索引: 索引就是一种存储结构,作用就是用来加快数据查询使用得。就好比我们找书得某一页知识一样,如果没有目录那我们就要一页一页得找,有了目录,我们可以根据目录定位到大概范围得页数,数据库中得索引作用就是类似这种。
索引的分类:
主键索引:一个表中只能有一个主键索引,PRIMARY KEY;
唯一索引:定义某个列得唯一性,一个表中可以有多个唯一索引。举个例子比如个人信息表,银行卡号,车牌号就是要唯一性得。
普通索引:列既不是主键列,也不是唯一列。
组合索引:多列组成得一个索引,用于组合搜索。(比如我们要经常根据name和age作为条件来搜索得话,就可以将name和age作为组合索引)。
全文索引:用于数据量比较大,只能用于CHAR ,VARCHAR,TEXT数据列类型,因为用like得时,大数据量得时候会比较影响效率。不过现在全文索引基本上不依赖于数据库自带得了,用Elasticsearch也是蛮多得。
也说下聚集索引和非聚集索引的区别吧。 根本区别是表记录的排列顺序和与索引的排列顺序是否一致。
聚集索引(聚簇索引):表记录得排列顺序和索引得排列顺序一致,所以查询效率快。但插入数据得时候,会比较慢,会对索引重新排序,以此来保证索引得顺序和表中记录得顺序一致。
非聚集索引(非聚簇索引):指定了表中的逻辑顺序
索引固然能够加快查询,但是也不要过多得使用,因为索引得创建是需要占用磁盘空间得,而且每次更新数据时,还会去更新索引。所以索引虽好,但不要贪用哦!
那接着就有一个问题了,索引是如何实现加快查询效率得呢?在未建立索引的情况下,如果一个表里面有1000条数据,那我们查询某一条的数据则需要全表扫描,时间复杂度是O(n);索引的底层是B+树,说到树,可以了解下二叉树、AVL树、红黑树他们都是如何去实现数据查询的,都是基于二分法的查找,使得复杂度只需要O(logN)就可以查询到数据。这篇将会说到B树和B+树都是如何提高查询效率的。
B+树是由B树衍生而来的,所以先来看下B树的结构
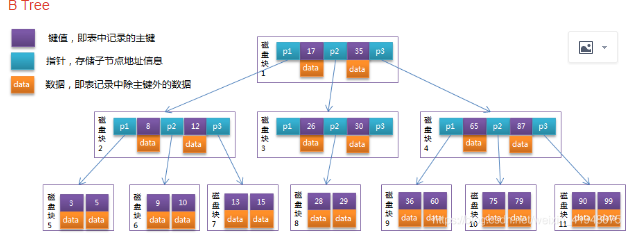
P1:指向其他磁盘块的指针
17:创建索引时,指定索引列的值
data:存放的是key(即17、35)所对应的整行数据。
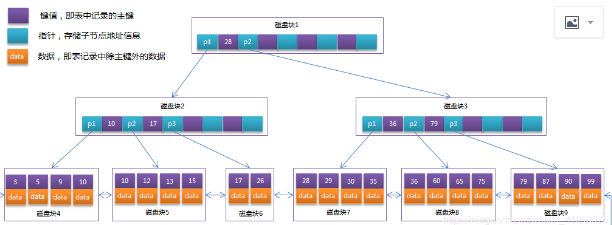
B+树的改动是在非叶子节点上仅仅存储了指针和索引的key,数据记录都存储在了叶子节点,如此一来的话,可以存储不少数据。而且每个叶子节点都有个双向指针,这样设计的话,我们查询数据的方式就有两种:(1)基于主键的范围查找和分页查找(2)从根节点查询,随机查询。通过以上知识,我们也进一步了解到Mysql底层索引的实现方式了,也明白了是如何提升查询效率的。
一个索引就是一个B+树,一个表里面聚簇索引只能有一个,叶子节点存储的是整行数据。非聚簇索引可以有多个,比如说想给name创建个索引(非聚簇索引),那么name的叶子节点存的是索引的主键值。当我们select * from user where name = 'xx'时,会首先到name得B+树下面搜索xx,找到其存储得索引key值,再根据key,去到聚簇索引里面搜索对应得整行数据,这个过程也叫回表。(这也是为什么聚簇索引查询效率比非聚簇索引查询效率快得原因了)
注意一点:参照官网,不是所有的存储引擎都是用的B+树(虽然写的B-Tree,但底层还是B+ 树),还有一些是用的Hash表。
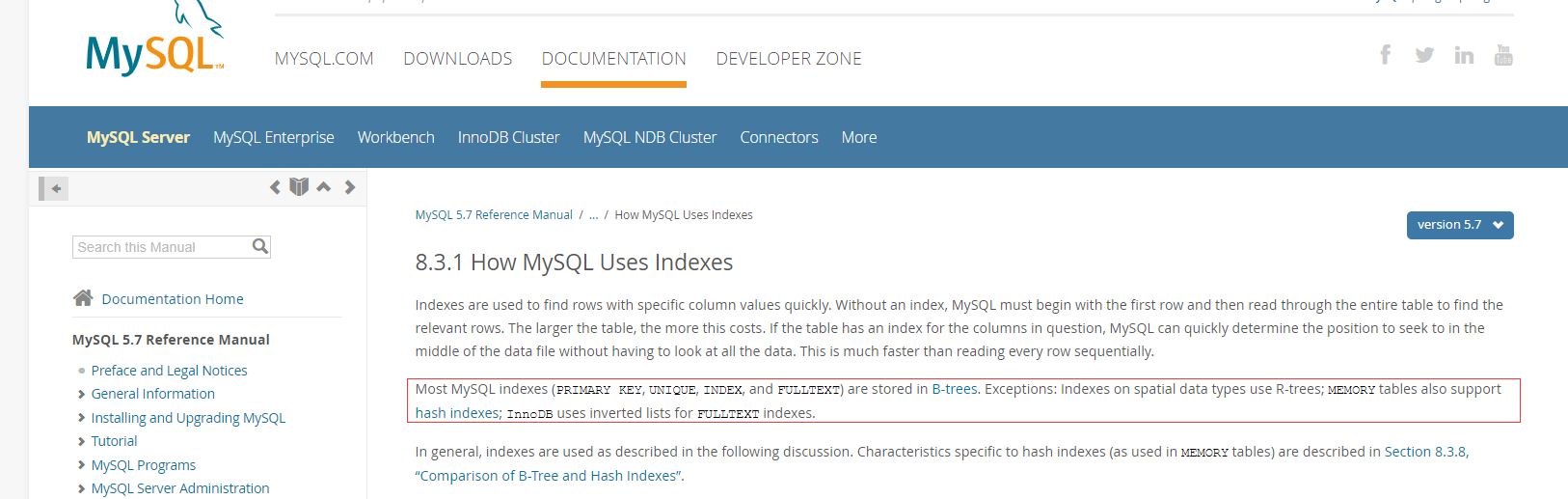
Hash索引存在得缺点:(1)Hash索引底层是Hash表,哈希表是key-value形式得存储结构,所以当数据量比较多得时候,元素存储是没有顺序得,这样我们查询数据得时候,是没法根据索引在某一块得范围内进行查询了,只能全表查询。适用于等值查询得场景。
(2)不支持多列联合索引得最左匹配原则。
(3)如果有大量重复键值得情况下,会存在Hash冲突,从而导致查询得效率。