安装apscheduler 模块
pip install apscheduler pip install django-apscheduler
将 django-apscheduler 加到项目中settings的INSTALLED_APPS中
INSTALLED_APPS = [ .... 'django_apscheduler', ]
执行:
# python manage.py migrate 没有其他表结构不必运行 python manage.py makemigrations
会创建两张表:django_apscheduler_djangojob/django_apscheduler_djangojobexecution
通过进入后台管理能方便管理定时任务。
在Django工程目录下的urls.py文件中,或者说主urls.py中引入如下内容
from apscheduler.schedulers.background import BackgroundScheduler
from django_apscheduler.jobstores import DjangoJobStore, register_events, register_job
scheduler = BackgroundScheduler()
scheduler.add_jobstore(DjangoJobStore(), "default")
# 时间间隔3秒钟打印一次当前的时间
@register_job(scheduler, "interval", seconds=3, id='test_job')
def test_job():
print("我是apscheduler任务")
# per-execution monitoring, call register_events on your scheduler
register_events(scheduler)
scheduler.start()
print("Scheduler started!")
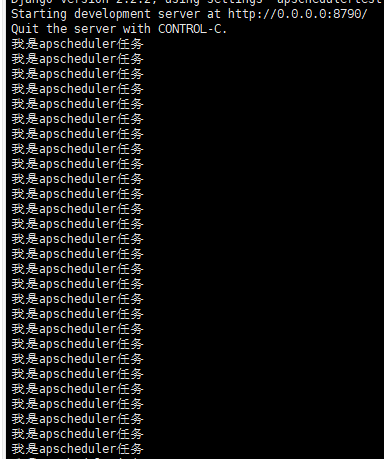
运行结果如下:
APScheduler中两种调度器的区别及使用过程中要注意的问题
APScheduler中有很多种不同类型的调度器,BlockingScheduler与BackgroundScheduler是其中最常用的两种调度器。区别主要在于BlockingScheduler会阻塞主线程的运行,而BackgroundScheduler不会阻塞。所以,我们在不同的情况下,选择不同的调度器:
BlockingScheduler: 调用start函数后会阻塞当前线程。当调度器是你应用中唯一要运行的东西时(如上例)使用。BackgroundScheduler: 调用start后主线程不会阻塞。当你不运行任何其他框架时使用,并希望调度器在你应用的后台执行。
BlockingScheduler的真实例子
from apscheduler.schedulers.blocking import BlockingScheduler
import time
def job():
print('job 3s')
if __name__=='__main__':
sched = BlockingScheduler(timezone='MST')
sched.add_job(job, 'interval', id='3_second_job', seconds=3)
sched.start()
while(True):
print('main 1s')
time.sleep(1)
运行结果:
job 3s
job 3s
job 3s
job 3s
可见,BlockingScheduler调用start函数后会阻塞当前线程,导致主程序中while循环不会被执行到。
BackgroundScheduler的真实例子
from apscheduler.schedulers.background import BackgroundScheduler
import time
def job():
print('job 3s')
if __name__=='__main__':
sched = BackgroundScheduler(timezone='MST')
sched.add_job(job, 'interval', id='3_second_job', seconds=3)
sched.start()
while(True):
print('main 1s')
time.sleep(1)
运行结果:
main 1s
main 1s
main 1s
job 3s
main 1s
main 1s
main 1s
job 3s
可见,BackgroundScheduler调用start函数后并不会阻塞当前线程,所以可以继续执行主程序中while循环的逻辑。
通过这个输出,我们也可以发现,调用start函数后,job()并不会立即开始执行。而是等待3s后,才会被调度执行。
如何让job在start()后就开始运行
如何才能让调度器调用start函数后,job()就立即开始执行呢?
其实APScheduler并没有提供很好的方法来解决这个问题,但有一种最简单的方式,就是在调度器start之前,就运行一次job(),如下
from apscheduler.schedulers.background import BackgroundScheduler
import time
def job():
print('job 3s')
if __name__=='__main__':
job()
sched = BackgroundScheduler(timezone='MST')
sched.add_job(job, 'interval', id='3_second_job', seconds=3)
sched.start()
while(True):
print('main 1s')
time.sleep(1)
运行结果:
job 3s
main 1s
main 1s
main 1s
job 3s
main 1s
main 1s
main 1s
这样虽然没有绝对做到“让job在start()后就开始运行”,但也能做到“不等待调度,而是刚开始就运行job”。
如果job执行时间过长会怎么样
如果执行job()的时间需要5s,但调度器配置为每隔3s就调用一下job(),会发生什么情况呢?我们写了如下例子:
from apscheduler.schedulers.background import BackgroundScheduler
import time
def job():
print('job 3s')
time.sleep(5)
if __name__=='__main__':
sched = BackgroundScheduler(timezone='MST')
sched.add_job(job, 'interval', id='3_second_job', seconds=3)
sched.start()
while(True):
print('main 1s')
time.sleep(1)
运行结果:
main 1s
main 1s
main 1s
job 3s
main 1s
main 1s
main 1s
Execution of job "job (trigger: interval[0:00:03], next run at: 2018-05-07 02:44:29 MST)" skipped: maximum number of running instances reached (1)
main 1s
main 1s
main 1s
job 3s
main 1s
可见,3s时间到达后,并不会“重新启动一个job线程”,而是会跳过该次调度,等到下一个周期(再等待3s),又重新调度job()。
为了能让多个job()同时运行,我们也可以配置调度器的参数max_instances,如下例,我们允许2个job()同时运行
from apscheduler.schedulers.background import BackgroundScheduler
import time
def job():
print('job 3s')
time.sleep(5)
if __name__=='__main__':
job_defaults = { 'max_instances': 2 }
sched = BackgroundScheduler(timezone='MST', job_defaults=job_defaults)
sched.add_job(job, 'interval', id='3_second_job', seconds=3)
sched.start()
while(True):
print('main 1s')
time.sleep(1)
运行结果:
main 1s
main 1s
main 1s
job 3s
main 1s
main 1s
main 1s
job 3s
main 1s
main 1s
main 1s
job 3s
每个job是怎么被调度的
通过上面的例子,我们发现,调度器是定时调度job()函数,来实现调度的。
那job()函数会被以进程的方式调度运行,还是以线程来运行呢?
为了弄清这个问题,我们写了如下程序:
from apscheduler.schedulers.background import BackgroundScheduler
import time,os,threading
def job():
print('job thread_id-{0}, process_id-{1}'.format(threading.get_ident(), os.getpid()))
time.sleep(50)
if __name__=='__main__':
job_defaults = { 'max_instances': 20 }
sched = BackgroundScheduler(timezone='MST', job_defaults=job_defaults)
sched.add_job(job, 'interval', id='3_second_job', seconds=3)
sched.start()
while(True):
print('main 1s')
time.sleep(1)
运行结果:
main 1s
main 1s
main 1s
job thread_id-10644, process_id-8872
main 1s
main 1s
main 1s
job thread_id-3024, process_id-8872
main 1s
main 1s
main 1s
job thread_id-6728, process_id-8872
main 1s
main 1s
main 1s
job thread_id-11716, process_id-8872
可见,每个job()的进程ID都相同,但线程ID不同。所以,job()最终是以线程的方式被调度执行。
BlockingScheduler定时任务及其他方式的实现
#BlockingScheduler定时任务
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime
首先看看周一到周五定时执行任务
# 输出时间
def job():
print(datetime.now().strtime("%Y-%m-%d %H:%M:%S"))
# BlockingScheduler
scheduler = BlockingScheduler()
scheduler.add_job(job, "cron", day_of_week="1-5", hour=6, minute=30)
schduler.start()
scheduler.add_job(job, 'cron', hour=1, minute=5)
hour =19 , minute =23 这里表示每天的19:23 分执行任务
hour ='19', minute ='23' 这里可以填写数字,也可以填写字符串
hour ='19-21', minute= '23' 表示 19:23、 20:23、 21:23 各执行一次任务
#每300秒执行一次
scheduler .add_job(job, 'interval', seconds=300)
#在1月,3月,5月,7-9月,每天的下午2点,每一分钟执行一次任务
scheduler .add_job(func=job, trigger='cron', month='1,3,5,7-9', day='*', hour='14', minute='*')
# 当前任务会在 6、7、8、11、12 月的第三个周五的 0、1、2、3 点执行
scheduler .add_job(job, 'cron', month='6-8,11-12', day='3rd fri', hour='0-3')
#从开始时间到结束时间,每隔俩小时运行一次
scheduler .add_job(job, 'interval', hours=2, start_date='2018-01-10 09:30:00', end_date='2018-06-15 11:00:00')
#自制定时器
from datetime import datetime
import time
# 每n秒执行一次
def timer(n):
while True:
print(datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
time.sleep(n)
timer(5)
BackgroundScheduler定时任务及其他方式的实现
启动异步定时任务
import time
from apscheduler.schedulers.background import BackgroundScheduler
from django_apscheduler.jobstores import DjangoJobStore, register_events, register_job
try:
# 实例化调度器
scheduler = BackgroundScheduler()
# 调度器使用DjangoJobStore()
scheduler.add_jobstore(DjangoJobStore(), "default")
# 'cron'方式循环,周一到周五,每天9:30:10执行,id为工作ID作为标记
# ('scheduler',"interval", seconds=1) #用interval方式循环,每一秒执行一次
@register_job(scheduler, 'cron', day_of_week='mon-fri', hour='9', minute='30', second='10',id='task_time')
def test_job():
t_now = time.localtime()
print(t_now)
# 监控任务
register_events(scheduler)
# 调度器开始
scheduler.start()
except Exception as e:
print(e)
# 报错则调度器停止执行
scheduler.shutdown()