基础知识
1 js:JavaScript缩写
json:JavaScript的一种数据格式
2 浏览器的原理:把 html+css+js 下载到本地然后再进行渲染。即看到网页这个过程,实际上是浏览器把代码下载下来,然后浏览器来解释这个代码,变成界面的过程。
3 查看网页源代码:就是别人服务器发送到浏览器的原封不动的代码。这个代码没有被浏览器执行js。
(F12)检查元素:检查元素时,在源代码中找不到的代码,是在浏览器执行js动态生成的。通过检查元素看到的就是最终的html代码。即:源代码 + 网页js渲染
数据的存放
网页的数据有两种存放方法:①存在“网页源代码”里。
②存在后端(数据库)里。
注意:存在“网页源代码”里的数据也可能存在数据库里。
获取网页的代码
① 使用requests.get()
使用该方法请求网页,得到的是网页源代码。因为requests请求库不能执行js,所以js无法渲染。如果网页的数据存在“网页源代码”里,那么使用该方法能获取到这些数据;如果网页的数据存在后端(数据库)里,那么使用该方法就不能获取这些数据了。因为后端的数据需要浏览器执行js才能动态生成。
② 使用selenium自动化技术
爬虫中使用selenium主要是为了解决requests无法执行javaScript代码的问题。selenium本质上是通过驱动浏览器,完成模拟浏览器的操作,比如跳转、输入、点击、下拉等...进而拿到网页渲染之后的结果。如果你的网站需要发送ajax请求,异步获取数据渲染到页面上,就需要使用js发送请求。selenium可以模拟浏览器执行js。使用selenium模拟浏览器,得到的是最终的html代码,即:源代码 + 网页js渲染。但是它也有缺点,因为使用selenium本质上是驱动浏览器对目标站点发送请求,那浏览器在访问目标站点的时候,需要把静态资源都加载完毕。html、css、js这些文件都要等待它们加载完成,导致速度很慢。所以我们一般用它来做登录验证。不管网页的数据存在“网页源代码”里,还是存在数据库里,使用该方法能获取到所有的数据。
爬虫的思路:
查看网页源代码里是否有我们需要的数据。
如果有,直接使用requests.get()方法获取。当使用该方法获取数据较困难时,也可以查看http协议的接口是否有数据,有的话就可以使用(1)或者(2)的方法。
如果没有,有两种方法:
(1) 调用接口:查看数据所在的http协议接口,然后获取该接口的url,再使用第requests.get种方法进行请求。
(2) 使用selenium自动化技术。遇到加密的接口时,使用该方法就能绕过加密。
智能等待
使用selenium模拟浏览器有时候会报一个错误:使用xpath找不到需要定位的数据元素。但该数据元素的路径是正确的,出现这种问题的原因是没有设置等待时间。因为浏览器执行js是需要时间的,只有等到网页js渲染完成后,数据才能加载在最终的html代码里,如果没有等到数据加载到最终的html代码里就获取页面代码,自然就找不到数据元素了。因此我们需要设置等待时间,让网页js渲染完成后再对数据元素进行定位。
selenium有三种等待的方式
①time.sleep(等待时间)
这种方法是选择一个固定的时间进行等待,单位是秒。使用时需要引入time模块。 import time
②implicitly_wait(等待时间)
这种方法是判断在设定的时间内页面是否加载完成,如果加载完成那么就进行下一步,如果没加载完成就会报超时加载的错误。使用时需要引入time模块。 import time
③推荐使用:WebDriverWait(driver,时间)
from selenium.webdriver.support.ui import WebDriverWait WebDriverWait(driver, 10).until(lambda driver: driver.find_element_by_xpath('指定元素路径')) # driver是操作 webdriver.Chrome()的句柄。 # 在10秒内每隔500毫秒扫描1次页面变化,当出现指定的元素后就结束等待,进行下一步。 # until代表一直等待,直到某元素可见为止。
selenium操作对象的text方法
1 使用 driver.find_element_by_xpath("xpath路径") 定位到单个元素后,直接使用text方法,即可获取元素的文本。即 driver.find_element_by_xpath("xpath路径").text
2 使用 driver.find_elements_by_xpath("xpath路径") 定位到一组元素后,先使用for循环把每个元素遍历出来,遍历出来后再对单个元素使用text方法获取单个元素的文本。
如何查找一组元素的xpath路径呢?任意选择几个同组元素的xpath路径来进行对比,找到这几个路径中不一样的地方,然后提取公共部分就是这组元素的xpath路径。通过这组元素的xpath路径就能够定位到这组的所有元素。
1 yizuyuansu = driver.find_elements_by_xpath("一组元素的xpath路径") 2 for yigeyuansu in yizuyuansu: 3 print(yigeyuansu.text)
一、抓取深圳证券交易所的信息
目标:打开 http://www.szse.cn/market/stock/indicator/index.html ,出现如下页面。我们的目标是要获取深圳市场、深市主板、中小企业板、创业板下的数据。
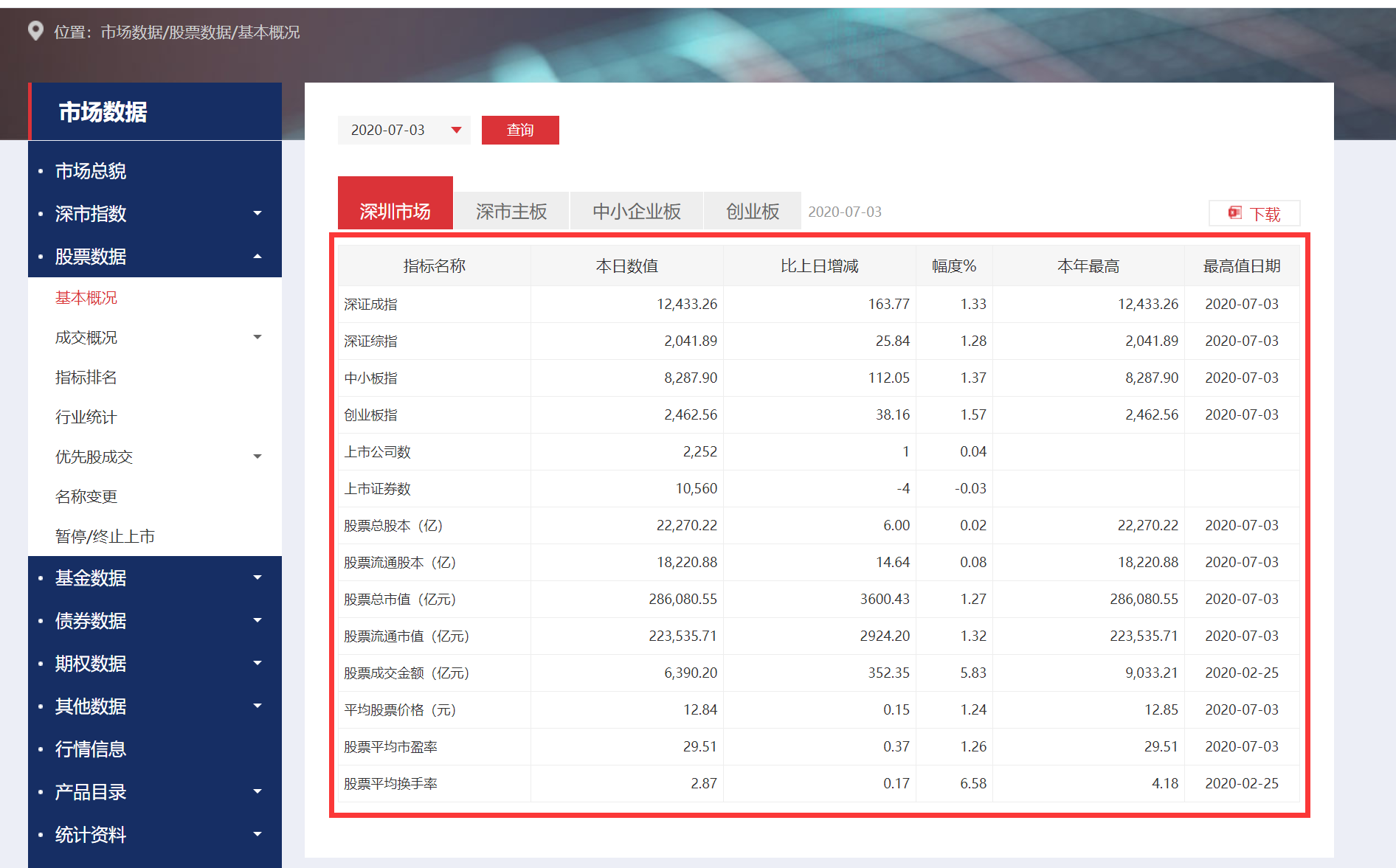
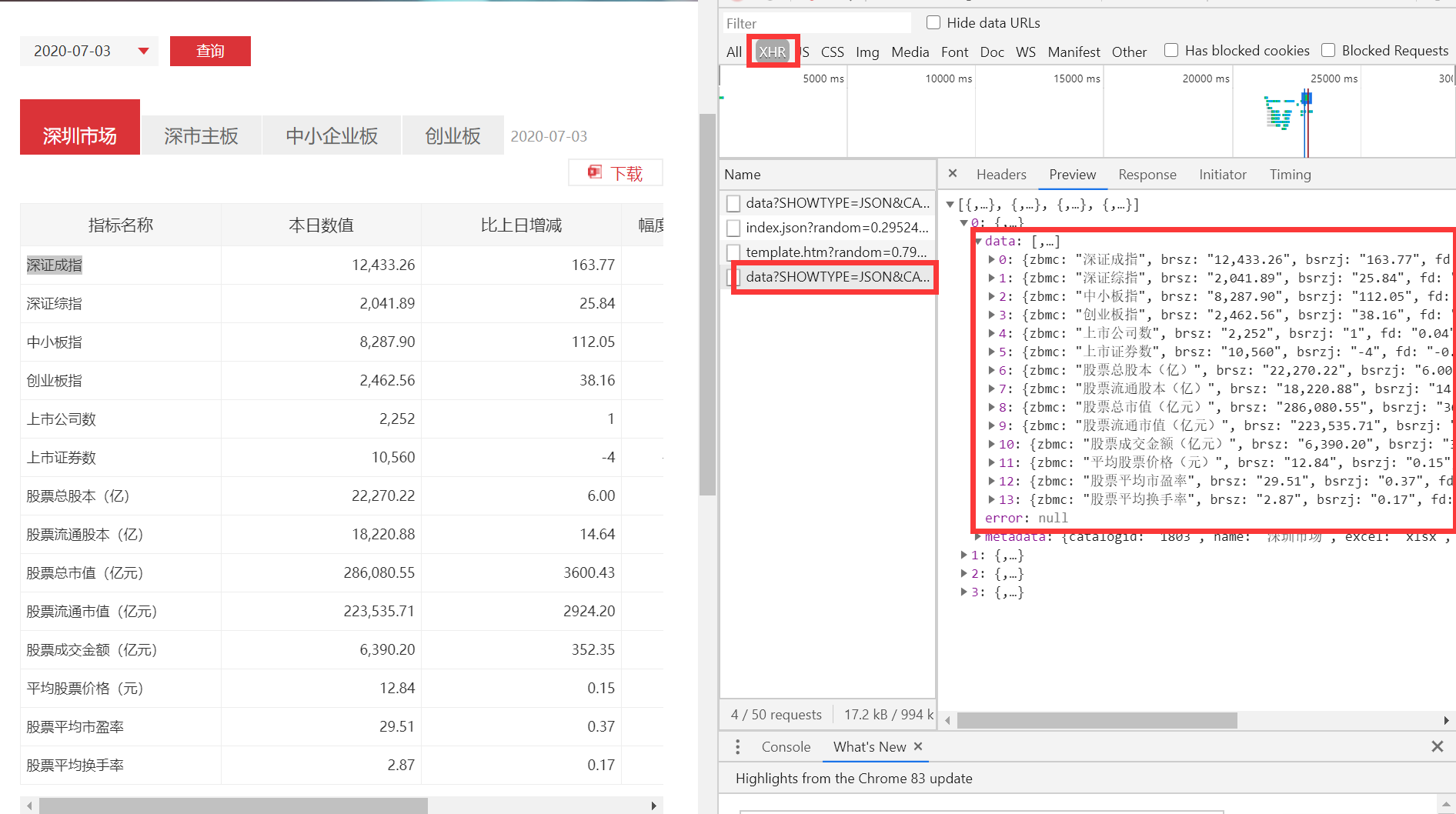
分析:查找网页源代码,发现并没有我们需要的数据。而在接口中发现了我们需要的数据。所以该网站把我们需要的数据存在接口里。
获取数据的方法:①通过接口 ②使用xpath获取我们需要的数据所在的元素后,使用selinum的text方法来获取这些元素的文本。
1 def get_informations_by_interface(interface_shenzhenshichang_url,interface_shenshizhuban_url,interface_zhongxiaoqiyeban_url,interface_chuangyeban_url): 2 import requests 3 4 #深圳市场 5 shenzhenshichang = requests.get(interface_shenzhenshichang_url) 6 # requests中内置一个JSON解码器,帮助处理JSON数据。通过json()方法可以把返回对象为json格式的字符串转化为字典。 7 shenzhenshichang = shenzhenshichang.json() 8 shenzhenshichang = shenzhenshichang[0]['data'] 9 for data in shenzhenshichang: 10 print('===================') 11 print('指标名称:' + data['zbmc']) 12 print('本日数值:' + data['brsz']) 13 print('比上日增减:' + data['bsrzj']) 14 print('幅度%:' + data['fd']) 15 print('本年最高:' + data['bnzg']) 16 print('最高值日期:' + data['zgzrq']) 17 18 #深市主板 19 shenshizhuban = requests.get(interface_shenshizhuban_url) 20 shenshizhuban = shenshizhuban.json() 21 shenshizhuban = shenshizhuban[1]['data'] 22 for data in shenshizhuban: 23 print('===========================') 24 print('指标名称:' + data['indicator']) 25 print('本日数值:' + data['today']) 26 print('比上日增减:' + data['increase']) 27 print('本年最高:' + data['highofyear']) 28 print('最高值日期:' + data['dateofhigh']) 29 30 #中小企业板 31 zhongxiaoqiyeban = requests.get(interface_zhongxiaoqiyeban_url) 32 zhongxiaoqiyeban = zhongxiaoqiyeban.json() 33 zhongxiaoqiyeban = zhongxiaoqiyeban[2]['data'] 34 for data in zhongxiaoqiyeban: 35 print('===========================') 36 print('指标名称:' + data['indicator']) 37 print('本日数值:' + data['today']) 38 print('比上日增减:' + data['increase']) 39 print('本年最高:' + data['highofyear']) 40 print('最高值日期:' + data['dateofhigh']) 41 42 #创业板 43 chuangyeban = requests.get(interface_chuangyeban_url) 44 chuangyeban = chuangyeban.json() 45 chuangyeban = chuangyeban[3]['data'] 46 for data in chuangyeban: 47 print('===========================') 48 print('指标名称:' + data['indicator']) 49 print('本日数值:' + data['today']) 50 print('比上日增减:' + data['increase']) 51 print('本年最高:' + data['highofyear']) 52 print('最高值日期:' + data['dateofhigh']) 53 54 def get_informations_by_selenium(url): 55 from selenium import webdriver 56 import requests 57 from selenium.webdriver.support.ui import WebDriverWait 58 import time 59 60 driver = webdriver.Chrome() 61 driver.maximize_window() 62 driver.get(url) 63 64 WebDriverWait(driver, 10).until(lambda driver: driver.find_element_by_xpath('//*[@id="1803_nav1"]')) 65 shenzhenshichang_text = driver.find_element_by_xpath('//*[@id="1803_nav1"]').text 66 print(shenzhenshichang_text) 67 print('=================================================================================') 68 69 # 此处我使用time.sleep(1)等待页面加载,运行时,一切正常。后做优化,想使用WebDriverWait 代替time.sleep,但是会时不时出现click失效的情况。 70 # 出现问题原因:html文档加载出来了,但是对应的图标还没加载出来,所以当时点击无效 71 # 解决方法:在WebDriverWait 语句后面,适当加一点的休息时间,即time.sleep 72 driver.find_element_by_xpath('//*[@id="1803_tabs"]/div[1]/div[1]/ul/li[2]/a').click() 73 WebDriverWait(driver, 10).until(lambda driver: driver.find_element_by_xpath('//*[@id="1803_nav2"]')) 74 time.sleep(1) 75 shenshizhuban_text = driver.find_element_by_xpath('//*[@id="1803_nav2"]').text 76 print(shenshizhuban_text) 77 print('==================================================================================') 78 79 driver.find_element_by_xpath('//*[@id="1803_tabs"]/div[1]/div[1]/ul/li[3]/a').click() 80 WebDriverWait(driver, 10).until(lambda driver: driver.find_element_by_xpath('//*[@id="1803_nav3"]')) 81 time.sleep(1) 82 zhongxiaoqiyeban_text = driver.find_element_by_xpath('//*[@id="1803_nav3"]').text 83 print(zhongxiaoqiyeban_text) 84 print('===================================================================================') 85 86 driver.find_element_by_xpath('//*[@id="1803_tabs"]/div[1]/div[1]/ul/li[4]/a').click() 87 WebDriverWait(driver, 10).until(lambda driver: driver.find_element_by_xpath('//*[@id="1803_nav4"]')) 88 time.sleep(1) 89 chuangyeban_text = driver.find_element_by_xpath('//*[@id="1803_nav4"]').text 90 print(chuangyeban_text) 91 92 93 94 if __name__ == '__main__': 95 interface_shenzhenshichang_url = 'http://www.szse.cn/api/report/ShowReport/data?SHOWTYPE=JSON&CATALOGID=1803&loading=first&random=0.049964627342305334' 96 interface_shenshizhuban_url = 'http://www.szse.cn/api/report/ShowReport/data?SHOWTYPE=JSON&CATALOGID=1803&TABKEY=tab2&txtQueryDate=2020-07-06&random=0.8286262855952344' 97 interface_zhongxiaoqiyeban_url = 'http://www.szse.cn/api/report/ShowReport/data?SHOWTYPE=JSON&CATALOGID=1803&TABKEY=tab3&txtQueryDate=2020-07-06&random=0.5038392303025343' 98 interface_chuangyeban_url = 'http://www.szse.cn/api/report/ShowReport/data?SHOWTYPE=JSON&CATALOGID=1803&TABKEY=tab4&txtQueryDate=2020-07-06&random=0.9404614845941501' 99 url = 'http://www.szse.cn/market/stock/indicator/index.html' 100 101 get_informations_by_interface(interface_shenzhenshichang_url,interface_shenshizhuban_url,interface_zhongxiaoqiyeban_url,interface_chuangyeban_url) 102 get_informations_by_selenium(url)
二、抓取QQ音乐歌词和歌曲信息
目标:打开 https://y.qq.com/n/yqq/song/004dcSDN0czi28.html ,出现如下页面。我们的目标是要获取这首歌的歌词和歌曲信息。
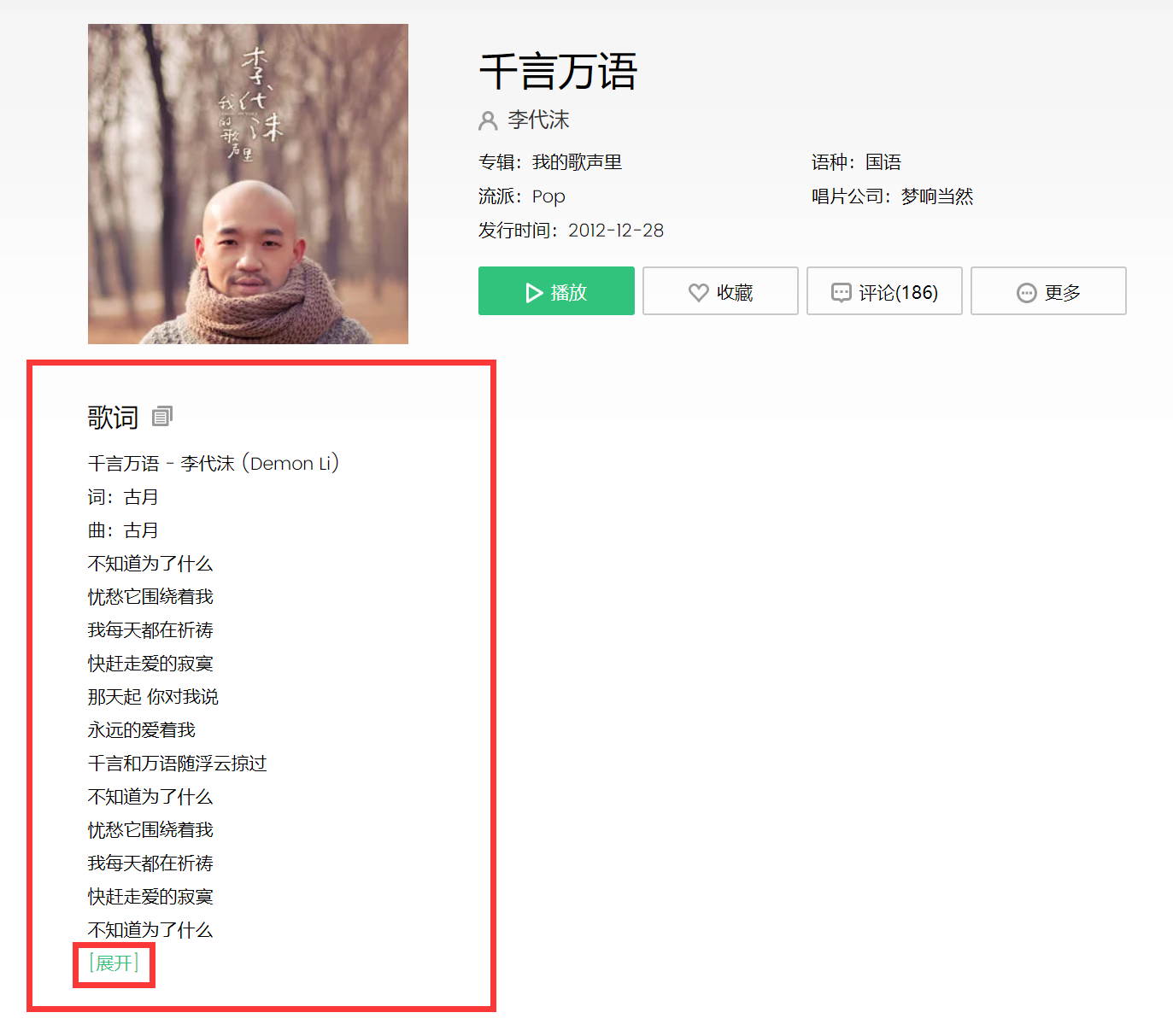
分析:查找网页源代码,发现并没有歌词。而在一个接口中发现了歌词。因为歌曲信息在源代码中很难匹配出来,接口中又存在歌曲信息,所以选择使用接口获取歌曲信息。
获取歌词的方法:①通过接口 ②使用xpath找到歌词元素后,使用selenium的text方法来获取歌词元素的文本。
注意:使用selenium时,打开页面后,我们需要先点击图片上的“展开”,把歌词在页面中显示完整,此时使用text方法来获取歌词元素的文本才是完整的歌词。如果不点击“展开”,那么使用text方法来获取歌词元素的文本只有页面中显示的那部分不完整的歌词。
1 def get_qqmusic_lyrics_by_selenium(url): 2 from selenium import webdriver 3 import requests 4 from selenium.webdriver.support.ui import WebDriverWait 5 import time 6 7 driver = webdriver.Chrome() 8 driver.maximize_window() 9 driver.get(url) 10 11 # 此处我使用time.sleep(1)等待页面加载,运行时,一切正常。后做优化,想使用WebDriverWait 代替time.sleep,但是会时不时出现click失效的情况。 12 # 出现问题原因:html文档加载出来了,但是对应的图标还没加载出来,所以当时点击无效 13 # 解决方法:在WebDriverWait 语句后面,适当加一点的休息时间,即time.sleep 14 WebDriverWait(driver, 10).until(lambda driver: driver.find_element_by_xpath('//a[@class="c_tx_highlight js_open_lyric"]')) 15 time.sleep(2) 16 17 # 点击“展开”歌词 18 driver.find_element_by_xpath('/html/body/div[2]/div[2]/div[1]/div[1]/div[2]/a').click() 19 WebDriverWait(driver, 10).until(lambda driver: driver.find_element_by_xpath('//*[@id="lrc_content"]')) 20 21 # 使用xpath定位到歌词后,获取歌词文本 22 lyric_text = driver.find_element_by_xpath('//*[@id="lrc_content"]').text 23 print(lyric_text) 24 25 def get_qqmusic_informations_by_interface(informations_interface_url): 26 import requests 27 response = requests.get(information_interface_url) 28 29 # requests中内置一个JSON解码器,帮助处理JSON数据。通过json()方法可以把返回对象为json格式的字符串转化为字典。 30 response = response.json() 31 32 print(response['songinfo']['data']['info']['genre']['title'] + ':' + response['songinfo']['data']['info']['genre']['content'][0]['value']) 33 print(response['songinfo']['data']['info']['company']['title'] + ':' + response['songinfo']['data']['info']['company']['content'][0]['value']) 34 print(response['songinfo']['data']['info']['lan']['title'] + ':' + response['songinfo']['data']['info']['lan']['content'][0]['value']) 35 print(response['songinfo']['data']['info']['pub_time']['title'] + ':' + response['songinfo']['data']['info']['pub_time']['content'][0]['value']) 36 37 def get_qqmusic_lyrics_by_interface(lyrics_interface_url): 38 import requests 39 import html 40 # 我第一次没加请求头就发送请求,结果请求不成功,加了这个请求i头后请求才成功。因此有的接口的请求需要加请求头。 41 headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36', 42 'referer': 'https://y.qq.com/n/yqq/song/004dcSDN0czi28.html'} 43 response = requests.get(lyrics_interface_url,headers=headers) 44 45 # requests中内置一个JSON解码器,帮助处理JSON数据。通过json()方法可以把返回对象为json格式的字符串转化为字典。 46 response = response.json() 47 48 lyrics = response['lyric'] 49 # html实体反转义字符。 50 lyrics = html.unescape(lyrics) 51 print(lyrics) 52 53 if __name__ == '__main__': 54 qqmusic_url = '歌曲链接' 55 information_interface_url = '歌曲信息的接口链接' 56 lyrics_interface_url = '歌词的接口链接' 57 58 get_qqmusic_lyrics_by_selenium(qqmusic_url) 59 print('======================================') 60 get_qqmusic_informations_by_interface(information_interface_url) 61 print('======================================') 62 get_qqmusic_lyrics_by_interface(lyrics_interface_url)
三、抓取京东大地瓜价格和名字
目标:打开 https://search.jd.com/Search?keyword=%E5%A4%A7%E5%9C%B0%E7%93%9C&enc=utf-8&wq=%E5%A4%A7%E5%9C%B0%E7%93%9C&pvid=1ea2204782724a3bbbd3df7ef5d74b93 ,出现如 下页面,我们的目标是要获取每页中的60个商品的价格和名字。
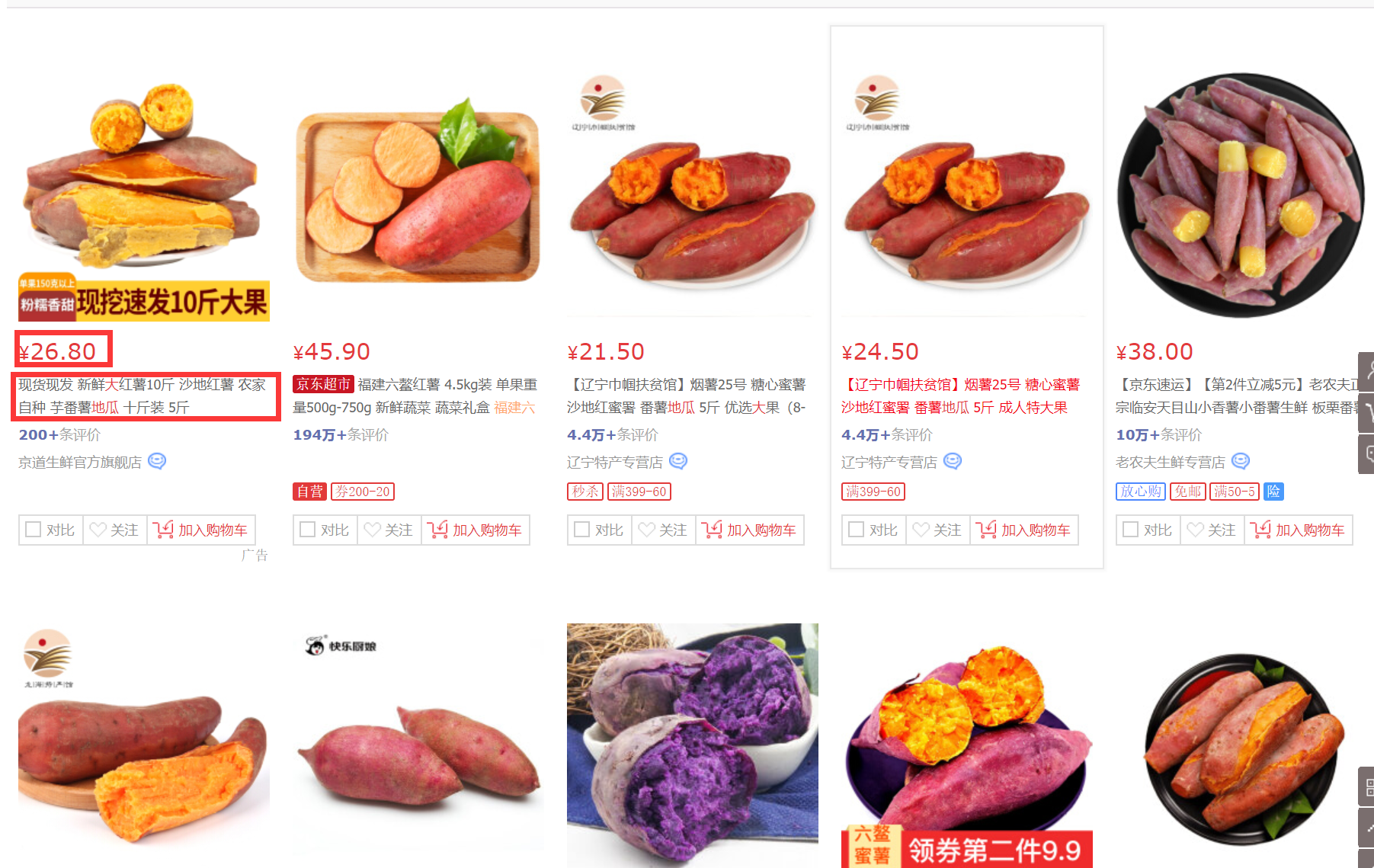
分析: 查找网页源代码,发现只存在30个商品元素。而在一个接口中,找到了剩下的30个商品元素。
获取一页商品价格的方法:①先从源码中取出30个商品的价格和名字,再通过接口取出剩下的30个商品的价格和名字。 ②使用xpath找到一页中的60个价格元素后,使用selenium的text方法来获取这60个价格元素的文本。
对于前五页,只需要一个for循环对url进行循环即可解决。
使用第②种方法的注意事项:
1 因为打开链接后页面源码默认存在30个商品元素,也就是说如果我们不把页面滚动条拖到底部,那么我们只能获取到30个商品价格元素。当我们把页面滚动条拖到最底部后,页面源码中就有60个商品价格元素了。可以通过js代码实现拖动页面滚动条。
#1 将普通页面滚动条拖到底部,如果想把滚动条拖到顶部,只需要把10000改为0即可 js="var q=document.documentElement.scrollTop=10000" driver.execute_script(js) #2 将内嵌窗口(例如第一次进入游戏中需要阅读的游戏须知窗口)的页面滚动条拖到底部,需要先找到内嵌窗口元素的id js="var q=document.getElementById('id').scrollTop=10000" driver.execute_script(js)
2 因为我们要的是页面上的60个价格,即一组价格数据。因此使用 driver.find_elements_by_xpath 来查找这组价格元素,而不是 driver.find_element_by_xpath 。
先任选一个价格元素的xpath路径(比如第一个://*[@id="J_goodsList"]/ul/li[1]/div/div[2]/strong/i ),再任选一个价格元素的xpath路径(比如第二个://*[@id="J_goodsList"]/ul/li[2]/div/div[2]/strong/i ),通过对比这两个xpath路径后发现,它们的不同是路径中标黄的li[1]和li[2]部分,因此我们把路径中标黄的li后面的[1]或者[2]去掉后,得到的就是这组价格元素的路径。即://*[@id="J_goodsList"]/ul/li/div/div[2]/strong/i 。使用xpath定位到这组价格元素后,通过for循环把60个价格元素遍历出来,然后读取每个价格元素的文本就是我们需要的价格数据。60个商品的名字同理。
1 #该函数通过selenium获取京东大地瓜商品第一页的商品价格,一共有60个商品。 2 def get_informations_by_selenium(): 3 from selenium import webdriver 4 import requests 5 from selenium.webdriver.support.ui import WebDriverWait 6 import time 7 8 driver = webdriver.Chrome() 9 driver.maximize_window() 10 driver.get( 11 'https://search.jd.com/Search?keyword=%E5%A4%A7%E5%9C%B0%E7%93%9C&qrst=1&wq=%E5%A4%A7%E5%9C%B0%E7%93%9C&stock=1&page=1&s=1&click=0') 12 WebDriverWait(driver, 10).until( 13 lambda driver: driver.find_element_by_xpath('//*[@id="J_goodsList"]/ul/li/div/div[2]/strong/i')) 14 15 # 将页面滚动条拖到底部,可以作为固定写法。 16 js = "var q=document.documentElement.scrollTop=10000" 17 driver.execute_script(js) 18 time.sleep(3) 19 20 price_elements = driver.find_elements_by_xpath('//*[@id="J_goodsList"]/ul/li/div/div[2]/strong/i') 21 for price_element in price_elements: 22 print(price_element.text) 23 print(len(price_elements)) 24 25 26 #该函数通过网页源代码和接口共同获取京东大地瓜商品前5页的商品价格和名称,每页都有60个商品。 27 '''思路: 28 前30个商品的数据在网页源代码,我们可以请求网页源代码后使用xpath获取。把前30个商品的价格和名字存到一个价格列表和一个名字列表里。 29 1 获取的是30个商品的xpath路径。 30 做法是:①对比n个商品的xpath价格路径,得到30个商品的xpath价格路径; 31 ②对比n个商品的xpath名字路径,得到30个商品的xpath名字路径。 32 ③对比30个商品的xpath价格路径和30个商品的xpath名字路径,得到30个商品的路径。 33 34 比如这是第一个商品的xpath价格路径://*[@id="J_goodsList"]/ul/li[1]/div/div[2]/strong/i 35 这是第二个商品的xpath价格路径://*[@id="J_goodsList"]/ul/li[2]/div/div[2]/strong/i 36 所以30个商品的xpath价格路径是://*[@id="J_goodsList"]/ul//li/div/div[2]/strong/i 37 38 比如这是第一个商品的xpath名字路径://*[@id="J_goodsList"]/ul/li[1]/div/div[3]/a/em 39 这是第二个商品的xpath名字路径://*[@id="J_goodsList"]/ul/li[2]/div/div[3]/a/em 40 所以30个商品的xpath名字路径是://*[@id="J_goodsList"]/ul//li/div/div[3]/a/em 41 42 比如这是30个商品的xpath价格路径://*[@id="J_goodsList"]/ul//li/div/div[2]/strong/i 43 这是30个商品的xpath名字路径://*[@id="J_goodsList"]/ul//li/div/div[3]/a/em 44 所以30个商品的路径是://*[@id="J_goodsList"]/ul//li/div 45 46 2 得到30个商品的路径后,把每个商品遍历出来。并且同时获取该商品的价格和名字,使得获取的一个商品的价格和名字一一对应。 47 3 遍历取出每一个商品的价格和名字后,添加到价格列表和名字列表。因为列表是有序的,价格和名字同时添加能一一对应上。 48 注:因为获取到的每一个商品名字,都夹杂着空格换行等。所以需要使用''.join(seq)的方法把获取到的每一个格式为字符串的名字进行重新拼接。拼接后再添加到名字列表里。 49 ''' 50 51 '''思路: 52 后30个商品的数据在一个get接口里。我们需要获取这个接口的url,然后发送请求,在返回的代码中找出后30个商品的数据。 53 1 观察第一页的get接口的url:https://search.jd.com/s_new.php?keyword=%E5%A4%A7%E5%9C%B0%E7%93%9C&qrst=1&wq=%E5%A4%A7%E5%9C%B0%E7%93%9C&stock=1&page=2&s=26&scrolling=y&log_id=1594065480723.2392&tpl=1_M&isList=0&show_items=70420536815,7713680,57318822454,30055576938,57318822453,30872758383,69922945312,53766745353,60888146009,48104226309,51773251563,29814344646,50404645676,41600013322,51709357916,67097609456,65925516601,64143955809,65514287148,53132376874,65509103991,59878621907,52079997901,57681653424,69514509700,57719320185,71052393509,69896760089,66685136093,60911474440 54 再观察第一页的网页源代码的url:https://search.jd.com/Search?keyword=%E5%A4%A7%E5%9C%B0%E7%93%9C&qrst=1&wq=%E5%A4%A7%E5%9C%B0%E7%93%9C&stock=1&page=1&s=1&click=0 55 发现第一页的网页源代码的url中存在“page=1”,get接口的url中存在“page=2”, 56 此时我们再去观察第二页,发现网页源代码的url中存在”page=3“,get接口的url中存在“page=4”, 57 第三页的网页源代码的url中存在“page=5”,get接口的url中存在“page=6”. 58 此时我们发现一个规律:第n页的网页源代码的page等于2n-1,get接口的url的page等于2n。 59 60 2 观察每一页的get接口的url,发现“items=”往后的部分都有30个数字,因此我们知道这30个数字与后30个商品一一对应。 61 我们只需要找到每一页的后30个商品对应的30个数字,再进行拼接就能得到每一页的get接口的url。 62 我们发现,后30个商品对应的30个数字都在网页源代码里,因此我们可以先获取网页源代码,然后使用正则表达式把后30个商品对应的数字匹配出来。 63 我们发现匹配的结果里每个数字都有3个重复的,即匹配到90个数字。此时我们可以通过集合的去重功能匹配出我们需要的30个数字。 64 得到30个数字后,我们再进行字符串拼接,就能得到get接口的url。注意每一页get接口的url中page对应的规则是2n。 65 66 3 get接口的url拼接成功后,发送一个get请求,得到的代码里就包括了剩下的30个商品数据。 67 注意:发送请求时需要携带请求头,不然会触发京东页面登陆机制。 68 因为后30个商品的标签和在源码里前30个商品的标签是差不多的,因此我们可以仿照前30个商品的xpath路径,即//li/div。 69 70 4 获取后30个商品的标签后,进行for循环遍历,每次遍历都把价格和名字一一对应地添加到价格列表和名字列表里。并且使用''.join(seq)把后30个商品的名字处理好。 71 ''' 72 73 def get_informatiion_by_interface(): 74 import requests 75 from lxml import etree 76 import re 77 for page in range(1,10,2): 78 print('-------------------------------------------------------------------------------------------------------------------------') 79 # url 是每一页网页源代码的url。 80 url = 'https://search.jd.com/s_new.php?keyword=%E5%A4%A7%E5%9C%B0%E7%93%9C&qrst=1&wq=%E5%A4%A7%E5%9C%B0%E7%93%9C&stock=1&page=' + str(page) + '&s=1&click=0' 81 82 # 请求的header头部增加浏览器的cookie信息的目的是为了使得我们抓取到的商品排序和我们用浏览器打开页面后商品的排序是一样的 83 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36', 84 'referer': 'https://search.jd.com/Search?keyword=%E5%A4%A7%E5%9C%B0%E7%93%9C&qrst=1&wq=%E5%A4%A7%E5%9C%B0%E7%93%9C&stock=1&page=1&s=1&click=0', 85 'cookie': '3AB9D23F7A4B3C9B=2UDPAMUVVAOX4434BC7I2ZLURIPLLIIUQP4YPLIOTU664VIP7KSLA6MAK6OQKGJHRZZDQ3DYSFK5XDBNHFCU6KJB6M; __jda=122270672.15933569519401053893576.1593356952.1593356952.1593356952.1; __jdv=122270672|direct|-|none|-|1593356951941; __jdc=122270672; __jdu=15933569519401053893576; shshshfp=570e85b8b983f561323d6ce789eb70fd; shshshfpa=ca3ed469-1333-824a-e055-0077f782a98a-1593356953; shshshfpb=vLxmwxHcieTu9rJHld9YGrQ%3D%3D; areaId=20; ipLoc-djd=20-1818-1824-0; __jdb=122270672.3.15933569519401053893576|1.1593356952; shshshsID=b47f5b4faadb933f4f6c6bc34f7c587a_3_1593357253227'} 86 87 price_list = [] 88 name_list = [] 89 html_befor30 = requests.get(url, headers=headers) 90 html_befor30 = etree.HTML(html_befor30.text) 91 shangpins_befor30 = html_befor30.xpath('//*[@id="J_goodsList"]/ul//li/div') 92 for shangpin in shangpins_befor30: 93 price = shangpin.xpath('div[2]/strong/i//text()') 94 name = shangpin.xpath('div[3]/a/em//text()') 95 price_list.append(price[0]) 96 name_list.append(''.join(name)) 97 98 #后30个数据信息 99 # 对每一页的网页源代码进行请求,目的是为了使用正则表达式匹配后30个商品对应的30个数字。 100 html_re = requests.get(url,headers=headers) 101 pattern = 'data-sku="(d+)' 102 id_number = re.findall(pattern,html_re.text) 103 # 匹配到数字后使用字符串拼接的方式构造一个完整的get接口的url。使用set方法把匹配到重复的数字去重。 104 id_number = ','.join(set(id_number)) 105 urls = 'https://search.jd.com/s_new.php?keyword=%E5%A4%A7%E5%9C%B0%E7%93%9C&qrst=1&wq=%E5%A4%A7%E5%9C%B0%E7%93%9C&stock=1&page=' + str(page+1) + '&s=31&scrolling=y&log_id=1593366515600.6909&tpl=1_M&isList=0&show_items=' + id_number 106 107 #请求时必须要加上headers头,不然会触发登录机制。 108 html_later30 = requests.get(urls,headers=headers) 109 html_later30 = etree.HTML(html_later30.text) 110 shangpins_later30 = html_later30.xpath('//li/div') 111 for shangpin in shangpins_later30: 112 price = shangpin.xpath('div[2]/strong/i//text()') 113 name = shangpin.xpath('div[3]/a/em//text()') 114 price_list.append(price[0]) 115 name_list.append(''.join(name)) 116 117 #打印60个数据信息 118 for (price,name) in zip(price_list,name_list): 119 print(price,name) 120 121 if __name__ == '__main__': 122 get_informatiion_by_interface() 123 get_informations_by_selenium()