1 什么是SolrCloud
SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用SolrCloud。当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。SolrCloud是基于Solr和Zookeeper的分布式搜索方案,它的主要是使用Zookeeper作为集群的配置信息中心。
它有几个特色功能:
1)集中式的配置信息
2)自动容错
3)近实时搜索
4)查询时自动负载均衡
1.1 zookeeper是个什么?
顾名思义zookeeper就是动物园管理员,他是用来管hadoop(大象)、Hive(蜜蜂)、pig(小猪)的管理员,Apache Hbase和Apache Solr 的分布式集群都用到了zookeeper;Zookeeper:是一个分布式的、开源的程序协调服务,是hadoop项目下的一个子项目。
1.2 Zookeeper可以干哪些事情
1、配置管理
在我们的应用中除了代码外,还有一些就是各种配置。比如数据库连接等。一般我们都是使用配置文件的方式,在代码中引入这些配置文件。但是当我们只有一种配置,只有一台服务器,并且不经常修改的时候,使用配置文件是一个很好的做法,但是如果我们配置非常多,有很多服务器都需要这个配置,而且还可能是动态的话使用配置文件就不是个好主意了。这个时候往往需要寻找一种集中管理配置的方法,我们在这个集中的地方修改了配置,所有对这个配置感兴趣的都可以获得变更。比如我们可以把配置放在数据库里,然后所有需要配置的服务都去这个数据库读取配置。但是,因为很多服务的正常运行都非常依赖这个配置,所以需要这个集中提供配置服务的服务具备很高的可靠性。一般我们可以用一个集群来提供这个配置服务,但是用集群提升可靠性,那如何保证配置在集群中的一致性呢?这个时候就需要使用一种实现了一致性协议的服务了。Zookeeper就是这种服务,它使用Zab这种一致性协议来提供一致性。现在有很多开源项目使用Zookeeper来维护配置,比如在HBase中,客户端就是连接一个Zookeeper,获得必要的HBase集群的配置信息,然后才可以进一步操作。还有在开源的消息队列Kafka中,也使用Zookeeper来维护broker的信息。在Alibaba开源的SOA框架Dubbo中也广泛的使用Zookeeper管理一些配置来实现服务治理。
2、名字服务
名字服务这个就很好理解了。比如为了通过网络访问一个系统,我们得知道对方的IP地址,但是IP地址对人非常不友好,这个时候我们就需要使用域名来访问。但是计算机是不能是别域名的。怎么办呢?如果我们每台机器里都备有一份域名到IP地址的映射,这个倒是能解决一部分问题,但是如果域名对应的IP发生变化了又该怎么办呢?于是我们有了DNS这个东西。我们只需要访问一个大家熟知的(known)的点,它就会告诉你这个域名对应的IP是什么。在我们的应用中也会存在很多这类问题,特别是在我们的服务特别多的时候,如果我们在本地保存服务的地址的时候将非常不方便,但是如果我们只需要访问一个大家都熟知的访问点,这里提供统一的入口,那么维护起来将方便得多了。
3、分布式锁
其实在第一篇文章中已经介绍了Zookeeper是一个分布式协调服务。这样我们就可以利用Zookeeper来协调多个分布式进程之间的活动。比如在一个分布式环境中,为了提高可靠性,我们的集群的每台服务器上都部署着同样的服务。但是,一件事情如果集群中的每个服务器都进行的话,那相互之间就要协调,编程起来将非常复杂。而如果我们只让一个服务进行操作,那又存在单点。通常还有一种做法就是使用分布式锁,在某个时刻只让一个服务去干活,当这台服务出问题的时候锁释放,立即fail over到另外的服务。这在很多分布式系统中都是这么做,这种设计有一个更好听的名字叫Leader Election(leader选举)。比如HBase的Master就是采用这种机制。但要注意的是分布式锁跟同一个进程的锁还是有区别的,所以使用的时候要比同一个进程里的锁更谨慎的使用。
4、集群管理
在分布式的集群中,经常会由于各种原因,比如硬件故障,软件故障,网络问题,有些节点会进进出出。有新的节点加入进来,也有老的节点退出集群。这个时候,集群中其他机器需要感知到这种变化,然后根据这种变化做出对应的决策。比如我们是一个分布式存储系统,有一个中央控制节点负责存储的分配,当有新的存储进来的时候我们要根据现在集群目前的状态来分配存储节点。这个时候我们就需要动态感知到集群目前的状态。还有,比如一个分布式的SOA架构中,服务是一个集群提供的,当消费者访问某个服务时,就需要采用某种机制发现现在有哪些节点可以提供该服务(这也称之为服务发现,比如Alibaba开源的SOA框架Dubbo就采用了Zookeeper作为服务发现的底层机制)。还有开源的Kafka队列就采用了Zookeeper作为Cosnumer的上下线管理。
2 Solr集群的结构
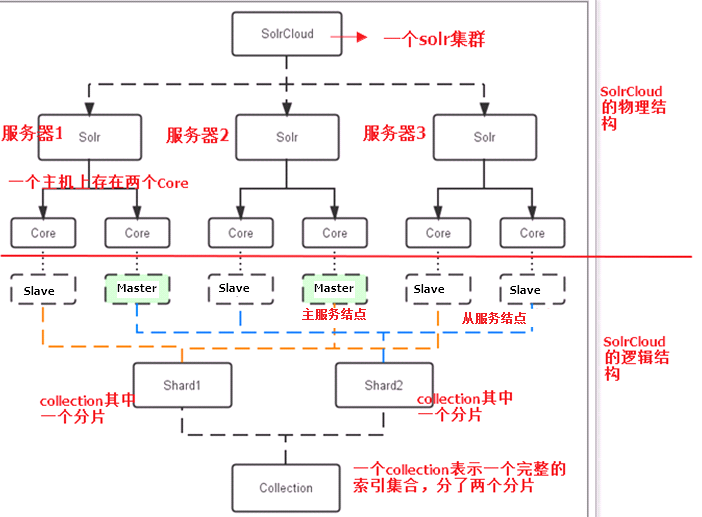
3 Solr集群的搭建
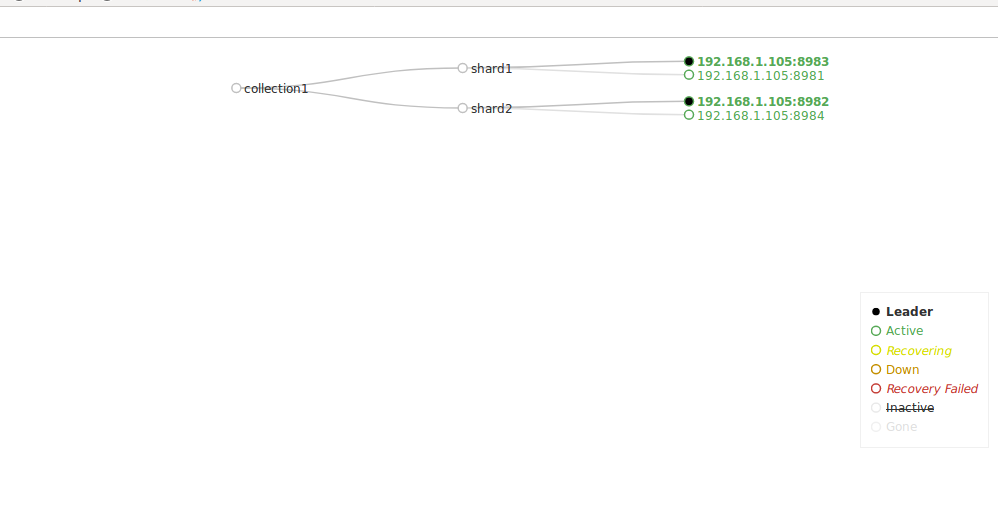
集群的结构大致如下,一个zookeeper集群负责管理配置文件和投票选举,solr集群共俩分片,每个分片一主一仆。
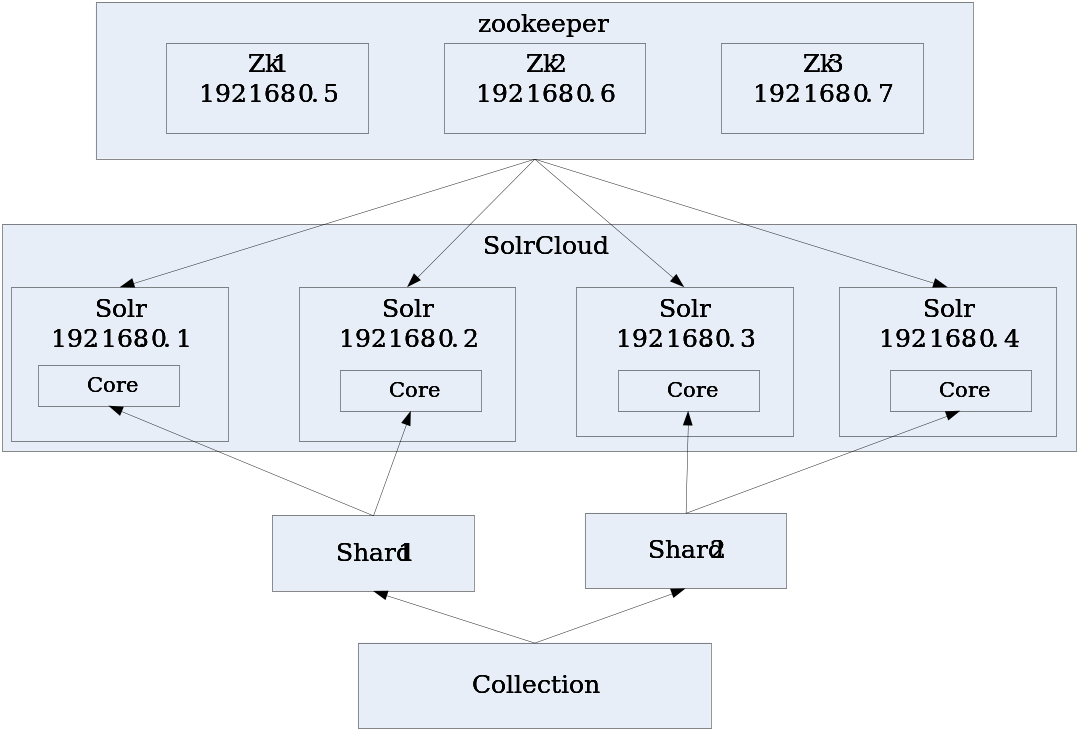
3、1 zookeeper集群搭建
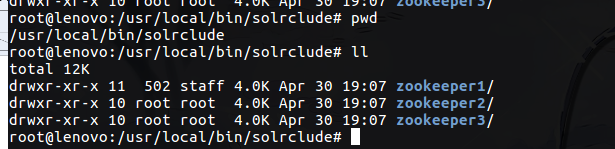
1)下载zookeeper这里采用3.4.11并且解压,拷贝三分分别命名,如图:
2)配置zookeeper,这里以zookeeper1为例(网络版需要更换ip,伪分布式只需要更换port)
在zookeeper节点中建立一个data目录,用于存放数据文件,创建一个文件"myid",内容是1,表明当前节点id
1 # cd zookeeper1 2 # mkdir data 3 # echo 1 >> data/myid
进入config中,修改节点配置,指明数据文件目录、客户端连接端口和zookeeper集群中各个节点信息
1 cd conf # 进入zookeeper config目录 2 cp zoo_sample.cfg zoo.cfg # 复制一份配置文件,并修改内
修改配置信息如下:
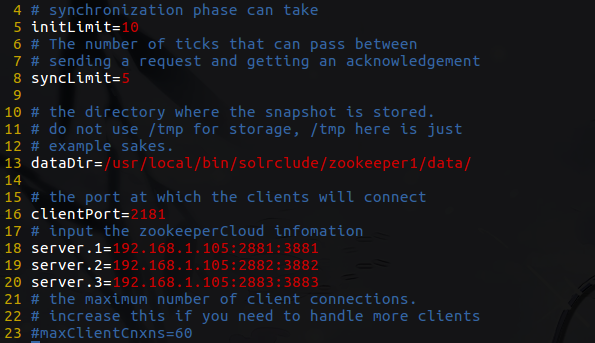
重点关注最后四行
dataDir:就是刚刚创建的目录,有个myid文件表示当前节点id(我们填的1)
clientPort:外部访问solrcloud时连接的端口,因为solr交给zookeeper管理了
server.zookeeper_nodeId=zookeeper_ip:选举端口:投票端口,选举和投票在不同端口进行
3)依次修改其他几个节点的配置信息(节点至少要三个)
4)启动zookeeper集群和关闭集群
# bin/zkServer.sh start # 启动zookeeper
# bin/zkServer.sh stop # 关闭节点
节点全部启动后,可以查看节点状态
# bin/zkServer.sh status
Solr集群安装参考别人的博客,
链接:https://segmentfault.com/a/1190000010836061
重要操作:
本次实验目录设置

solr7_conf是配置文件,要把该配置文件上传到zookeeper管理,后面会说
三个zookeeper集群,四个solr集群,solr中的docs和example文件夹可以删除,如下图
Solr 配置
#修改 bin/solr.in.sh SOLR_HOST="本机ip" SOLR_PORT="程序运行端口" #分布式时ip不一样,端口一样,伪分布式时,ip一样,端口不一样 #可选操作 SOLR_PORT=8981 ZK_HOST="192.168.1.105:2181,192.168.1.105:2182,192.168.1.105:2183" #如果不指定这两个,可以在solr启动时指定

solr_home, 配置指定你创建的索引库位置所在,默认就在安装目录的server/solr中
本人配置:
#solr1
SOLR_HOST="192.168.1.105"
SOLR_PORT="8981"
ZK_HOST="192.168.1.105:2181,192.168.1.105:2182,192.168.1.105:2183"#solr2
SOLR_HOST="192.168.1.105" SOLR_PORT="8982"
ZK_HOST="192.168.1.105:2181,192.168.1.105:2182,192.168.1.105:2183"
#solr3
SOLR_HOST="192.168.1.105" SOLR_PORT="8983"
ZK_HOST="192.168.1.105:2181,192.168.1.105:2182,192.168.1.105:2183"
#solr4
SOLR_HOST="192.168.1.105" SOLR_PORT="8984"
ZK_HOST="192.168.1.105:2181,192.168.1.105:2182,192.168.1.105:2183"
启动所有solr
#没有在配置文件中指定ZK_HOST 和 SOLR_PORT的在启动要指定
solr1/bin/solr start -cloud -z 192.168.1.105:2181,192.168.1.105:2182,192.168.1.105:2183 -p 8981 -force"
solr2/bin/solr start -cloud -z 192.168.1.105:2181,192.168.1.105:2182,192.168.1.105:2183 -p 8982 -force"
solr3/bin/solr start -cloud -z 192.168.1.105:2181,192.168.1.105:2182,192.168.1.105:2183 -p 8983 -force"
solr4/bin/solr start -cloud -z 192.168.1.105:2181,192.168.1.105:2182,192.168.1.105:2183 -p 8984 -force"
本次测试启动:
solr1/bin/solr start -cloud -force"
solr2/bin/solr start -cloud -force"
solr3/bin/solr start -cloud -force"
solr4/bin/solr start -cloud -force"
参数解释:
-c / -cloud 以solrcloud方式启动
-z 指定zookeeper集群的地址和客户端连接端口,以逗号隔开
-p 指定端口
后两个在有配置的情况下可以省
创建集群库
在任意一台机器
$ /opt/solr-6.6.0/bin/solr create_collection -c collection1 -shards 2 -replicationFactor 2 -force
create_collection 创建集合,只有在cloud模式下有效
-c 指定库(collection)名称 -shards 指定分片数量,可简写为 -s ,索引数据会分布在这些分片上 -replicationFactor 每个分片的副本数量,每个碎片由至少1个物理副本组成
或者浏览器输入:
http://192.168.1.105:8982/solr/admin/collections?action=CREATE&name=collection2&numShards=2&replicationFactor=2
最后上传自己的配置文件交给zookeeper集中管理(配置文件就是自己创建的分词器和fieldtype等)
配置文件上传到ZooKeeper 集群
可用参数(所有参数都是必需的)
-n <name> 在ZooKeeper中设置的配置名称,可以通过管理界面,点击菜单,Cloud 选中 Tree / configs 下查看,配置列表 -d <configset dir>配置设置为上传的路径。路径需要有一个“conf”目录,依次包含solrconfig.xml等。最好可以提供绝对路径 -z <zkHost> Zookeeper IP 端口,多个zk用"," 分隔
SolrCloud是通过Zookeeper集群来保证配置文件的变更及时同步到各个节点上,所以,可以将配置文件上传到Zookeeper集群。
$ solr1/bin/solr zk upconfig -z 192.168.1.105:2181,192.168.1.105:2182,192.168.1.105:2183 -n myconfig -d ../solr7_conf/conf
删除上传到ZooKeeper 集群的solr 配置
rm 删除-r 递归删除
$ solr1/bin/solr zk rm -r /configs/myconfig -z 192.168.1.105:2181,192.168.1.105:2182,192.168.1.105:2183
Connecting to ZooKeeper at node1:2181,node2:2181,node3:2181 ...
Removing Zookeeper node /configs/mynewconfig from ZooKeeper at node1:2181,node2:2181,node3:2181 recurse: true查看服务状态
solr1/bin/solr status
删除collection
配置目录是否被其他集合使用。如果没有,那么该目录将从SolrCloud 集群 中删除
solr1/bin/solr delete -c collection1
有时候上面方法删不掉,用下面这个
删除collection1.
浏览器输入:
http://192.168.1.105:8983/solr/admin/collections?action=DELETE&name=collection1
停止集群
四个节点分别调用
bin/solr stop
副本状态
$ bin/solr healthcheck -c test_collection -z 192.168.1.105:2181,192.168.1.105:2182,192.168.1.105:2183
# 如果指定了 ZK_HOST和端口,随便找个节点目录输入输入: bin/solr healthcheck -c collection
修改自己的配置文件
虽然solr现在支持页面直接添加field域,但是fieldType还是需要自己预先指定,所以要把配置文件从zookeeper中down下来,修改后再up上去(同名会自动覆盖)
# down下来配置 solr1/bin/solr zk downconfig -n myconfig -d /home/conf 修改managed-schema,添加中文分词器 如下: <fieldType name="text_ik" class="solr.TextField"> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType> 这样就加入了中文分词器IK 然后需要把相关jar包和IK的配置文件分别放在server/solr-webapps/webapp/WEB-INF下的lib和classes中 最后上传配置文件即可 solr1/bin/solr zk upconfig -n myconfig -d /home/conf
效果图:

注意:一定要把相关jar包和配置文件放在WEB-INF/lib 和 classes中,不然你会发现怎么弄都是错,我就是一直错,重新弄了好几个小时都不行,结果看下日志,真毙了狗,把包拷进去就好了。ik分词器去我上篇博客找百度云链接
最后用solrj测试下:
导入maven依赖
写个测试程序:
单点测试:

集群测试:待了解