方法一:
SELECT TOP 页大小 *
FROM table1
WHERE id NOT IN
(
SELECT TOP 页大小*(页数-1) id FROM table1 ORDER BY id
)
ORDER BY id
FROM table1
WHERE id NOT IN
(
SELECT TOP 页大小*(页数-1) id FROM table1 ORDER BY id
)
ORDER BY id
方法二:
SELECT TOP 页大小 *
FROM table1
WHERE id >
(
SELECT ISNULL(MAX(id),0)
FROM
(
SELECT TOP 页大小*(页数-1) id FROM table1 ORDER BY id
) A
)
ORDER BY id
FROM table1
WHERE id >
(
SELECT ISNULL(MAX(id),0)
FROM
(
SELECT TOP 页大小*(页数-1) id FROM table1 ORDER BY id
) A
)
ORDER BY id
网上的结论:
通过SQL 查询分析器,显示比较:我的结论是:
分页方案一:(利用Not In和SELECT TOP分页) 效率次之,需要拼接SQL语句
分页方案二:(利用ID大于多少和SELECT TOP分页)效率最高,需要拼接SQL语句
分页方案一:(利用Not In和SELECT TOP分页) 效率次之,需要拼接SQL语句
分页方案二:(利用ID大于多少和SELECT TOP分页)效率最高,需要拼接SQL语句
我的测试过程,大表条数: 1521715 条。 ID不设主键,不从1开始。
方案一的执行计划:

执行时间0秒。
方案二的执行计划:(出现 缓冲池中的可用内存不足。的错误,重启Sqlserver就好。)

执行时间6秒。
分析如下:
方案一两个表扫描行数只有100 和 150 。
方案二最后两个节点是全表扫描。 这是最关键的。
ID 加主键情况:
方案一情况照旧。
方案二的执行计划:
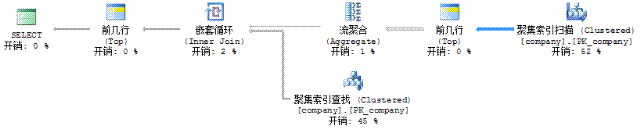
执行时间0秒。
但是,第一行最后一个节点都是扫描了100条记录。 但是,方案一占用了17%,方案二占用了62%,在这里,占用量越大,整体时间越短。所以 方案二是最优的,方案一浪费时间在两个方面,一是 Not IN 需要 哈希匹配,二是第二个聚集索引扫描扫描了150条记录,而方案二第二个聚集索引扫描只扫描了50条。
附Sql2005的方法三:
SELECT TOP 页大小 *
FROM
(
SELECT ROW_NUMBER() OVER (ORDER BY id) AS RowNumber,* FROM table1
) A
WHERE RowNumber > 页大小*(页数-1)
FROM
(
SELECT ROW_NUMBER() OVER (ORDER BY id) AS RowNumber,* FROM table1
) A
WHERE RowNumber > 页大小*(页数-1)
 |
作者:NewSea 出处:http://newsea.cnblogs.com/ QQ,MSN:iamnewsea@hotmail.com |