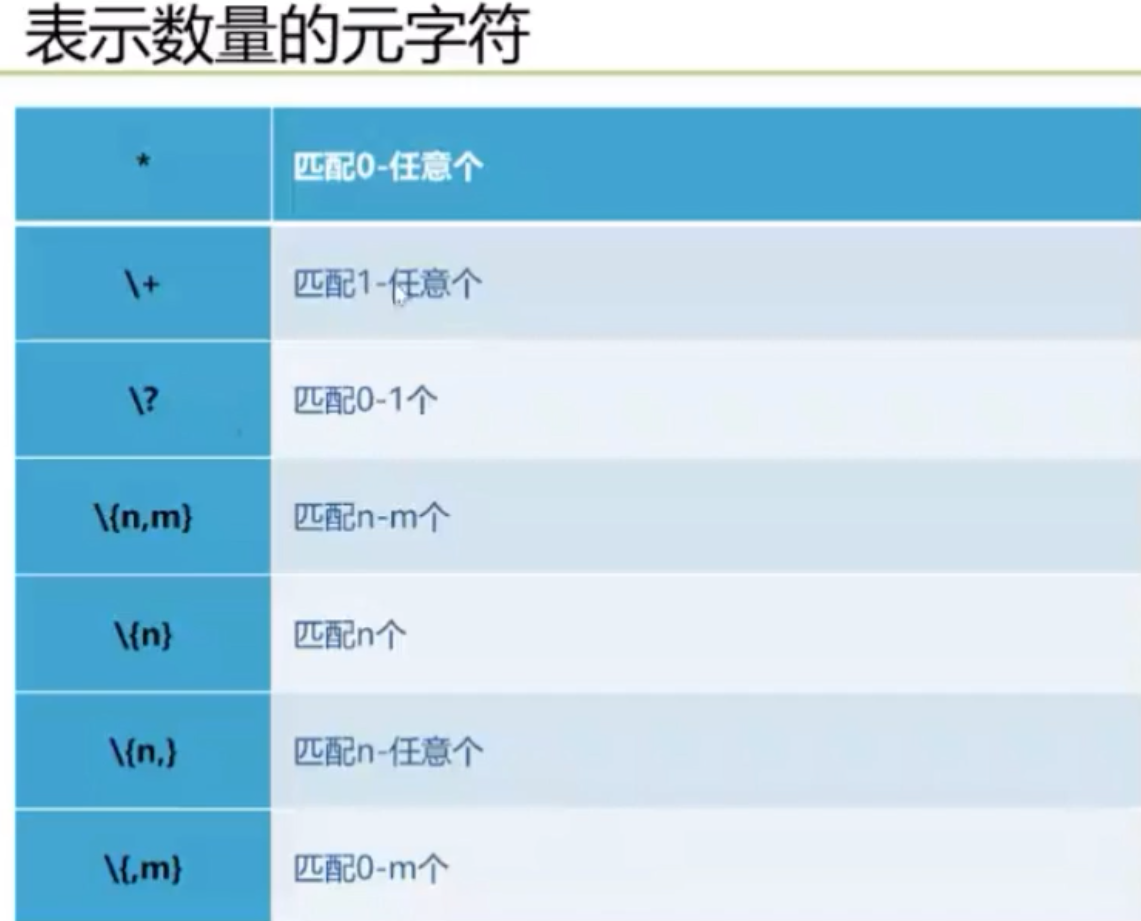
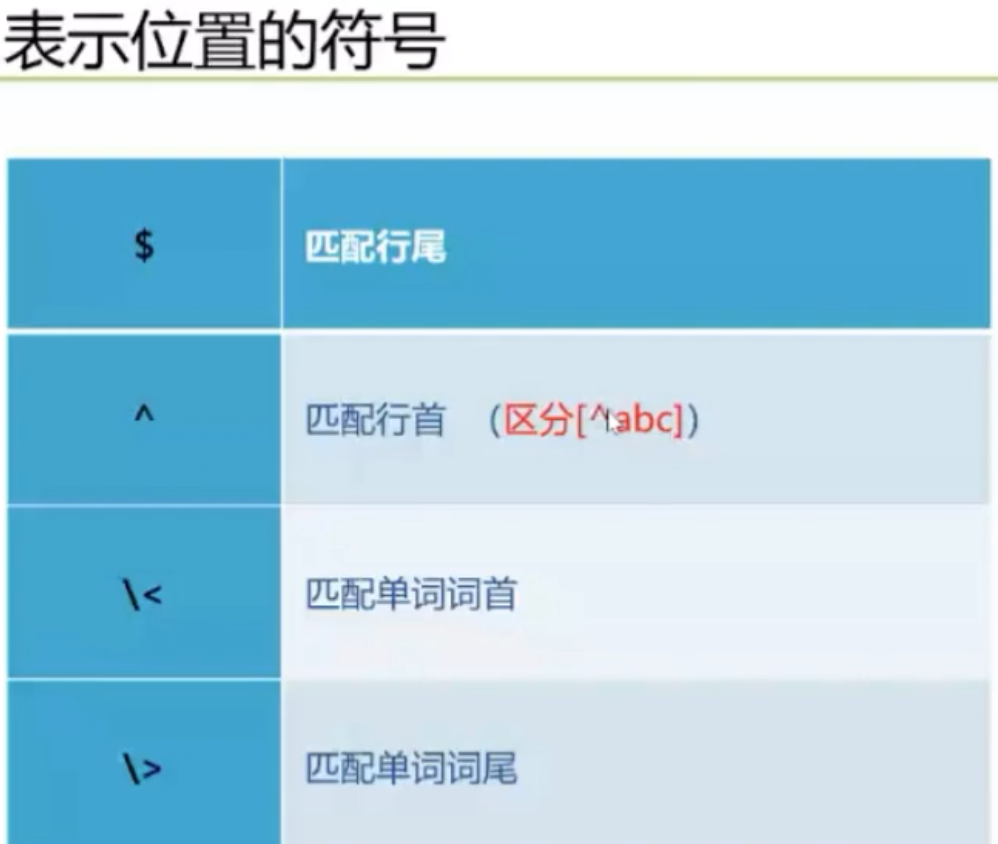
正则表达式字符匹配

实例替换
![]()
![]()
![]()
实例删除

3.删除所有空行
:g/^$/d (删除没有任何字符除了一个回车符的行)
:g/^[ ]*$/d (删除有空格或是tab符号的所有行)
4.删除含有某些字符的行
:g/ERROR/d (删除含有ERROR字符的所有行,d是删除指令)
5.删除每行的所有前导空格
:%s/^ *//g (后面的//之间没有任何东西,也就是说不用任何东西去替换前面的前导空格,即删除前导空格)
6.在文件中的每一行的开始插入 -> (或者换其他字符)
:%s/^/->/g
7.在每一行的尾部加上一个句号(或者其他字符)
:%s/$/。/g
8.删除以数字开头的行
:%s/^d.*$//g
9.删除以abc三个字母一起开头的行
:%s/^[a|b|c].*$//g或者:%s/^abc.*$//g
10.删除重复行
:%s/^(.*) 1$/1/g 将两行重复行压缩成一行(/^匹配到行首,.*匹配任意多个字符,(.*)相当于把之前匹配得到的字符保存下来,1就表示保存的内容, 1表示换行之后再去匹配之前保存的字符,到这里就匹配了两行,$接着到换行之后的行尾,之后的1表示用前面保存的匹配到的第一行字符去替换匹配得到的两行字符,这就相当于把两行重复行压缩成一行)
:%s/^(.*)( 1)+$/1/g 将多行重复行压缩成一行 ( 1)+表示匹配任意多重复行

实例对调
1.交换列表中所有连字符分隔的条目的顺序
如将ABC:XYZ对换成XYZ:ABC
:%s/(.*):(.*)/2:1/g 1表示第一次保存的内容,2表示第二次保存的内容
函数式
格式:
:s/str1/=函数式
例1:将各行的id字符串替换为行号
:%s/<id>/=line(".") <id>匹配的是单独的词id,而不是amid这类嵌在某个单词里面的字符。line(".")是返回各行行号的一个函数。
例2:将每行开头的单词替换为(行号-10)
:%s/^<w+>/=(line(".")-10)
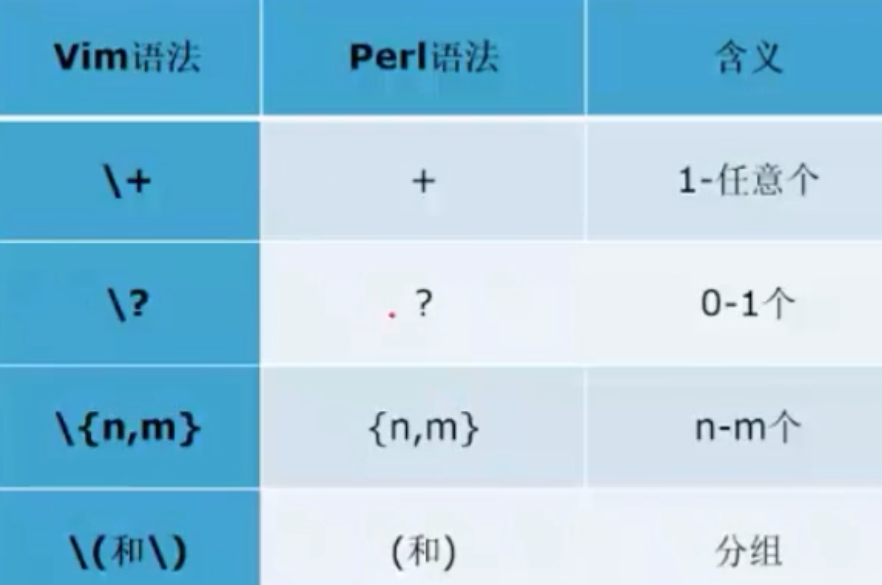
与Perl正则表达式的区别
Sed用法(用来直接处理文件)
