1 监督学习
利用一组带标签的数据, 学习从输入到输出的映射, 然后将这种映射关系应用到未知数据, 达到分类或者回归的目的
(1) 分类: 当输出是离散的, 学习任务为分类任务
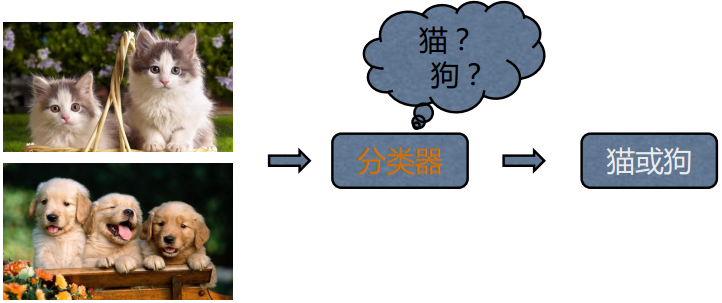
输入: 一组有标签的训练数据(也叫观察和评估), 标签表明了这些数据(观察)的所属类别, 图中"猫"和"狗"就是标签
输出: 分类模型根据这些训练数据, 训练自己的模型参数, 学习出一个适合这组数据的分类器, 当有新数据(非训练数据)需要进行类别判断, 就可以将这组数据作为输入送给学习好的分类器进行判断(得到标签)
训练集: 训练模型已经标注的数据, 用来建立模型发现规律
测试集: 已标注的数据, 只不过把标注隐藏了, 再送给训练好的模型, 比对结果与原来的标注, 评判该模型的学习能力
一般来说, 获得了一组标注好的数据, 70%当做训练集, 30%当做测试集, 另外还有交叉验证法, 自助法来评估学习模型
评价标准
1) 准确率
所有预测对的
把正类预测成正类(TP)
把负类预测成负类(TN)
准确率 = (TP+TN)/总数量
2) 精确率
以二分类为例
预测为正的样本是真的正样本
把正类预测为正类(TP)
把负类预测为正类(FP)
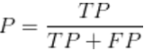
3) 召回率
样本中的正比例有多少被预测正确
把正类预测成正类(TP)
把正类预测成负类(FN)

sklearn提供的分类函数有:
K近邻(knn), 朴素贝叶斯(naivebayes), 支持向量机(svm), 决策树(decision tree), 神经网络模型(Neural networks)
(2) 回归: 当输出是连续的, 学习任务是回归任务
通过回归, 可以了解两个或多个变数是否相关, 方向及其强度, 可以建立数学模型来观察特定变数以及预测特定的变数
回归可以根据给出的自变量估计因变量的条件期望
sklearn提供的回归函数放在了两个子模块
sklearn.linear_model, 线性函数: 普通线性回归函数(LinearRegression), 岭回归(Ridge), Lasso
sklearn.preprocessing, 非线性回归: 多项式回归(PolynomialFeatures)
回归应用
对一些带有时序信息的数据进行预测或者趋势拟合, 在金融以及其他涉及时间序列分析的领域
股票趋势预测
交通流量预测
2 分类
2.1 人体运动信息评级实例
可穿戴设备可以获取人体各项数据, 通过这些数据可以进行分析和建模, 可以对用户状况进行判断
在数据源中有一个特征文件*.feature, 一个标签文件*.label
特征文件包含41列特征


温度: 静止时人体一般维持在36.5度上下, 当温度高于37度时, 可能是进行短时间的剧烈运动
一型/二型三轴加速区: 这是两个型号的加速度传感器, 两个加速度传感器可以相互印证来保证数据的完整性准确性, 获得的数据是在x,y,z三个轴上的加速度, 如z轴上加速度剧增, 很有可能就是人体向上跳
陀螺仪: 获得用户当前身体的角度, 可以判断姿态
磁场: 检测用户周围磁场强度和数值大小, 可以帮助我们理解用户所在的环境, 一般地, 人在一个办公场所, 用户座位的周围的磁场大体上是固定的, 因此当磁场发生改变时, 可以推测用户的位置和场景发生了变化
标签文件对应于特征文件的每一行, 总共有25中姿态
2.2 基本分类模型
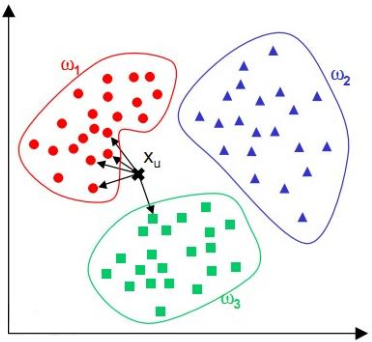
(1) k近邻分类器(KNN)
原有已经分类好的点, 现加入新的点, 判断其类别就是查看所有点与它的距离, 取前K个, 这K个点哪一部分的的点的数量多, 这个新加入的点就属于哪一部分
创建knn分类器
sklearn.neighbors.KNeighborsClassifier()
n_neighbors: 用于指定分类器中K的大小, 默认为5
weights: 设置K个点对分类结果影响的权重, 默认平均权重uniform, 距离权重(越近权重越高)distance, 或者是自定义计算函数
algorithm: 寻找临近点的方法, 默认为auto(根据数据自动选择), ball_tree, kd_tree, brute等
使用kkn
X = [[0],[1],[2],[3]]
y = [0,0,1,1]
from sklearn.neighbors import KNeighborsClassifier
neight = KNeighborsClassifier(n_neighbors=3)
neight.fit(X,y)
Out[5]:
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=3, p=2,
weights='uniform')
neight.predict([[1.1]])
Out[6]: array([0])
其中X是数据, y是标签, 使用predict()来预测新的点, 检查前3个点, 应该是[1],[2],[0]主要是标签0的数据点, 因此[1.1]被划分到标签0中
关于k的选取
较大的k值, 由于邻域较大, 有可能和他就近的分类点不多, 所以可能结果出错
较小的k值, 邻域较小, 有可能邻居是噪声点, 导致过拟合
一般来说, 选择较小的k, 然后使用交叉验证选取最优的k值
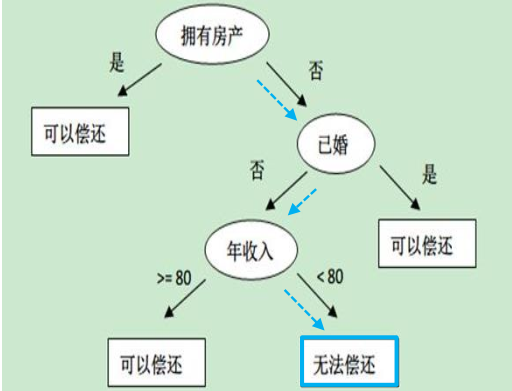
(2) 决策树
一般是询问分类点的属性决定走向的分支, 不断查询获得最终的分类
无房产单身年收入55k的决策效果
创建决策树
sklearn.tree.DecisionTree.Classifier()
criterion: 选择属性的准则, gini(基尼系数), entropy(信息增益)
max_features: 从多少个特征中选择最优特征, 默认是所有特征个数, 还可以是固定数目, 百分比等
决策树的使用
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
clf = DecisionTreeClassifier()
iris = load_iris()
cross_val_score(clf, iris.data, iris.target, cv=10)
Out[12]:
array([ 1. , 0.93333333, 1. , 0.93333333, 0.93333333,
0.86666667, 0.93333333, 1. , 1. , 1. ])
cross_val_score是一个计算交叉验证值的函数
iris.data作为数据集, iris.target作为目标结果
cv=10表示使用10折交叉验证
同样可以使用 clf.fit(X,y)来生成, clsf.predict(x)进行函数预测
(3) 朴素贝叶斯
朴素贝叶斯是以贝叶斯定理为基础的多分类的分类器
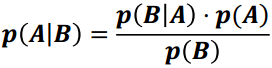
sklearn实现了三个朴素贝叶斯分类器

区别在于假设某一特征的所有属于某个类别的观测值符合特定分布, 分类问题的特征包括人的身高, 身高符合高斯分布, 这类问题适合高斯朴素贝叶斯
创建朴素贝叶斯
sklearn.naive_bayes.GaussianNB()
priors: 给定各个类别的先验概率, 空(按训练数据的实际情况进行统计), 给定先验概率(训练过程不能更改)
朴素贝叶斯的使用
import numpy as np
X = np.array([[-1,-1],[-2,-1],[-3,-2],[1,1],[2,1],[3,2]])
Y = np.array([1,1,1,2,2,2])
from sklearn.naive_bayes import GaussianNB
clf = GaussianNB(priors=None)
clf.fit(X,Y)
Out[18]: GaussianNB(priors=None)
clf.predict([[-0.8,-1]])
Out[19]: array([1])
朴素贝叶斯是典型的生成学习方法, 由训练数据学习联合概率分布, 并求得后验概率分布
朴素贝叶斯一般在小规模数据上的表现很好, 适合进行多分类任务
2.3 运动状态程序
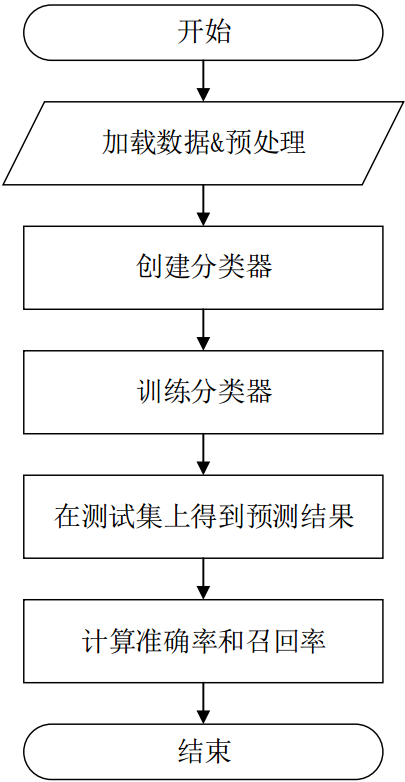
程序流程:
从特征文件和标签文件中将所有的数据加载到内存中, 并对缺失值进行简单的数据预处理
创建分类器, 使用训练集进行训练
测试集预测, 通过计算模型整体的准确率和召回率, 评估模型
1) 模块的导入
import pandas as pd
import numpy as np
from sklearn.preprocessing import Imputer
from sklearn.cross_validation import train_test_split
from sklearn.metrics import classification_report
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import GaussianNB
导入numpy库和pandas库
从sklearn库中导入预处理模块Imputer
导入自动生成训练集和测试集的模块train_test_split
导入预测结果评估模块classification_report
再导入三个算法: K近邻分类器KNeighborsClassifier, 决策树分类器DecisionTreeClassifier和高斯朴素贝叶斯函数GaussianNB
2) 数据导入函数
def load_datasets(feature_paths, label_paths):
feature = np.ndarray(shape=(0,41))
label = np.ndarray(shape=(0,1))
for file in feature_paths:
df = pd.read_table(file, delimiter=',', na_values='?', header=None)
imp = Imputer(missing_values='NaN', strategy='mean', axis=0)
imp.fit(df)
df = imp.transform(df)
feature = np.concatenate((feature, df))
for file in label_paths:
df = pd.read_table(file, header=None)
label = np.concatenate((label, df))
label = np.ravel(label)
return feature, label
编写数据导入函数,设置传入两个参数,分别是特征文件的列表feature_paths和标签文件的列表label_paths。
定义feature数组变量,列数量和特征维度一致为41;定义空的标签变量,列数量与标签维度一致为1。
使用pandas库的read_table函数读取一个特征文件的内容,其中指定分隔符为逗号、缺失值为问号且文件不包含表头行。
使用Imputer函数,通过设定strategy参数为‘ mean’,使用平均值对缺失数据进行补全。 fit()函数用于训练预处理器,transform()函数用于生成预处理结果。
将预处理后的数据加入feature,依次遍历完所有特征文件
遵循与处理特征文件相同的思想,我们首先使用pandas库的read_table函数读取一个标签文件的内容,其中指定分隔符为逗号且文件不包含表头行。
由于标签文件没有缺失值,所以直接将读取到的新数据加入label集合,依次遍历完所有标签文件,得到标签集合label。
最后函数将特征集合feature与标签集合label返回。
3) 主函数的编写
if __name__ == '__main__':
''' 数据路径 '''
featurePaths = ['A/A.feature','B/B.feature','C/C.feature','D/D.feature','E/E.feature']
labelPaths = ['A/A.label','B/B.label','C/C.label','D/D.label','E/E.label']
''' 读入数据 '''
x_train,y_train = load_datasets(featurePaths[:4],labelPaths[:4])
x_test,y_test = load_datasets(featurePaths[4:],labelPaths[4:])
x_train, x_, y_train, y_ = train_test_split(x_train, y_train, test_size = 0.0)
print('Start training knn')
knn = KNeighborsClassifier().fit(x_train, y_train)
print('Training done')
answer_knn = knn.predict(x_test)
print('Prediction done')
print('Start training DT')
dt = DecisionTreeClassifier().fit(x_train, y_train)
print('Training done')
answer_dt = dt.predict(x_test)
print('Prediction done')
print('Start training Bayes')
gnb = GaussianNB().fit(x_train, y_train)
print('Training done')
answer_gnb = gnb.predict(x_test)
print('Prediction done')
print('
The classification report for knn:')
print(classification_report(y_test, answer_knn))
print('
The classification report for DT:')
print(classification_report(y_test, answer_dt))
print('
The classification report for Bayes:')
print(classification_report(y_test, answer_gnb))
设置数据路径feature_paths和label_paths。
使用python的分片方法,将数据路径中的前4个值作为训练集,并作为参数传入load_dataset()函数中,得到训练集合的特征x_train,训练集的标签y_train。
将最后一个值对应的数据作为测试集,送入load_dataset()函数中,得到测试集合的特征x_test,测试集的标签y_test。
使用train_test_split()函数,通过设置测试集比例test_size为0,将数据随机打乱,便于后续分类器的初始化和训练。
使用默认参数创建K近邻分类器,并将训练集x_train和y_train送入fit()函数进行训练,训练后的分类器保存到变量knn中。
使用测试集x_test,进行分类器预测,得到分类结果answer_knn。
使用默认参数创建决策树分类器dt,并将训练集x_train和y_train送入fit()函数进行训练。训练后的分类器保存到变量dt中。
使用测试集x_test,进行分类器预测,得到分类结果answer_dt。
使用默认参数创建贝叶斯分类器,并将训练集x_train和y_train送入fit()函数进行训练。训练后的分类器保存到变量gnb中。
使用测试集x_test,进行分类器预测,得到分类结果answer_gnb。
使用classification_report函数对分类结果,从精确率precision、召回率recall、 f1值f1-score和支持度support四个维度进行衡量。
分别对三个分类器的分类结果进行输出
3 回归
3.1 线性回归
线性回归(Linear Regression)是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。
线性回归利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模。 这种函数是一个或多个称为回归系数的模型参数的线性组合。只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归