前言
延时任务介绍:
比如你在某宝上下了一个订单,却没有支付,过了半个小时后这个订单自动取消了。
设计思路比较方法可以通过性能,能否持久化,拓展分布式等。当然要根据你的业务来。
1. 基于数据库轮训
此方案很easy,即将延时任务存进数据库的表中,然后通过一个线程定时的去扫描数据库,不断的将任务的触发时间和当前时间进行比较,如果达到任务的触发时间,就执行任务!
优点:简单易行,支持集群操作
缺点:
(1)对服务器内存资源、cpu资源消耗大
(2)存在延迟,比如你每隔3分钟扫描一次,那最坏的延迟时间就是3分钟
(3)在互联网项目中,经常会遇到有几千万条延时任务在跑。那么,数据库里延时任务表里就有几千万条记录,每隔几分钟这样扫描一次,数据库损耗极大
不推荐
2. 基于JDK延迟队列
DelayQueue + 线程池
该方案是利用JDK自带的DelayQueue来实现,这是一个无界阻塞队列,该队列只有在延迟期满的时候才能从中获取元素,放入DelayQueue中的对象,是必须实现Delayed接口的。
消费者通过 poll()/take()方法获取一个任务。
其中Poll():获取并移除队列的超时元素,没有则返回空
take():获取并移除队列的超时元素,如果没有则wait当前线程,直到有元素满足超时条件,返回结果。
优点::效率高,任务触发时间延迟低
缺点::(1)服务器重启后,数据全部消失,怕宕机。要满足高可用场景,需要hook线程二次开发;
(2)集群扩展相当麻烦
(3)因为内存条件限制的原因,比如在互联网项目中,延时任务通常十分的多,如果全丢JVM,内存容易OOM
(4)代码复杂度较高
也是利用优先队列实现的,元素通过实现 Delayed 接口来返回延迟的时间。不过延迟队列就是个容器,需要其他线程来获取和执行任务。
3. 基于时间轮
包含两个重要的数据结构:
(1)环形队列,例如可以创建一个包含3600个slot的环形队列(本质是个数组);
(2)任务集合,环上每一个slot是一个Set
同时,启动一个timer:
(1)此timer每隔1s,在环形队列中移动一格;
(2)用一个Current Index来标识正在检测的slot;
Task结构中有两个很重要的属性:
(1)Cycle-Num:当Current Index第几圈扫描到这个Slot时,执行任务;
(2)Task-Function:需要执行的任务函数;
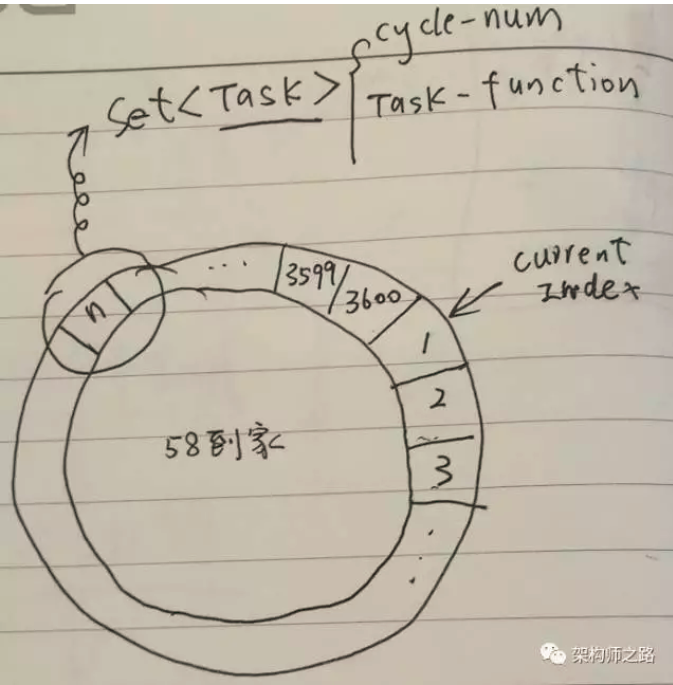
如上图,假设当前Current Index指向第一格,当有延时消息到达之后,例如希望3610秒之后,触发一个延时消息任务,只需:
(1)计算这个Task应该放在哪一个slot,现在指向1,3610秒之后,应该是第11格,所以这个Task应该放在第11个slot的Set
(2)计算这个Task的Cycle-Num,由于环形队列是3600格(每秒移动一格,正好1小时),这个任务是3610秒后执行,所以应该绕3610/3600=1圈之后再执行,于是Cycle-Num=1;
Current Index不停的移动,每秒移动一格,当移动到一个新slot,遍历这个slot中对应的Set
(1)如果不是0,说明还需要多移动几圈,将Cycle-Num减1;
(2)如果是0,说明马上要执行这个Task了,取出Task-Funciton执行,丢给工作线程执行,并把这个Task从Set
注意,不要用timer来执行任务,否则timer会越来越不准。
这种是通过增加轮次的概念。还有一种是通过多轮次的时间轮(Kafka内)
优点::效率高,任务触发时间延迟时间比delayQueue低,代码复杂度比delayQueue低(通过优先队列来获取最早需要执行的任务,因此插入和删除任务的时间复杂度都为O(logn),假设频繁插入删除次数为 m,总的时间复杂度就是O(mlogn))。时间轮是O(1)
缺点::(1)服务器重启后,数据全部消失,怕宕机。(可拓展持久化方案实现高可用,Netty kafak akka均有使用)
(2)集群扩展相当麻烦
(3)这种情况也是把任务丢JVM内存,因为内存条件限制的原因,,那么很容易就出现OOM异常
Netty 中有 HashedWheelTimer 工具原理类似
4. Redis
redis zset
zset是一个有序集合,每一个元素(member)都关联了一个score,通过score排序来取集合中的值。
具体如下图所示,我们将超时时间戳与延时任务分别设置为score和member,系统扫描第一个元素判断是否超时,具体如下图所示
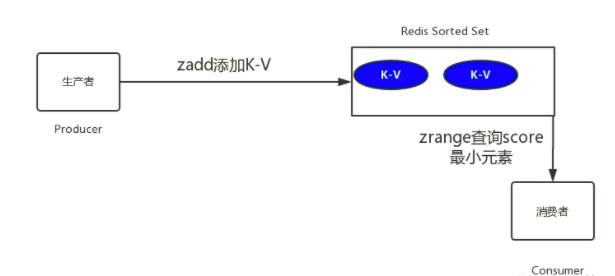
取出score最小的元素,与当前时间进行比较,如果发现已经到达时间,则执行任务。
键空间机制
该方案使用redis的Keyspace Notifications,中文翻译就是键空间机制,就是利用该机制可以在key失效之后,提供一个回调,实际上是redis会给客户端发送一个消息。是需要redis版本2.8以上。
做法很简单:
(1)给key设置一个超时时间
(2)给key超时事件订阅一个处理方法
(3)key超时了,redis将回调步骤(2)中订阅的方法
ps:官网不推荐使用该机制。因为Redis的发布/订阅目前是即发即弃(fire and forget)模式的,因此无法实现事件的可靠通知。也就是说,如果发布/订阅的客户端断链之后,此时刚好key的失效期到了,如果此时客户端又无法连接到,那么该延时任务就将丢失。即使客户端又恢复了连接,也不会再次回调。
优点:(1)由于使用Redis作为消息通道,消息都存储在Redis中。如果发送程序或者任务处理程序挂了,重启之后,还有重新处理数据的可能性。
(2)做集群扩展相当方便
(3)时间准确度高
缺点:(1)需要额外进行redis维护
5. MQ 基于消息队列
利用消息队列的某些特性实现延时队列,例如我们可以实现rabbitMQ的延时队列。
优点: 高效,可以利用rabbitmq的分布式特性轻易的进行横向扩展,消息支持持久化增加了可靠性。
缺点:本身的易用度要依赖于rabbitMq的运维.因为要引用rabbitMq,所以复杂度和成本变高
mq有些场景可能不太适合,比如对这个延迟任务取消。
6. 基于线程池
ScheduledThreadPoolExecutor
1.5 引入了 ScheduledThreadPoolExecutor,它是一个具有更多功能的 Timer 的替代品,允许多个服务线程。如果设置一个服务线程和 Timer 没啥差别。
ScheduledThreadPoolExecutor继承了 ThreadPoolExecutor,实现了 ScheduledExecutorService。可以定性操作就是正常线程池差不多了。区别就在于两点,一个是 ScheduledFutureTask ,一个是 DelayedWorkQueue。
其实 DelayedWorkQueue 就是优先队列,也是利用数组实现的小顶堆。而 ScheduledFutureTask 继承自 FutureTask 重写了 run 方法,实现了周期性任务的需求。
/**
* Overrides FutureTask version so as to reset/requeue if periodic.
*/
public void run() {
boolean periodic = isPeriodic();
if (!canRunInCurrentRunState(periodic))
cancel(false);
else if (!periodic) // 不是周期性任务 run
ScheduledFutureTask.super.run();
else if (ScheduledFutureTask.super.runAndReset()) {
setNextRunTime(); // 设置下一次执行时间
reExecutePeriodic(outerTask); // 重新入队列
}
}
ScheduledThreadPoolExecutor 大致的流程和 Timer 差不多,也是维护一个优先队列,然后通过重写 task 的 run 方法来实现周期性任务,主要差别在于能多线程运行任务,不会单线程阻塞。
并且 Java 线程池的设定是 task 出错会把错误吃了,无声无息的。因此一个任务出错也不会影响之后的任务。