栈和队列是非常重要的数据结构,后面要学习的很多算法都依赖于这俩数据结构,只要是学过编程的人应该都对这两个东东有所耳闻,这里还是对其进行复习一下,进一步认识它们的概念,虽然纯理论,但是有个了解之后有助于之后的使用。
其实栈和队列可以理解成是对之前学过的数组和链表的一种限制,下面具体来了解一下:
栈【Stack】:
先来看一下来自维基百科上对它的定义:
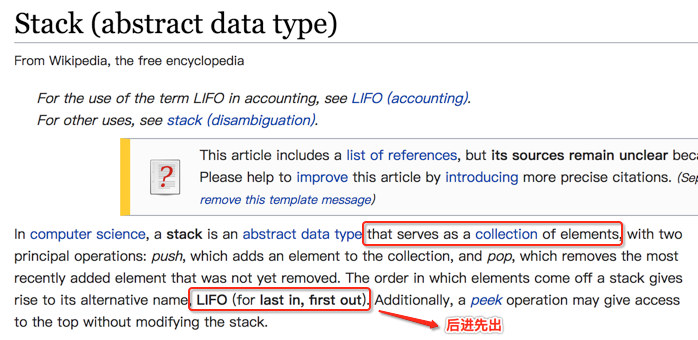
而为啥栈是后进先出的呢?下面看一下存数据与取数据就清楚啦:
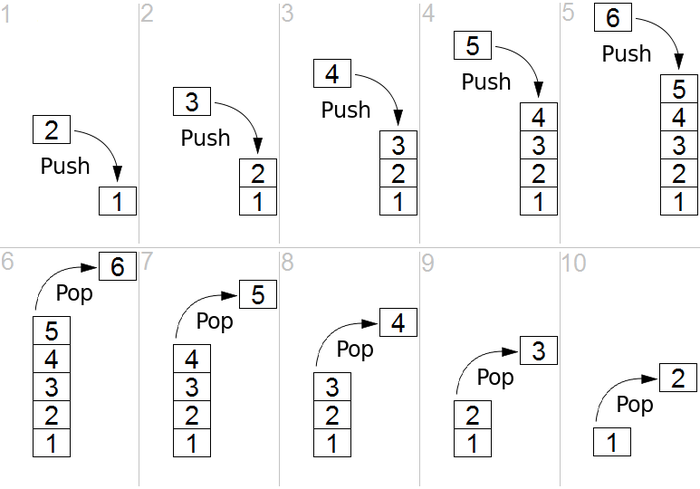
有木有豁然开朗,也就是后放的数据先被取出来,所以是“后进先出”。
接下来看一下对实现一个栈通常需要实现的方法定义:
看一下C++对于stack的实现:

清楚了栈的定义之后,下面来看下它的实际意义:
1、函数调用过程就是一个栈的最好应用。
比如这样一个调用过程:
函数A ---> 函数B ---> 函数C
而返回过程是:
函数C ---> 函数B ---> 回至A
刚好就是栈的特性,后进先出。
2、平常分析的算法的空间复杂度实际上就是指的栈的大小,怎么理解?
比如说之前学习递归实现的快速排序【http://www.cnblogs.com/webor2006/p/7159078.html】的空间复杂度是O(log n),实际上也就是指函数调用的深度,而函数调用也就是一个栈的应用,所以说也是指栈的深度。
队列【Queue】:
先上维基百科的定义:
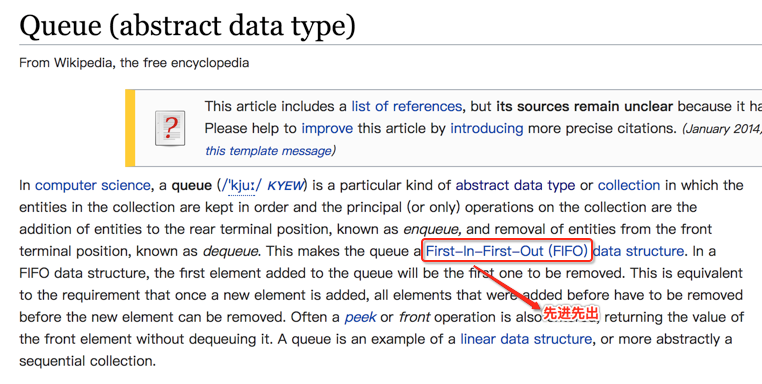
为啥它是先进先出呢?看下图:

清楚了队列的定义之后,下面来举一个实际比较有意义的使用场景:
生产者与消费者问题:有一个消费者,多个生产者,则可以利用队列将生产者生产的数据都放到队列当中,当然这个队列要是线程安全的【blockqueue】,而消费数据时则按先来后到的顺序进行一一消费。
总结:通过对上面的介绍,进一步发现其实栈和队列只不过是对容器【像之前学的数组或链表】进行了一定的也限制,也就是放数据得按一定的规则,而拿数据也得有一定的规则而已。