接着上一次https://www.cnblogs.com/webor2006/p/15468778.html继续
宏定义:
不带参数宏定义:
-
-
为了区分预处理指令和一般的C语句,所有预处理指令都以符号“#”开头,并且结尾不用分号。
-
预处理指令可以出现在程序的任何位置,它的作用范围是从它出现的位置到文件尾。习惯上我们尽可能将预处理指令写在源程序开头,这种情况下,它的作用范围就是整个源程序文件。
-
C语言提供供了多种预处理功能,
如宏定义、文件包含、条件编译等。合理地使用预处理功能编写的程序便于阅读、修改、移植和调试,也有利于模块化程序设计。
实践:
比如通常我们遍历数组是这样写的对吧:
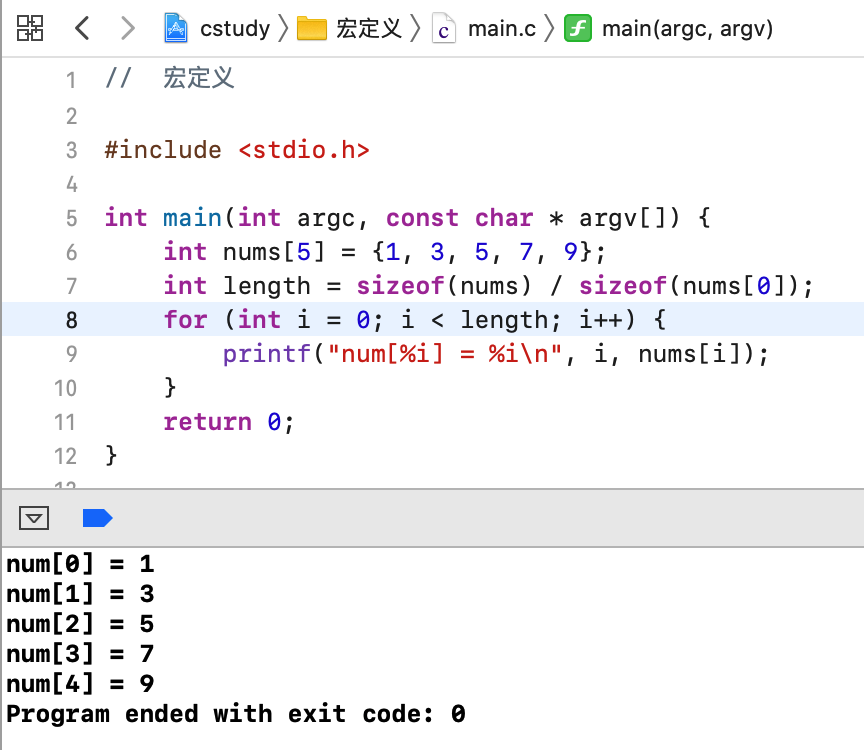
其中对于数组长度如果不想动态计算,就可以使用宏定义,如下:
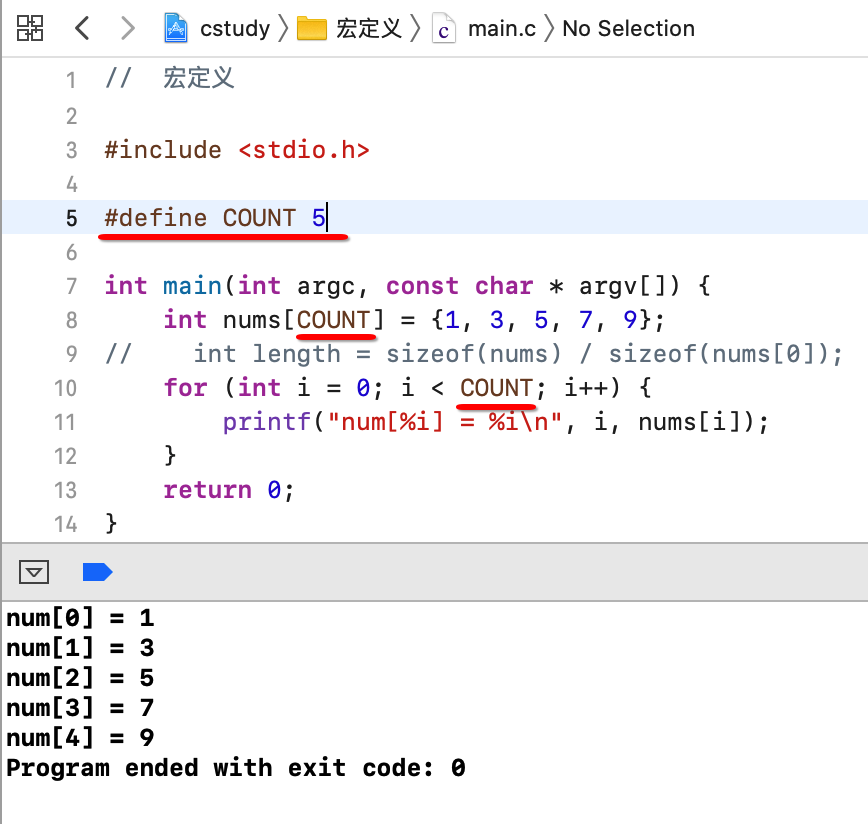
也就是宏定义的格式为:
#define 标识符 字符串
其中的“#”表示这是一条预处理命令。凡是以“#”开头的均为预处理命令。“define”为宏定义命令。“标识符”为所定义的宏名。“字符串”可以是常数、表达式、格式串等。它会在程序编译成0和1之前,将所有宏名替换为宏的值。
另外关于宏在使用中有一个非常容易犯的错误点,就是不要在后面加分号,比如咱们加个分号你会发现程序就报错了:

另外宏定义的作用域是从定义的第一行开始,一直到文件末尾,但是如果你想提前终止宏定义可以使用:

而它的使用场景一般可以对不变的东东进行提取,比如API地址的访问,通常项目的API地址可能域名是一样的,所以可以用宏定义把baseurl提取出来,如下:
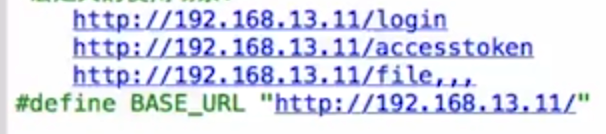
带参数的宏定义:
对于宏定义还可以定义参数的,比如求两数的和我们通常是这样定义函数的:
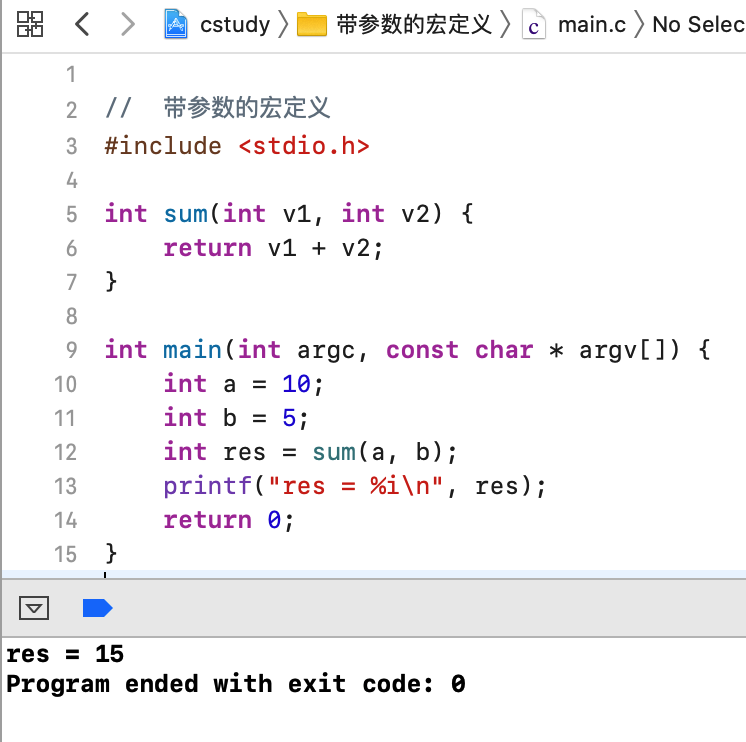
接下来咱们可以将这个求和的功能进行宏定义,如下:
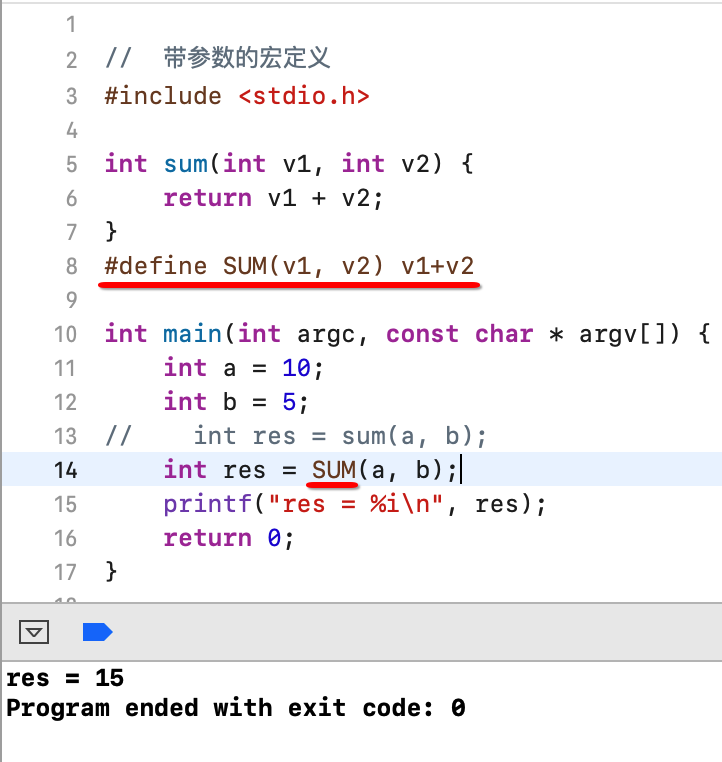
其中对于宏一定要明白,无论是有参数还是没参数的宏,它们都是不会做任何计算的,仅仅是在翻译成0和1之前做一个简单的“替换”。
那对于有参数的宏定义啥时候用比较好呢?如果函数的功能比较简单,仅仅是做一些简单的运算则可以使用宏定义,使用宏定义效率更高,运行速度更快【因为其实不是代码替换,不像函数还得去函数地址中找存储空间,再给形参分配空间,再运算再返回】,但是如果函数比较复杂,不仅仅是一些简单的运算,那么还是得使用函数。
下面再来定义一个宏,有一个细节需要揭露:
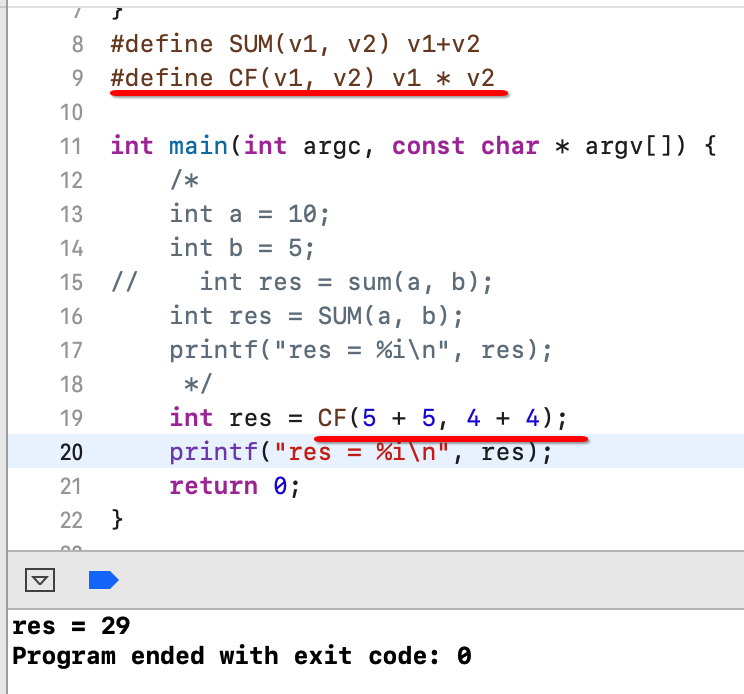
呃,貌似不如预期呀,预期应该是(5 + 5) * (4 + 4),而现在变成了5 + 5 * 4 + 4了,此时宏定义则需要这样修改:
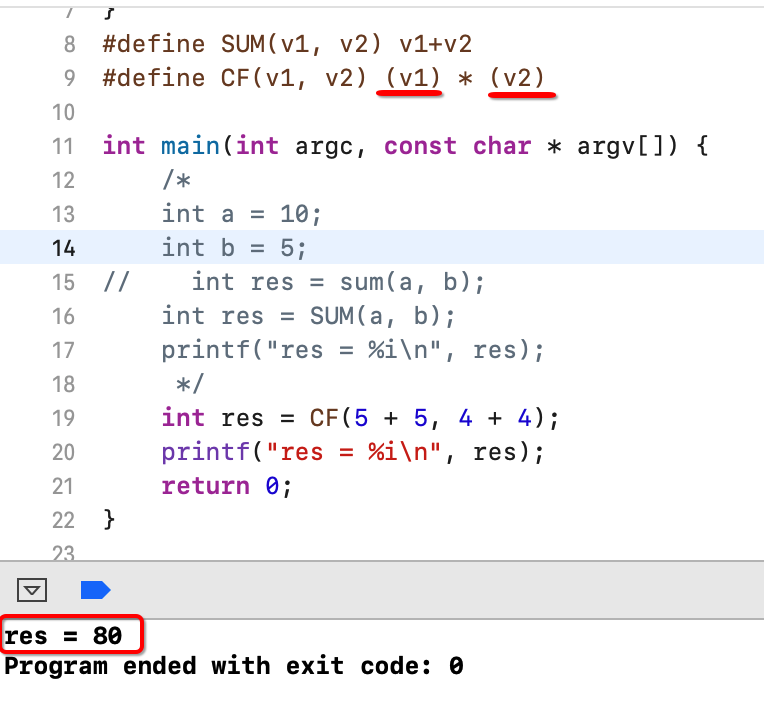
接下来再来看一个问题:

呃,又不如预期了,预期应该是PF(2),也就是4嘛,这里分析一下原因,其实就是将宏定义展开就知道了:

按照从左至右的顺序来算出来,是不是刚好就是等于16?而预期应该展开是这样:

其实解决起来也很简单,如下:
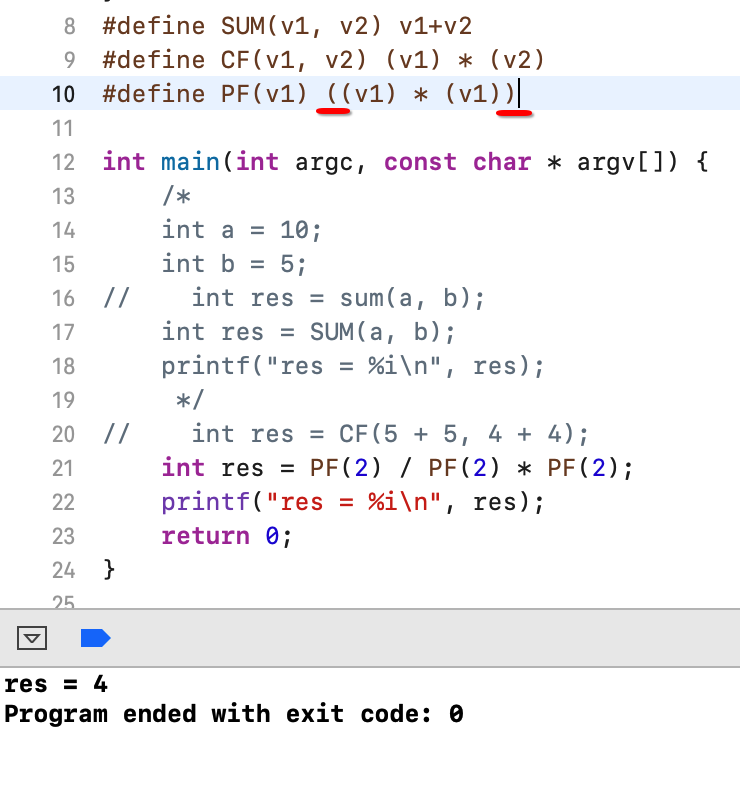
也就是对于带参数的宏定义有如下两个注意点:
1、一般情况下建议写带参数的宏的时候,给每个参数加上一个();
2、一般情况下建议写带参数的宏的时候,给结果也加上一个();
条件编译:
基本概念:
为什么要使用条件编译?
1、按不同的条件去编译不同的程序部分,因而产生不同的目标代码文件。有利于程序的移植和调试。
2、条件编译当然也可以用条件语句来实现。 但是用条件语句将会对整个源程序进行编译,生成 的目标代码程序很长,而采用条件编译,则根据条件只编译其中的程序段1或程序段2,生成的目 标程序较短。
#if-#else 条件编译指令:
这个条件编译跟if...else写法非常类似,先来看一下我们平常写的:
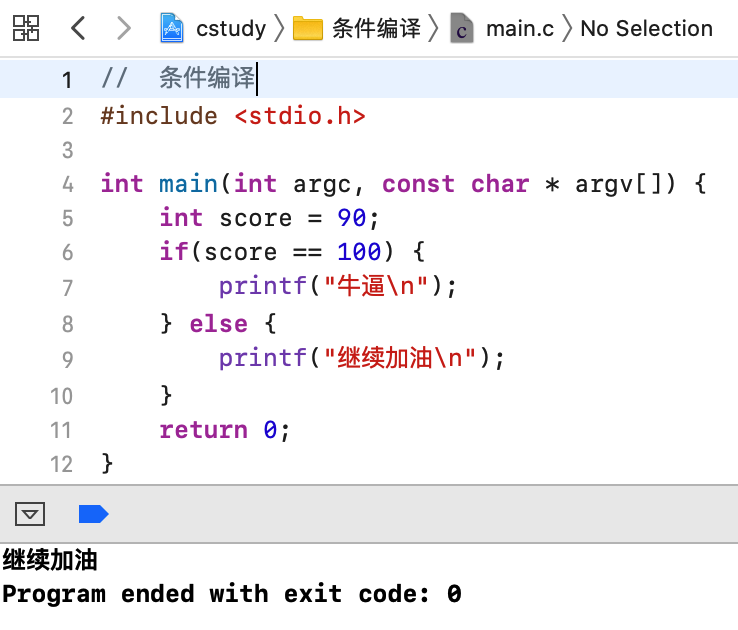
而改成条件编译就是这样了:
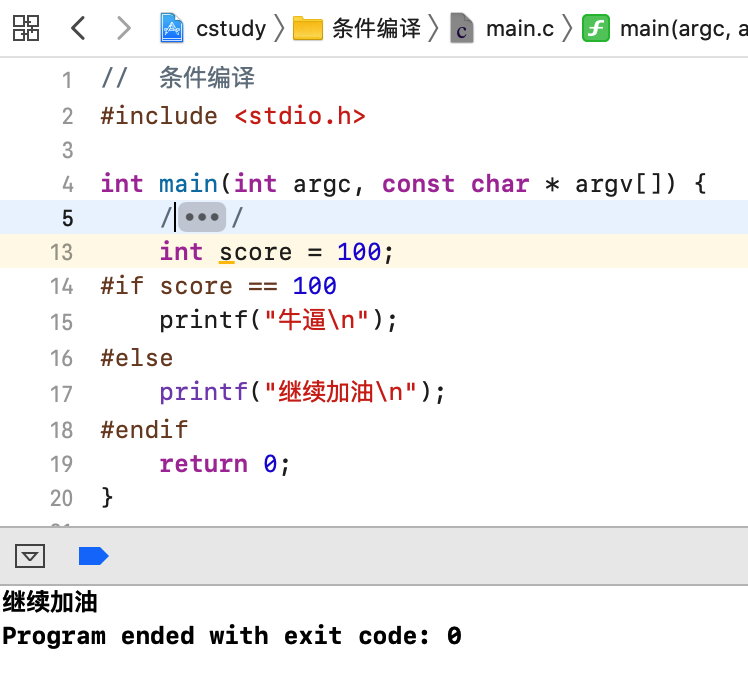
是不是神似,对于这个条件编译有两个细节可以发现:
1、条件编译的代码都是顶格写的,有别于咱们正常写的代码;
2、为啥没有输出“牛逼”呢?这其实也很好理解,因为这是预处理指令,此时还在编译之前,是不会执行score变量的赋值的,当然就输出else的语句喽。
所以,这里有一个注意点:条件编译是不能用来判断变量的,因为在不同的生命周期,它一般会和宏定义结合使用,比如:
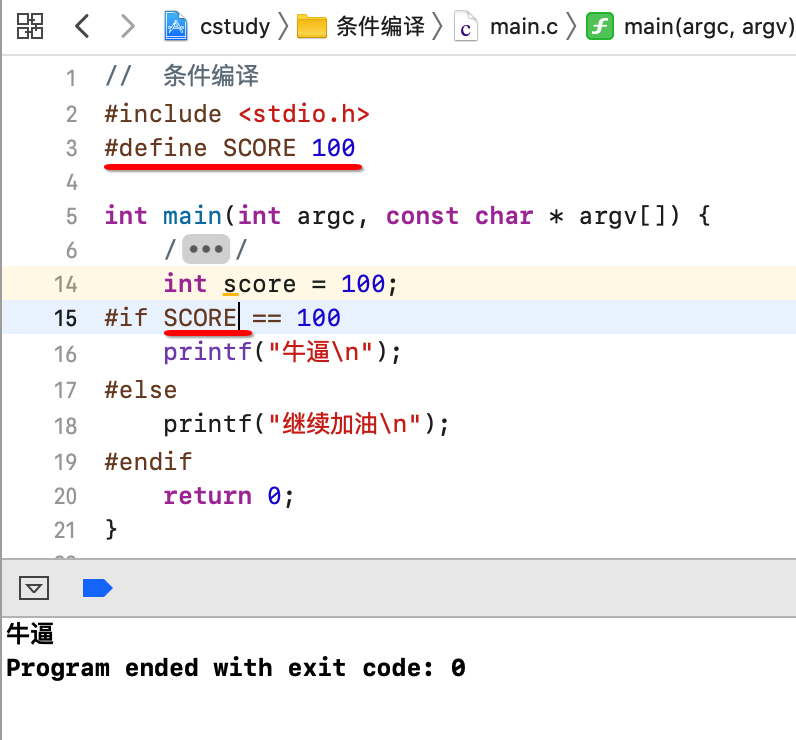
对于通常的条件语句我们可以是多条对吧,对于条件编译也是一样的可以:
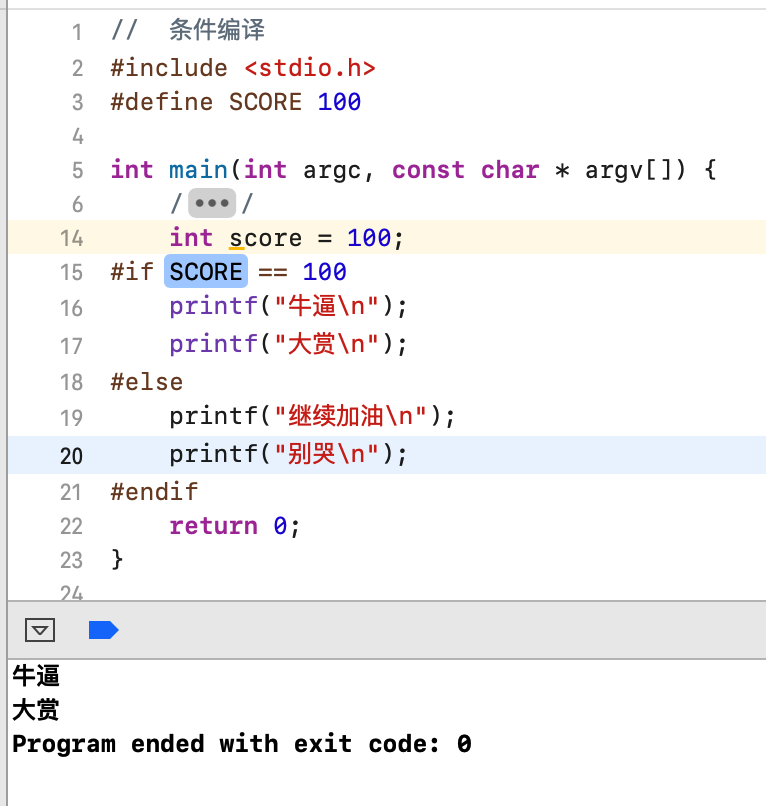
那对于if和条件编译之间有啥区别呢,下面来总结一下:
共同点:
都可以对给定的条件进行判断,添加满足或者不满足都可以执行特定的代码。
区别:
1、生命周期不同:if是在运行时,而#if是在编译之前;
2、#if需要一个明确的结束符号#endif,为啥呢?因为如果省略掉#endif,那么系统就不知道条件编译的范围,则会将满足条件之后的第二个条件之后的所有内容都删除。
3、if会将所有的代码都编译到二进制当中,而#if只会将满足条件的部分一直到下一个条件的部分编译到二进制当中。
条件编译的优点:缩小应用程序的大小,因为是部分编译。
另外条件编译也是可以有多个else的,比如:

使用条件编译指令调试bug:
最典型的是你在debug时是需要输出一些调试信息的,但是到了release包时这些调试信息是不需要的对吧,此时就可以使用条件编译来控制这个日志的输出,比如:
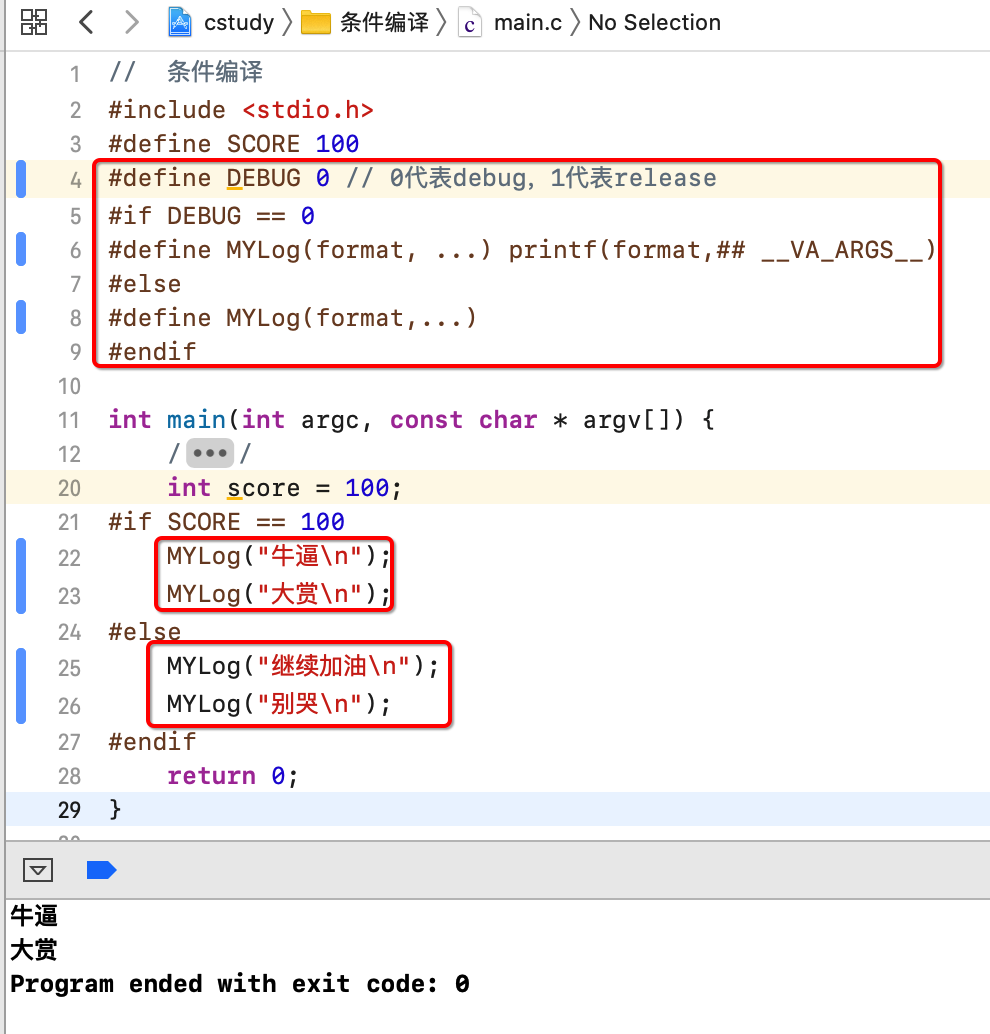
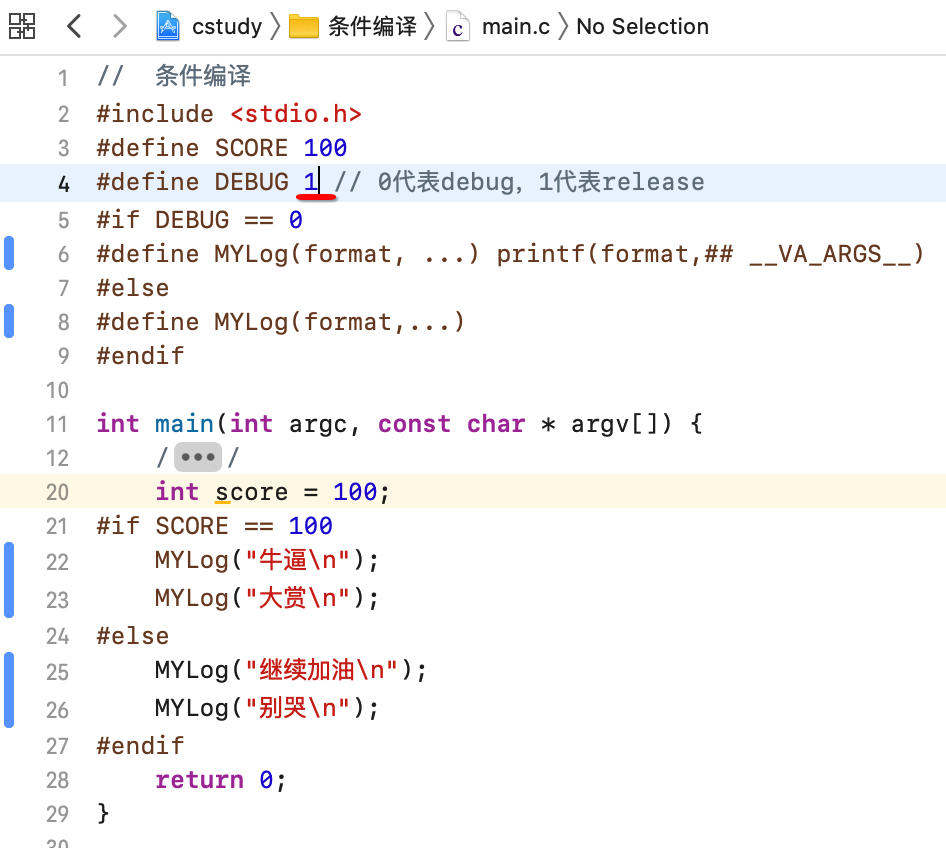
而如果发布上线了,改一下类型:
其它写法:
#ifdef 条件编译指令:
格式为:
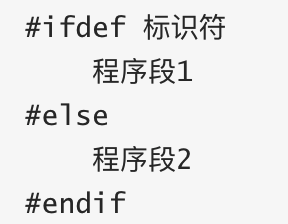
它的功能是,如果标识符已被#define命令定义过则对程序段1进行编译;否则对程序段2进行编译。如果没有程序段2(它为空),本格式中的#else可以没有,即可以写为:

下面来试一下:
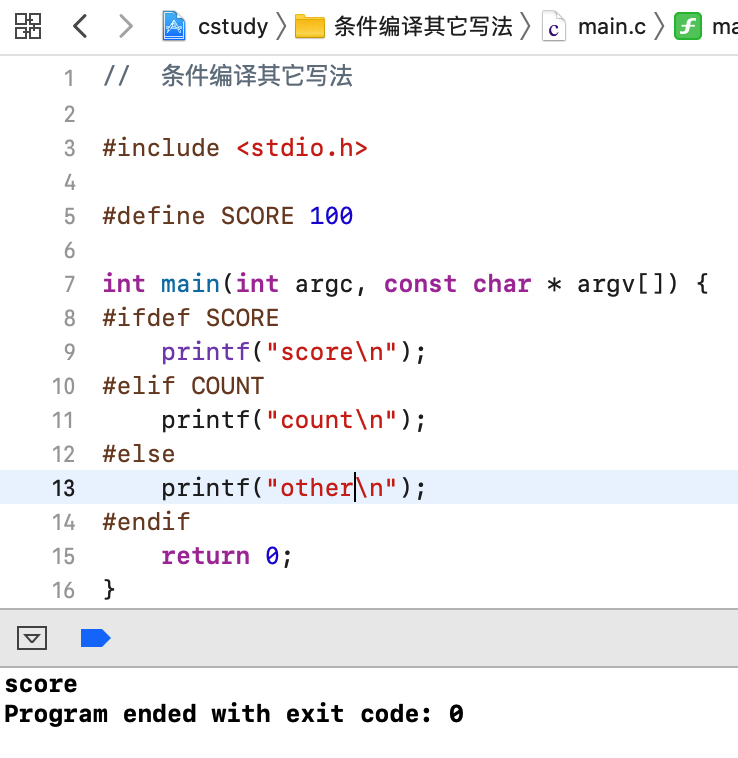
修改一下:
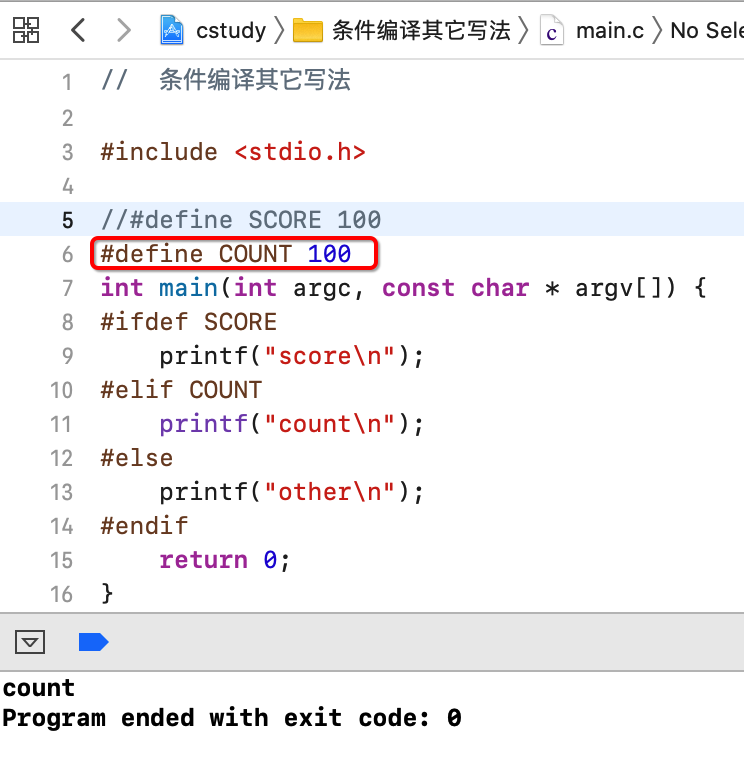
#ifndef 条件编译指令:
这个跟上面ifdef相关,比较简单:
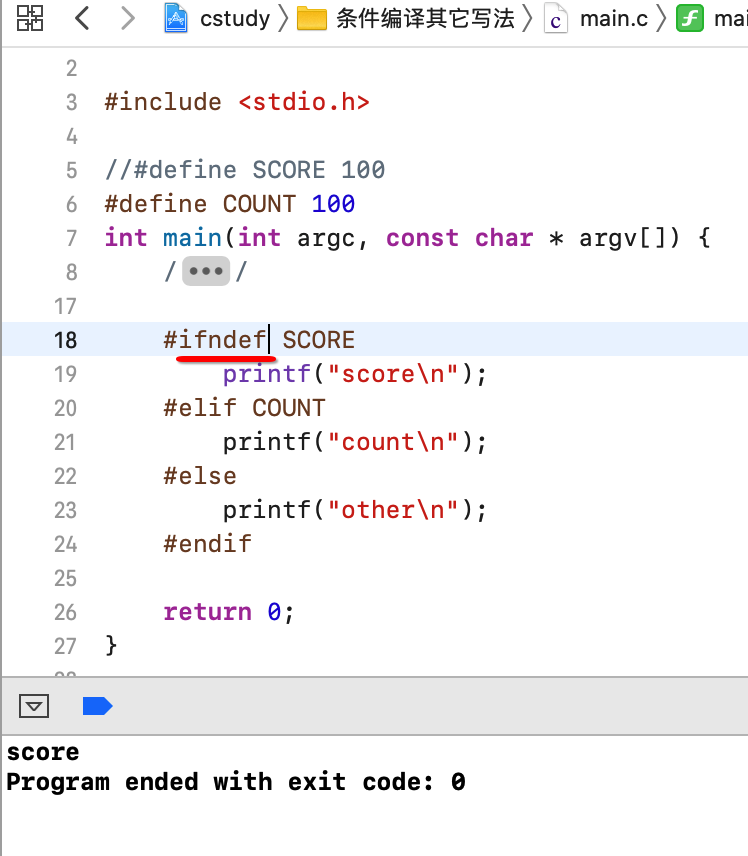
文件包含:
关于文件包含其实就是用#include,天天在用:
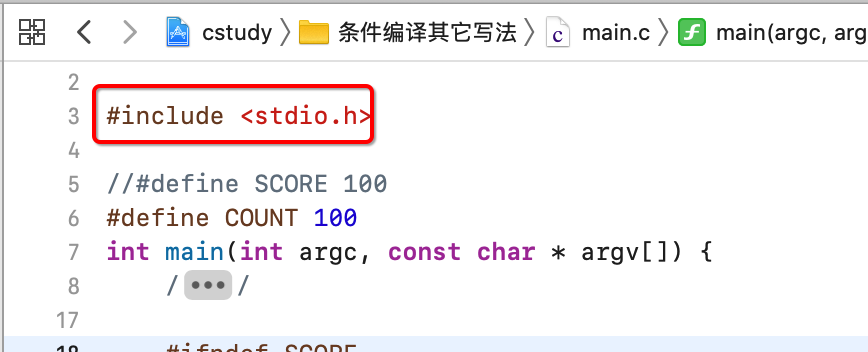
但是它还是有一些值得学习的细节,关于#include有两种写法:
1、#include <>它会先去编译器环境下查找,如果找不到则再去系统的环境下查找,通常系统的库用的就是它;
2、#include ""会先在当前文件查找,找不到再去编译器环境下查找,如果再找不到则再去系统的环境下查找。
通常在使用这个包含指令时,会遇到如下两个问题。
重复包含问题:
它会将待包含的文件内容完整的拷贝过来,接着就有一个重复包含的问题了,下面看一下:
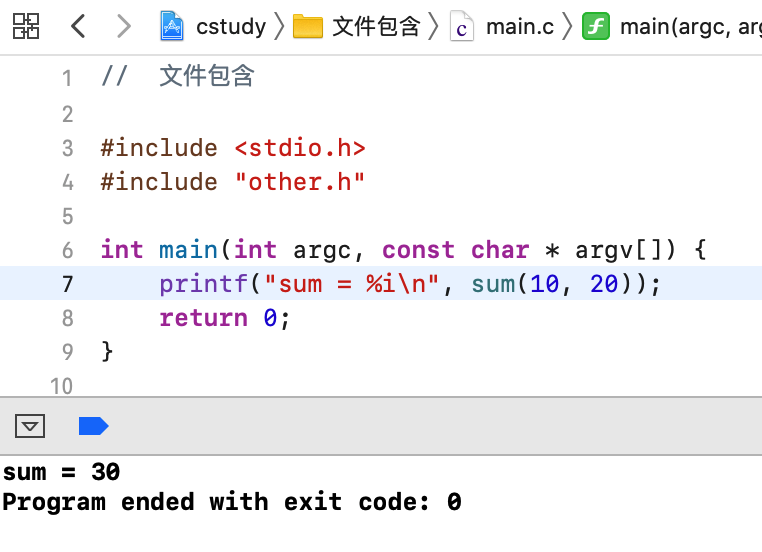
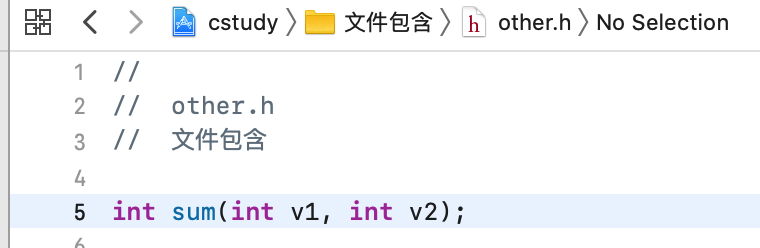

而由于函数是可以重复声明,所以如果不小写包含了多次,编译运行是完全不会有问题的,比如:
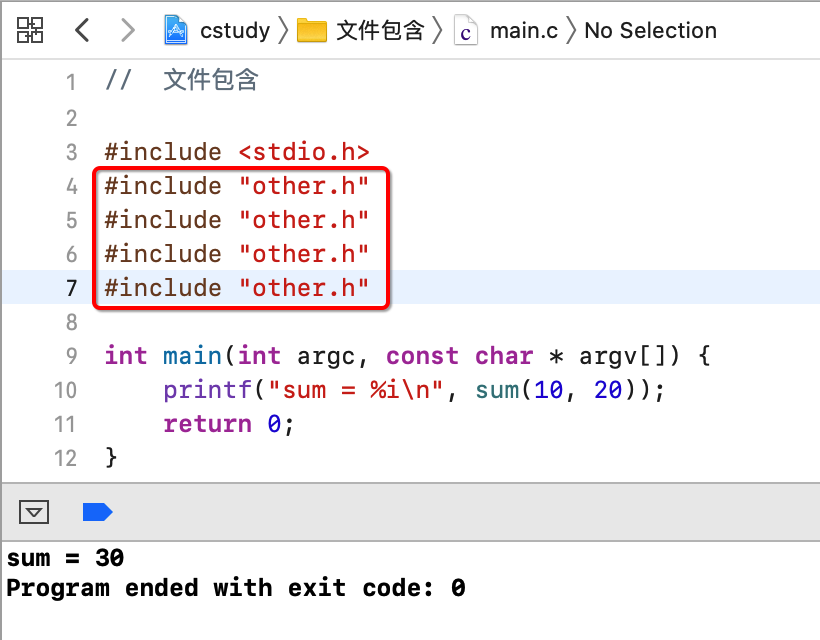
程序木影响,但是重复包含会降低编译效率,因为每遇到一个include都需要进行翻译成代码的过程, 所以为了防止重复包含,一般在头文件中会加入如下条件编译代码,如下:
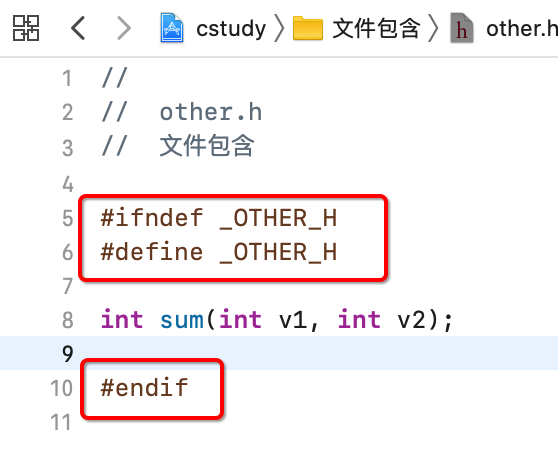
对于这些只做了解既可,因为在IDE中新建c文件时会自动帮你加上这些判断。
循环包含问题:
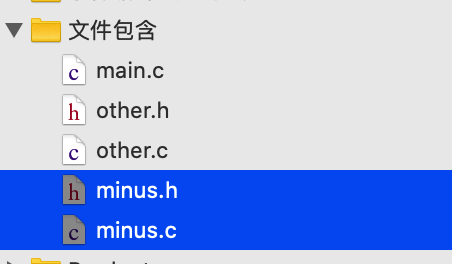
对于上面的重复包含头文件是不影响程序运行的对吧,但是如果是循环包含那就会编译出错,下面来还原一下循环包含错误出现的整个过程。这里再新建一个文件,里面定义一个减法函数:
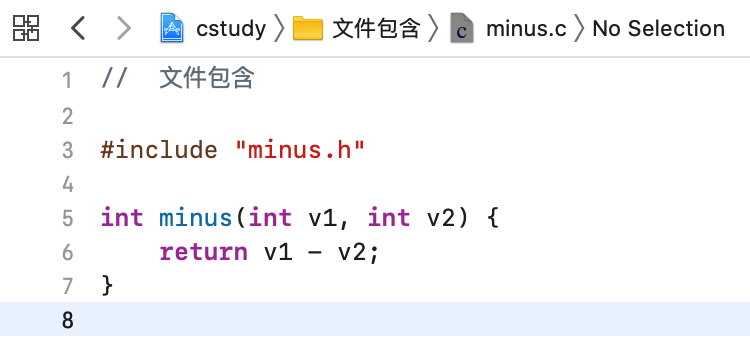
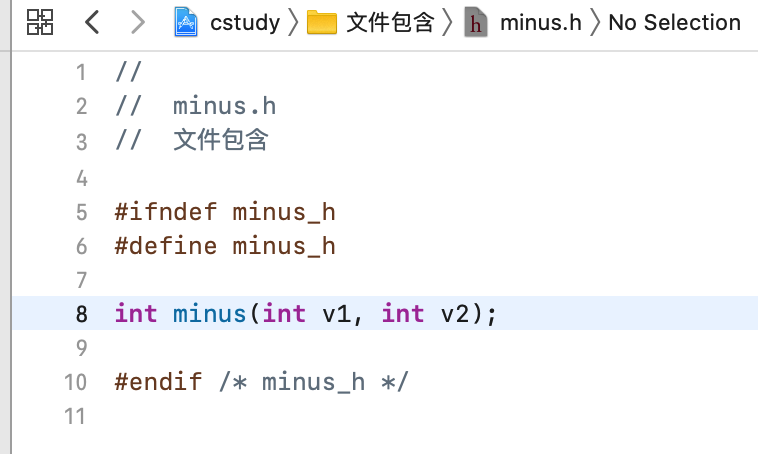
好,接下来有一个需求,就是在我们做减少操作之前 ,需要先进行加法运算,那对于加法运算不是在other.c已经封装好了么?所以:
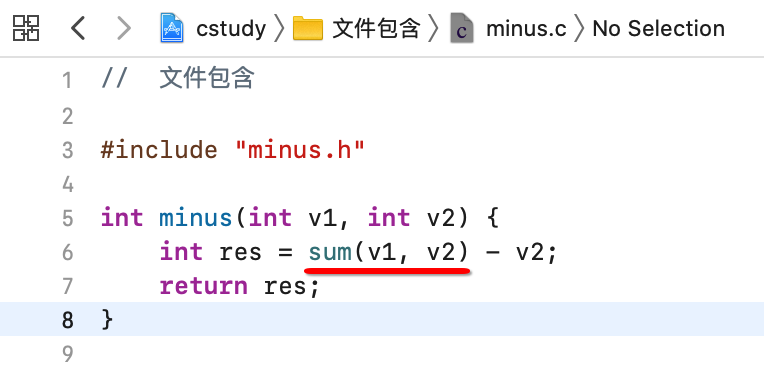
好,接下来回到main中调用一下:
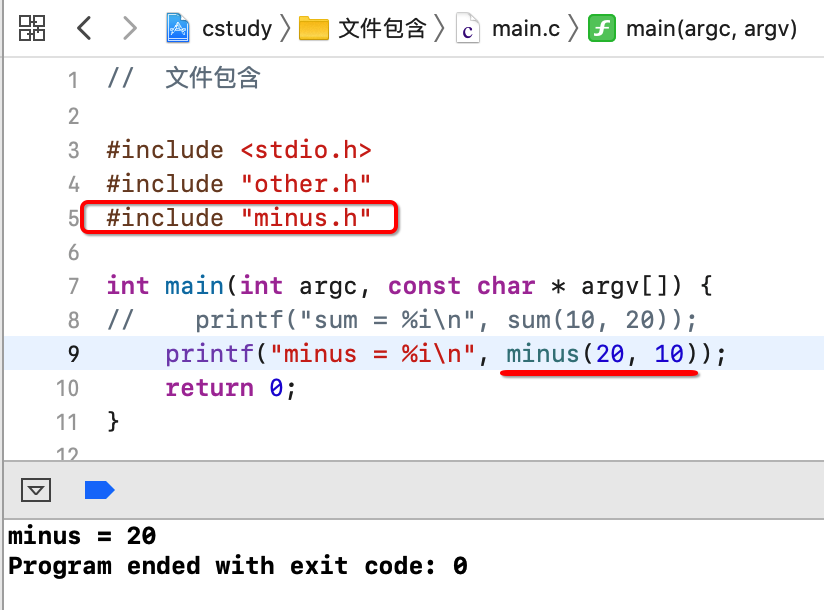
嗯,一切都木毛病, 接下来又来需求了,需要在加法之前,先做减法,也就是:
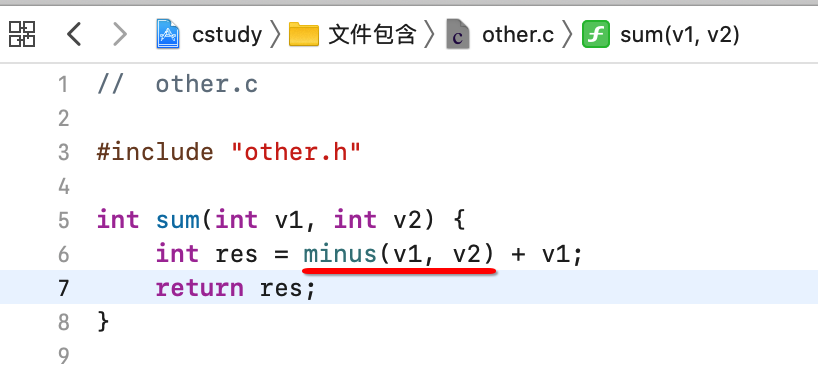
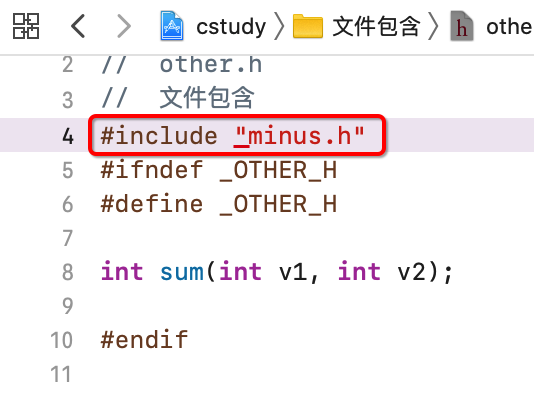
一编译报错了,主要是报在两个头文件中了,如下:

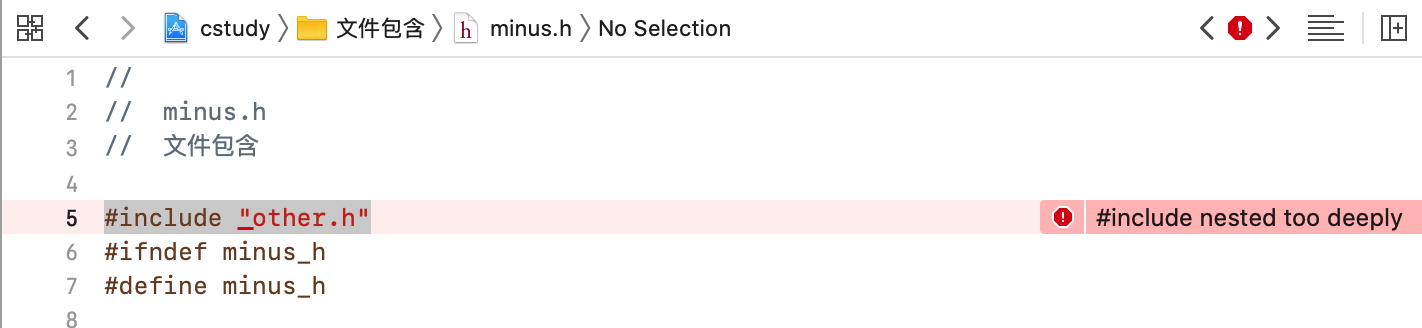
然后错误详情就是循环拷贝了:
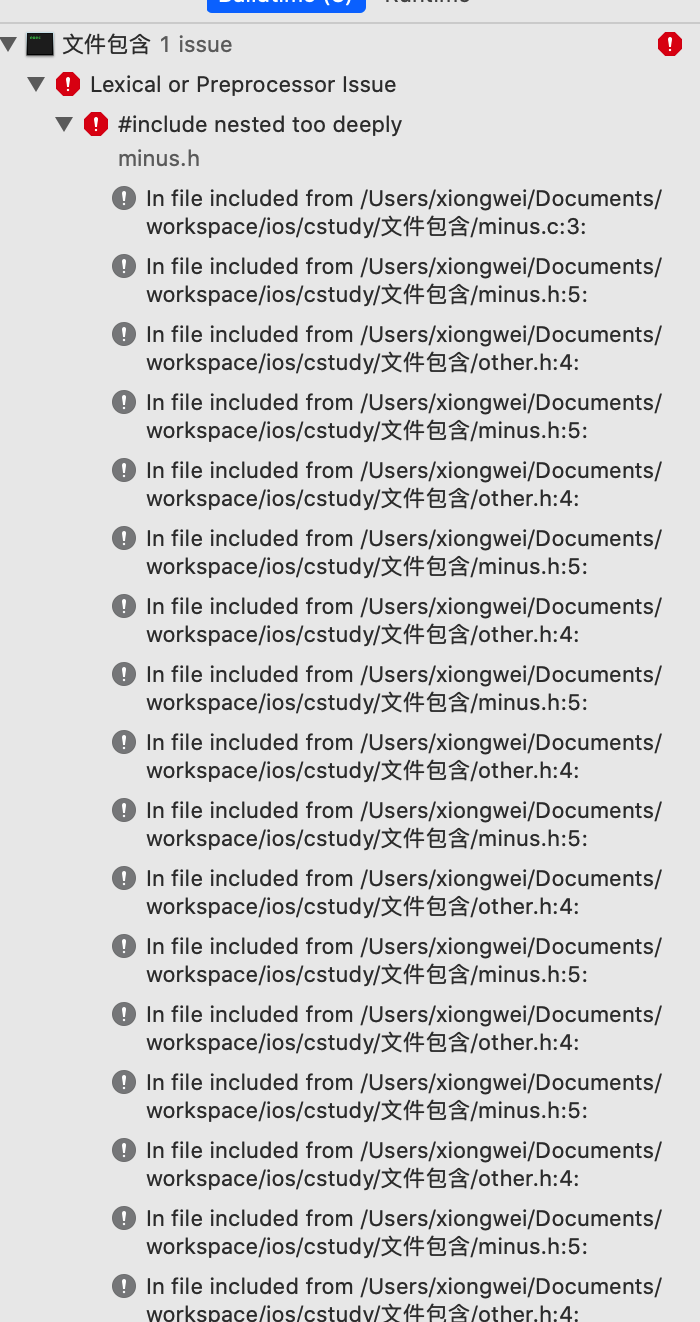
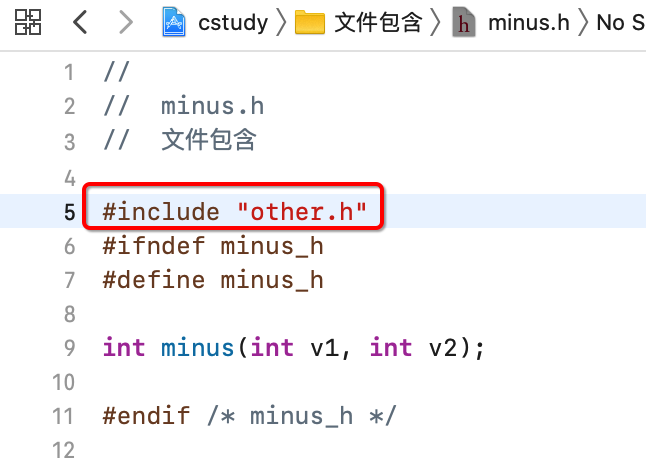
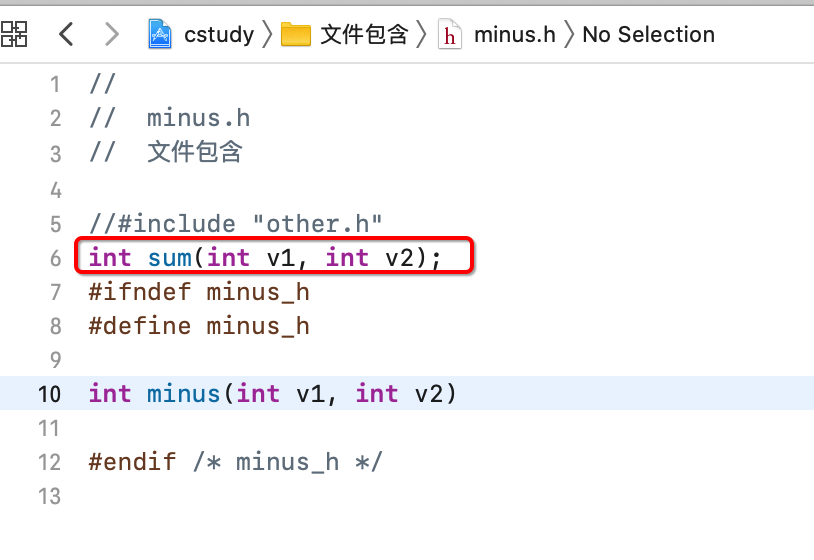
其实也很好理解,因为other.c中需要使用minus.h,而minus.h中也需要使用other.c,是不是相互依赖死循环了?那如何解决呢?也很简单,只需要单方面拷贝既可,像这样改:
最后,还有一个间接拷贝的含义,现在这个场景正好可以揭示:
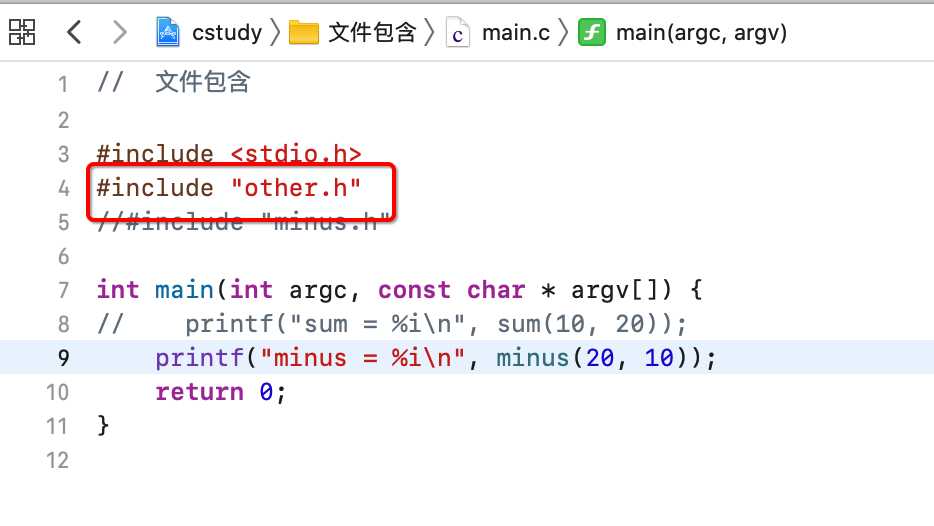
这里只包含了other.h对吧,而other.h中又间接地包含了minus.h:
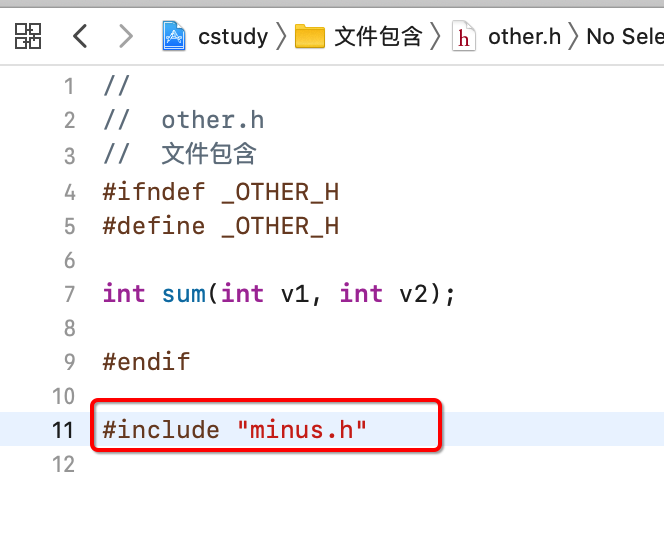
所以,等于main.c中包含了两个.h文件,minus.h就是其间接包含,了解一下。
typedef:
关于它其实就是取别名,这里直接上代码把一些关键点过一下。
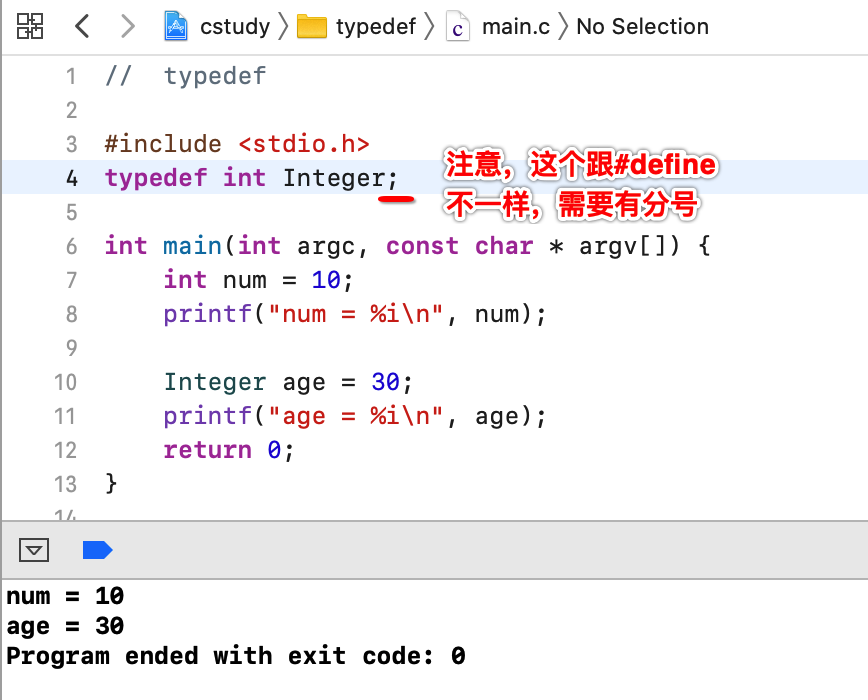
其中它还可以给自定义的类型再取别名,如:
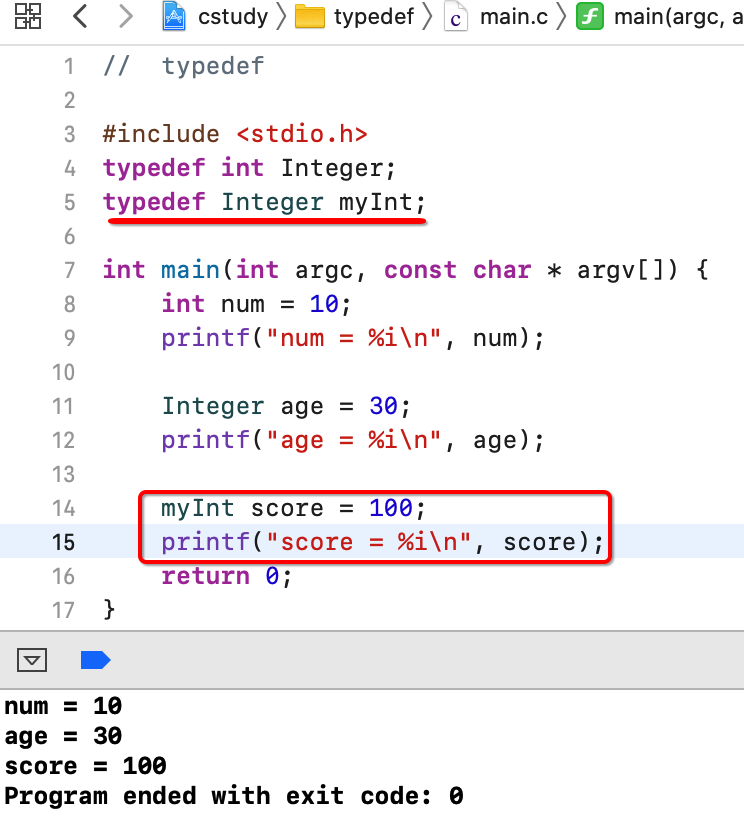
此时就可以给它取别名让其输写更加便捷:

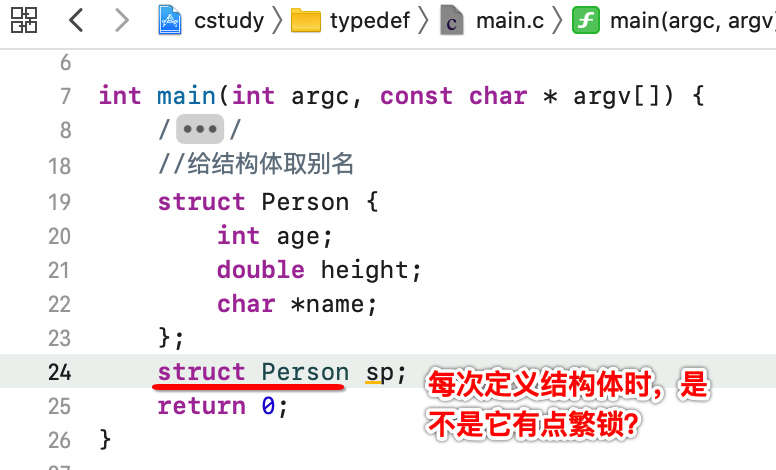
将Person的定义提到外面既可:
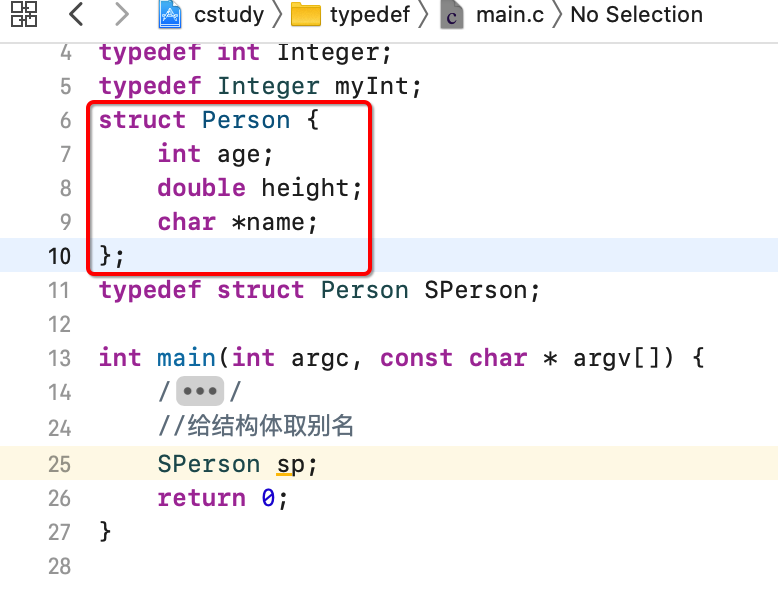
而由于结构体的定义有三种形式,所以对应的取别名还有另外两种形式,看一下:
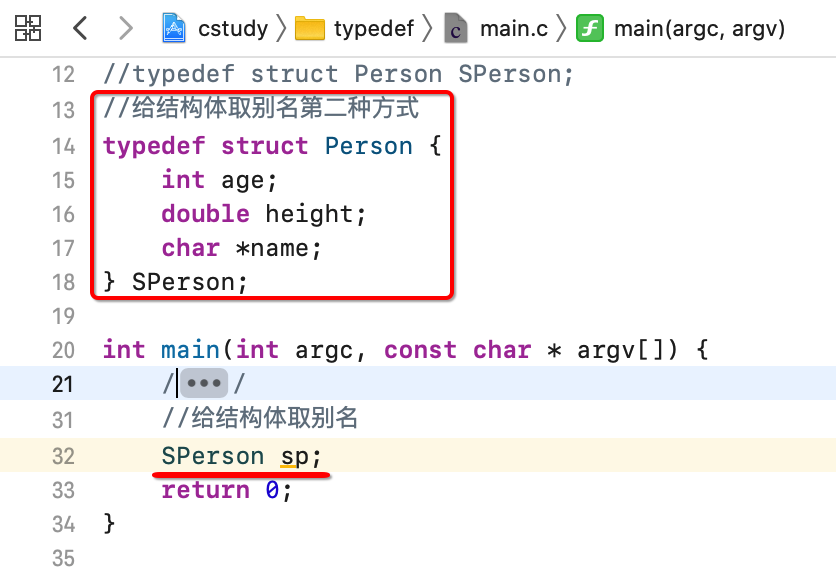
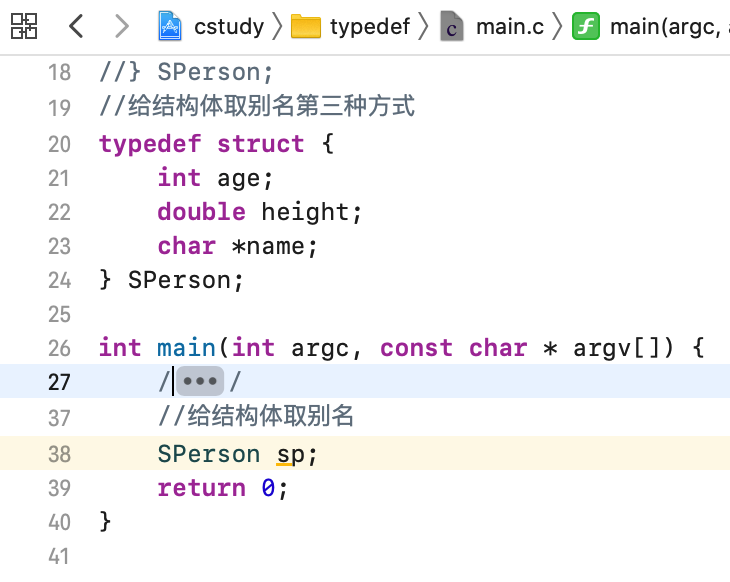
以上三种方式一定都要熟悉,因为未来都会用得到的。
给枚举取别名:
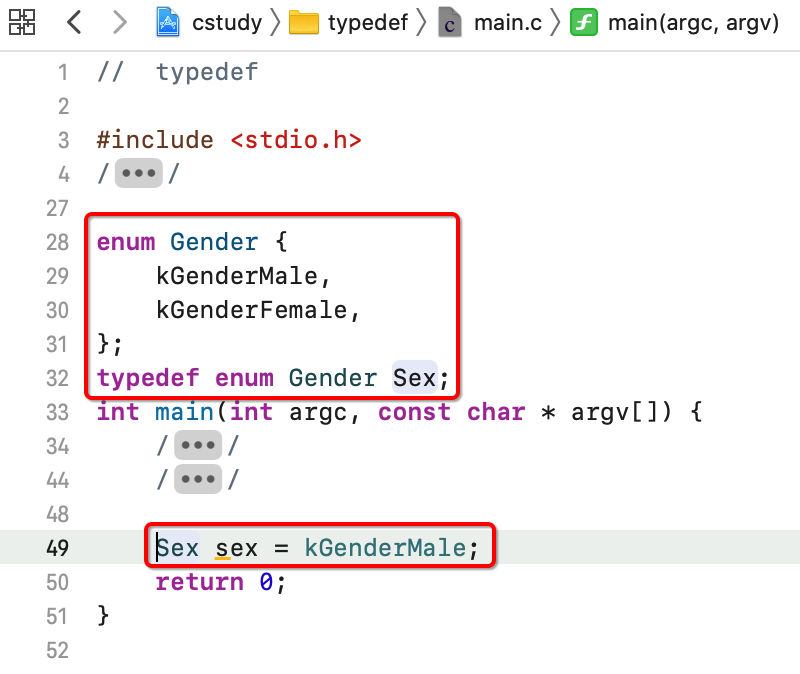
同样还有其它定义方式:
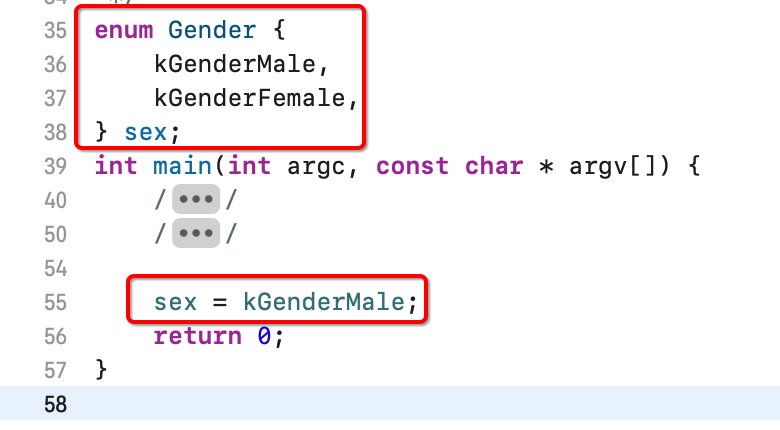
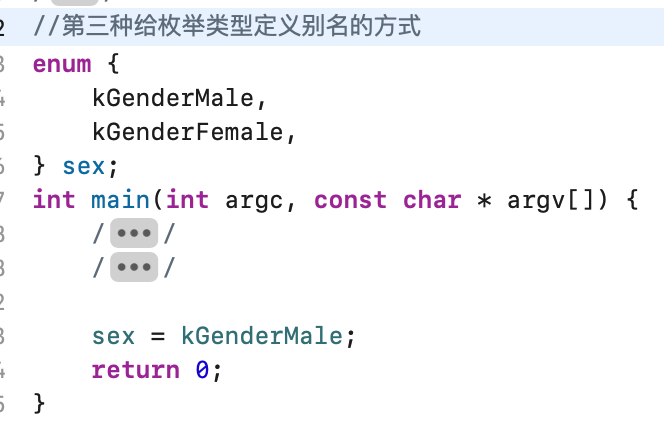
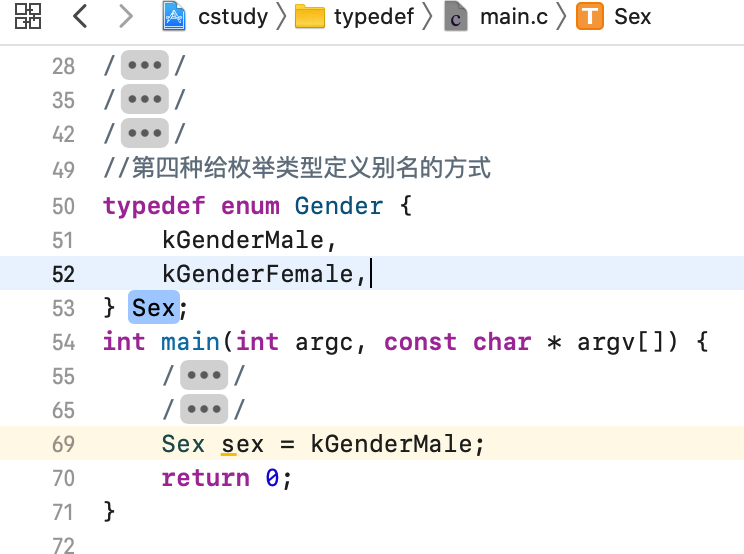
上面三种全是先定义枚举类型再给它取别名对吧,其实还可以在定义的同时取别名,如下:
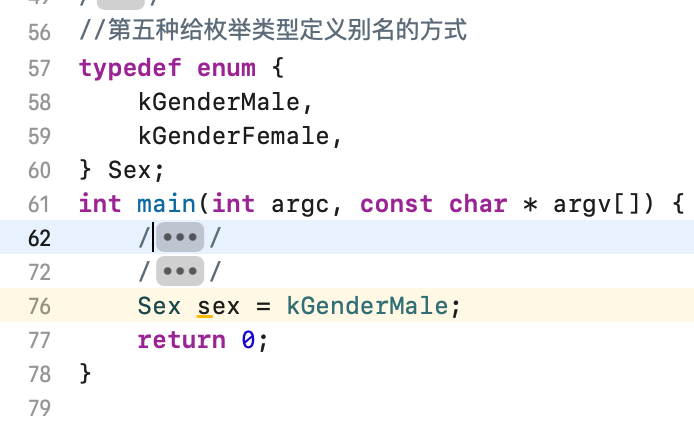
给指针取别名:
普通指针:

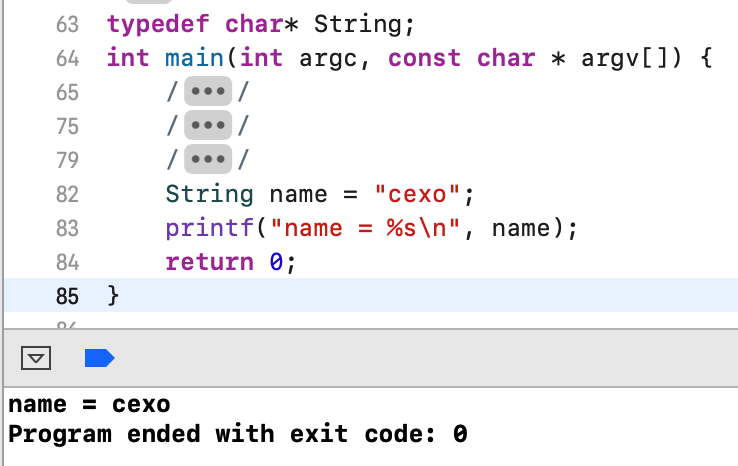
可能看着这指针*有点晕,于是乎可以给它也定义一个别名:
函数指针:【需掌握】
接下来还可以给函数指针取别名,这块需要好好掌握一下,本身写起来不是那么容易:
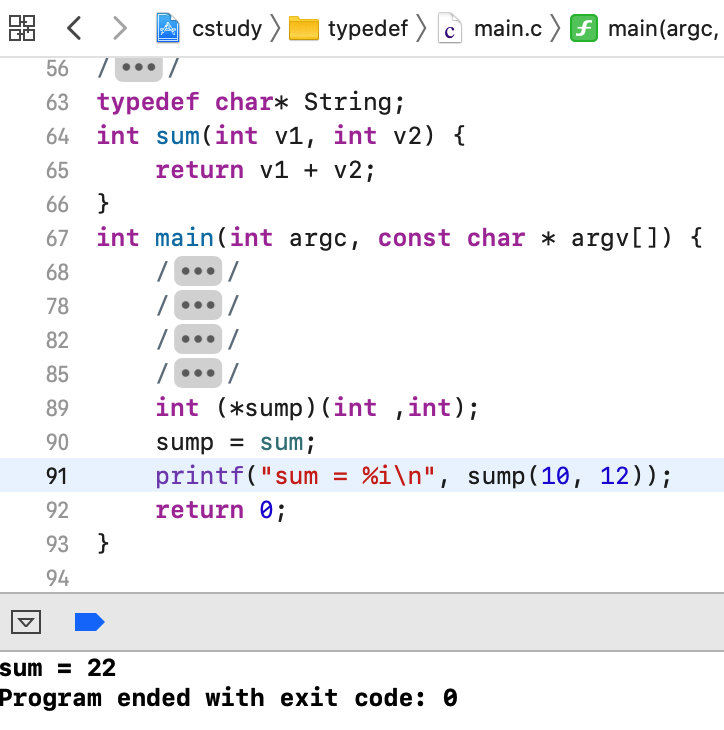
好,接下来又来了一个函数指针:
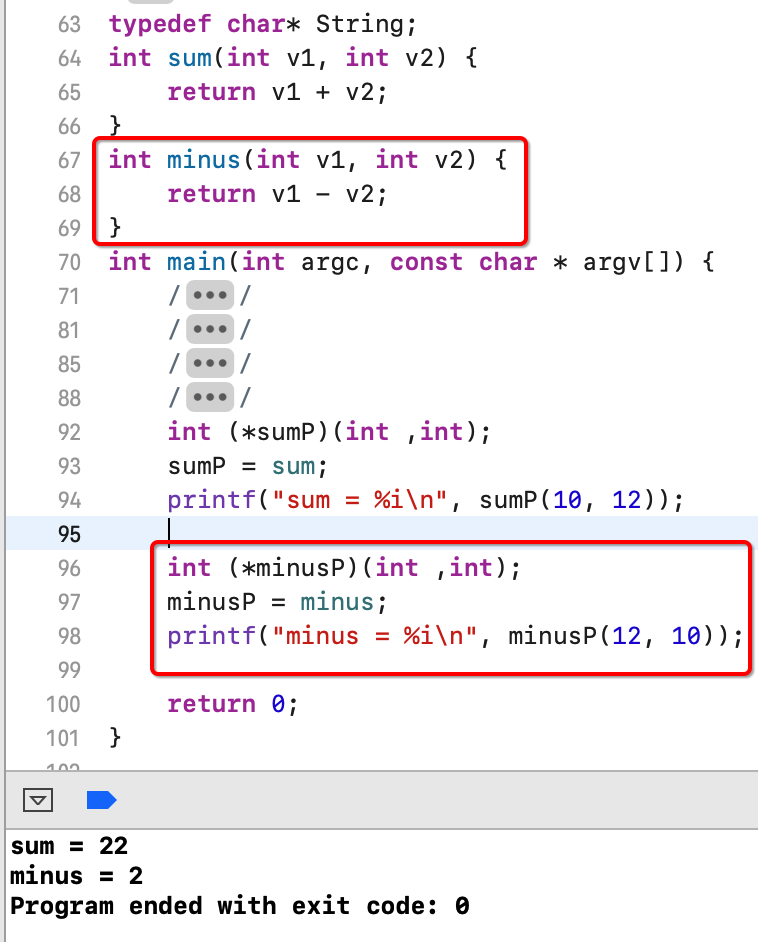
其中对于这两个函数指针的声明:
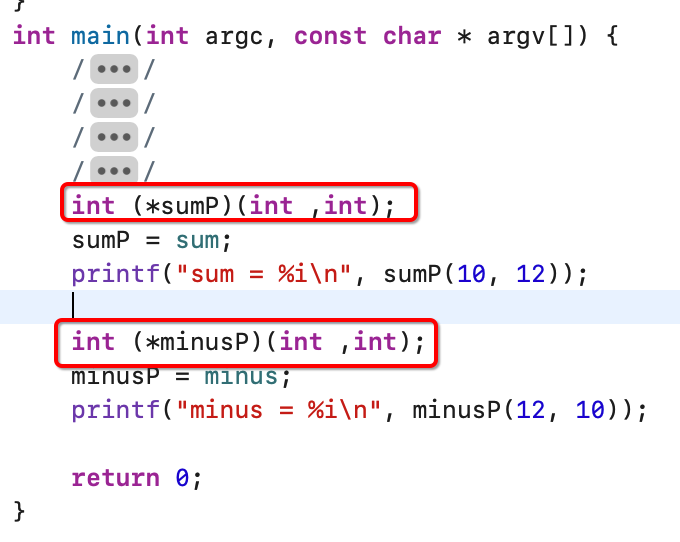
有木有发现这俩函数指针的定义就除了指类名称不一样,其它都一模一样对吧,此时就可以定义一个别名:
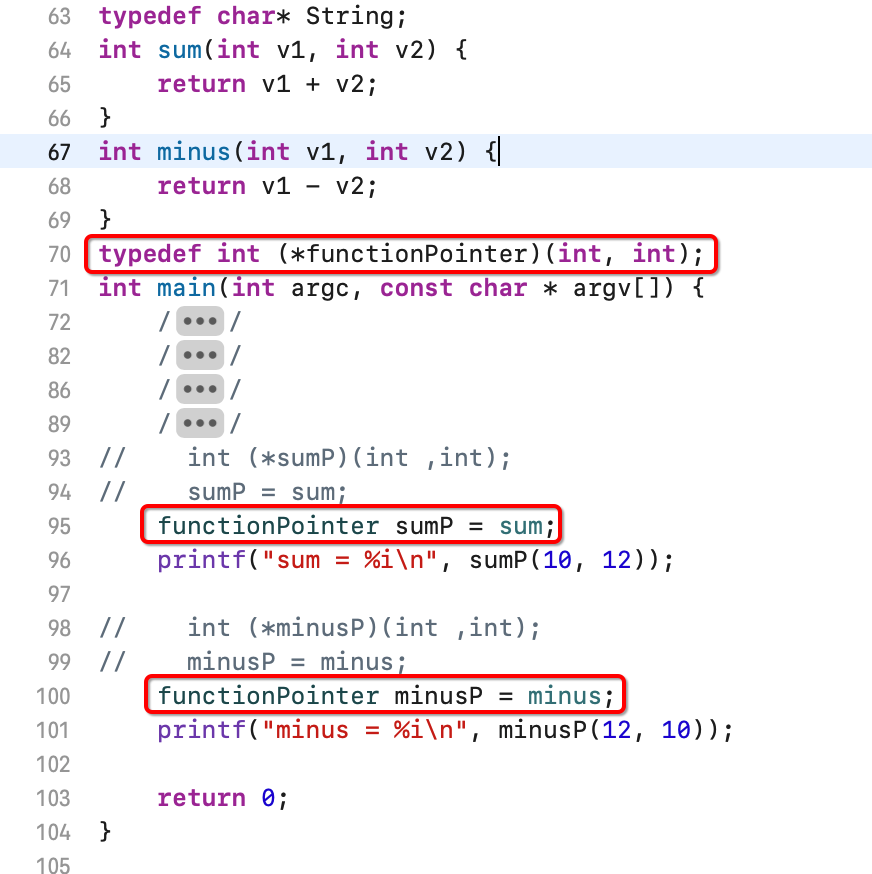
这个在实际中也是用得比较多的。
typedef和宏定义区别:
其实对于typedef定义别名,用宏定义也能达到类似的效果,下面看一下:
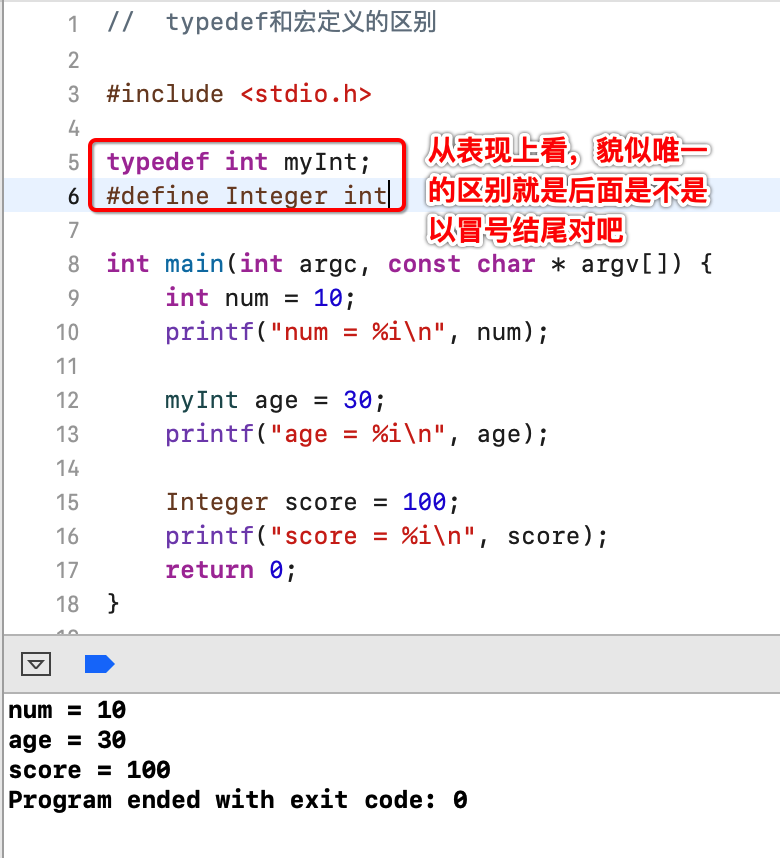
那。。这俩到底有啥区别呢?这里有一个原则 :一般情况下如果要给数据类型起一个别名建议用typedef,而不要用#define,下面再看一个例子:
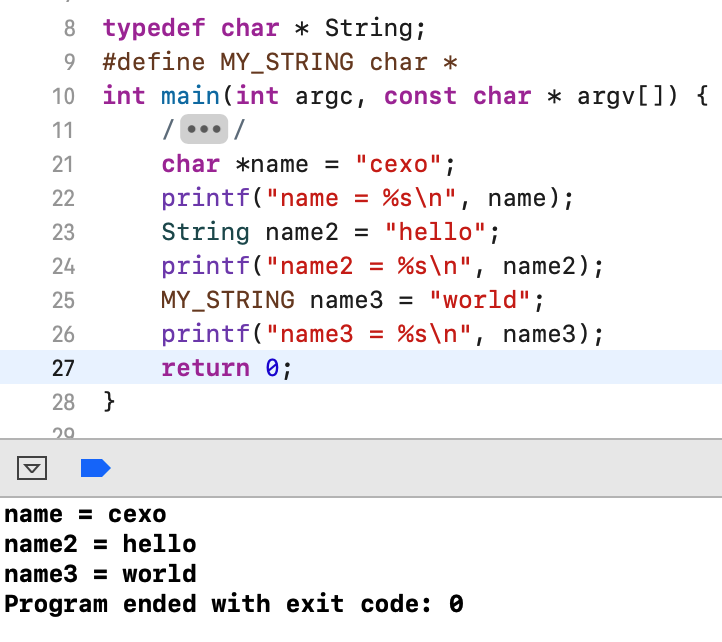
这貌似没看出啥问题对吧,好,下面再看:
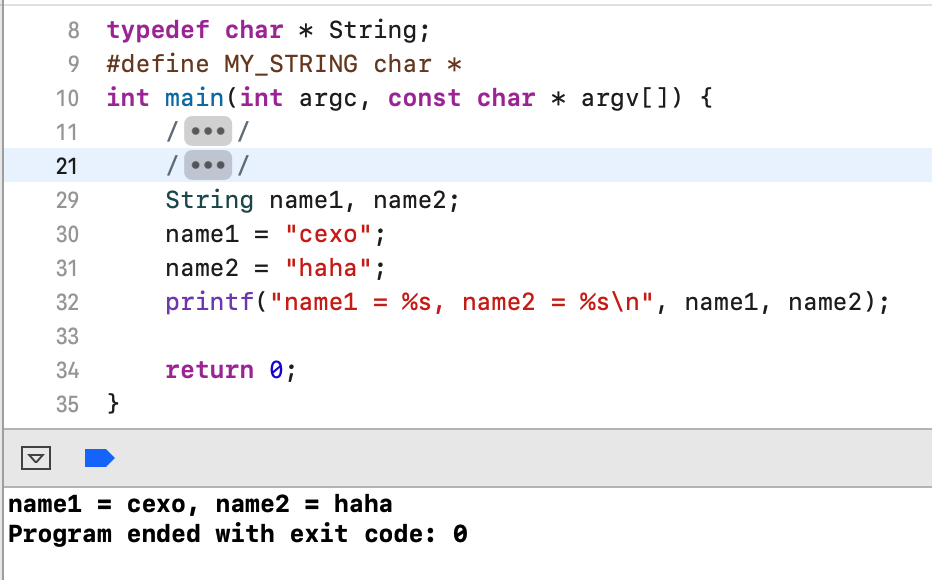
接下来再用宏定义:
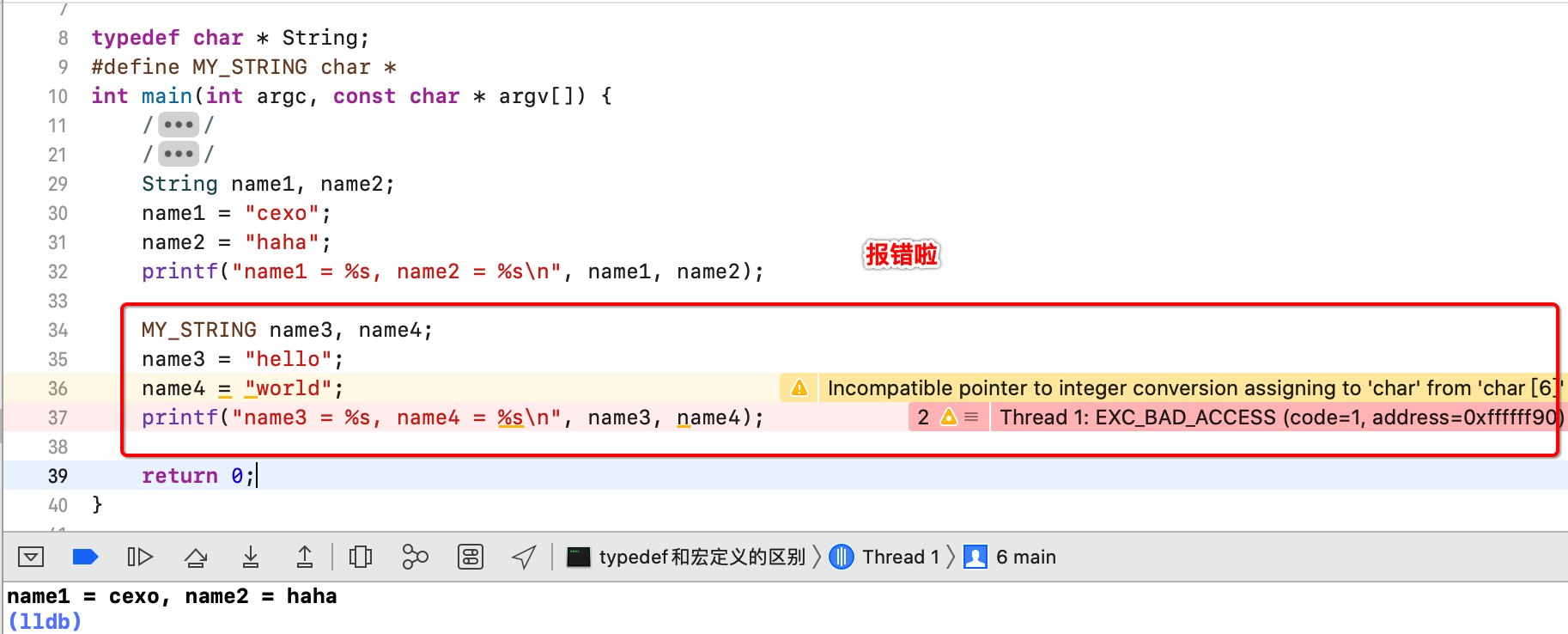
为啥会报错呢?其实也很容易想明白,宏定义本身就是字符替换,对于咱们这个程序替换之后的效果其实是:
很明显这样是有问题,所以记住这个原则既可,下面来总结一下区别。
typedef与函数的区别:
1> 宏定义不涉及存储空间的分配、参数类型匹配、参数传递、返回值问题
2> 函数调用在程序运行时执行,而宏替换只在编译预处理阶段进行。所以带参数的宏比函数具有更高的执行效率
typedef和#define的区别:
-
宏定义只是简单的字符串替换,
是在预处理完成的 -
typedef是在编译时处理的,它不是做简单的代换,
而是对类型说明符重新命名。被命名的标识符具有类型定义说明的功能
const关键字:
对于const也是实际会用得比较多的,所以也需要好好掌握。
基本概念:
- 使用const修饰变量则可以让变量的值不能改变。
- 常类型是指使用类型修饰符const说明的类型,常类型的变量或对象的值是不能被更新的。
const有什么主要的作用?
1、可以定义const常量,具有不可变性。 例如:
![]()
2、便于进行类型检查,使编译器对处理内容有更多了解,消除了一些隐患。
![]()
编译器就会知道i是一个常量,不允许修改。
3、可以避免意义模糊的数字出现,同样可以很方便地进行参数的调整和修改。 同宏定义一样,可以做到不变则已,一变都变!如(1)中,如果想修改Max的内容,只需要:const int Max=you want;即可。
4、可以保护被修饰的东西,防止意外的修改,增强程序的健壮性。 还是上面的例子,如果在 函数体内修改了i,编译器就会报错:
![]()
5、可以节省空间,避免不必要的内存分配:

6、提高了效率。编译器通常不为普通const常量分配存储空间,而是将它们保存在符号表中,这使得它成为一个编译期间的常量,没有了存储与读内存的操作,使得它的效率也很高。
使用const:
1、修饰一般常量一般常量是指简单类型的常量。这种常量在定义时,修饰符const可以用在类型说明符前,也可以用在类型说明符后。
![]()
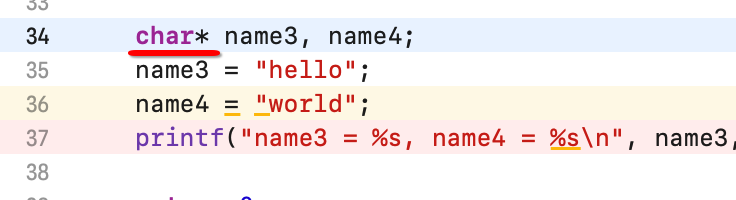
2、修饰常数组(值不能够再改变了)定义或说明一个常数组可采用如下格式:

3、
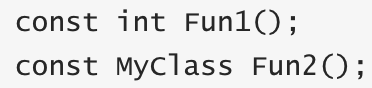
4、修饰函数的返回值: const修饰符也可以修饰函数的返回值,是返回值不可被改变,格式如下:
5、修饰常指针:【重点】
对于const使用最难的就是用在指针声明上了,下面好好学一下这块:
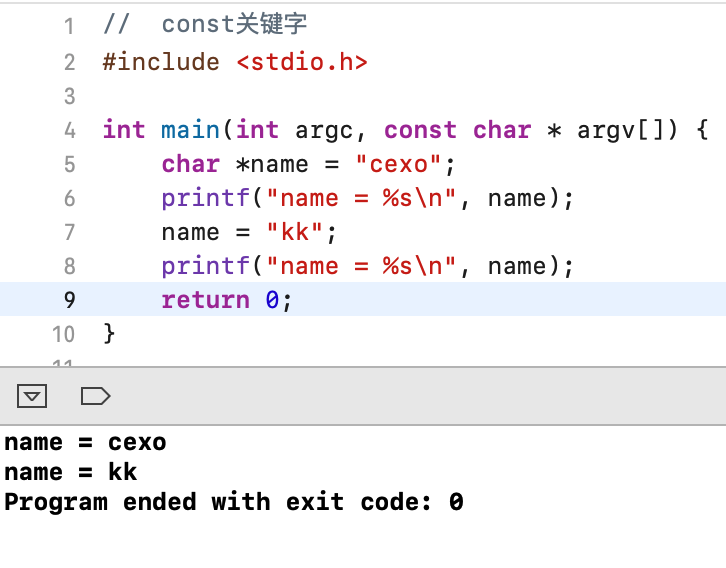
此时定义的指针内容是能够被更改对吧,那如果你不想让更改,此时就可以加上const关键字了,如下:
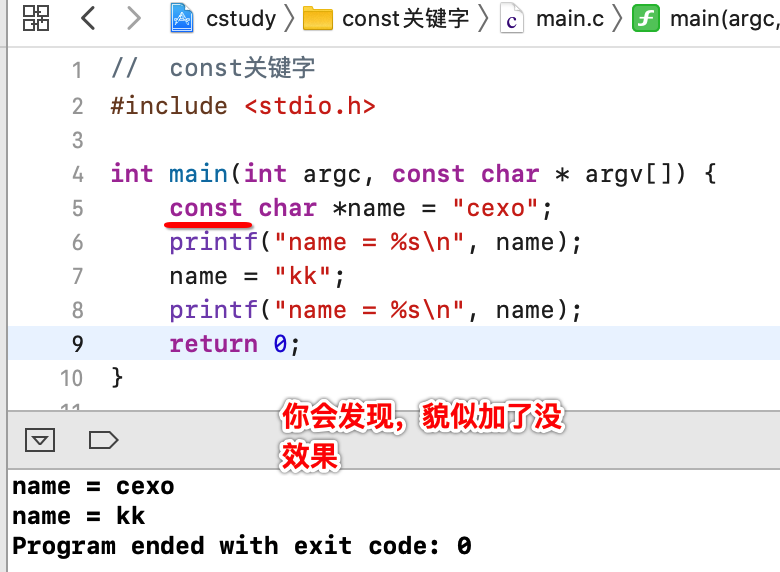
这是因为如果const写在指针类型的左边,则指针的指向可以变,但是指向的内存空间中的值是不能改变的,为了更好的理解,下面换一个程序,将其拆解一下:
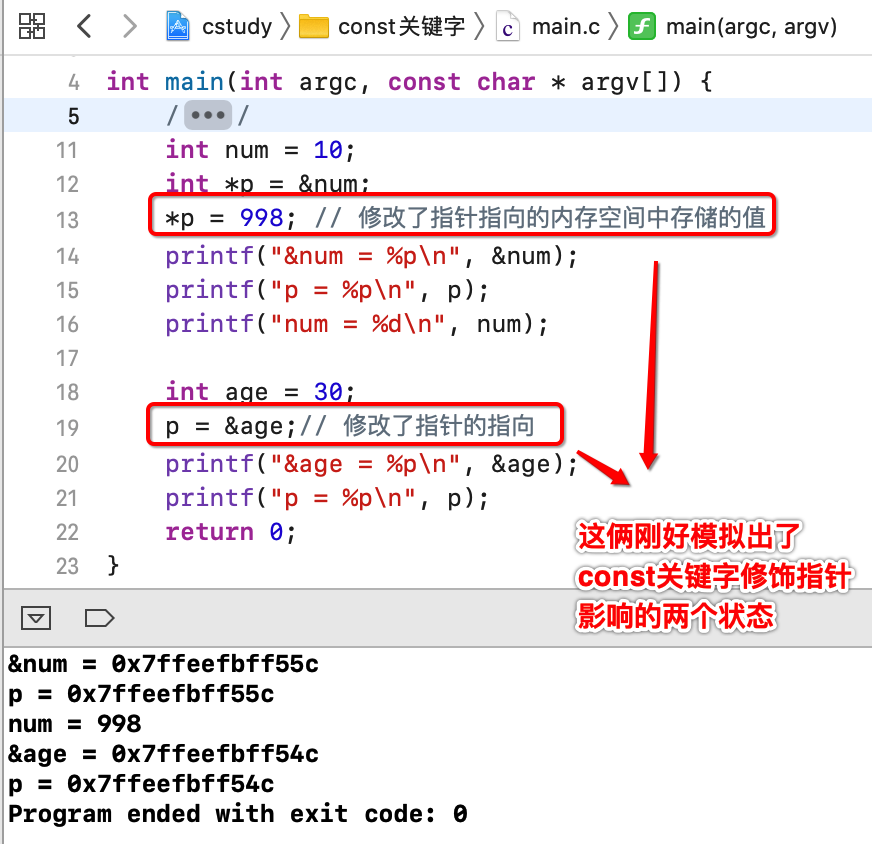
好,接下来加const啦:
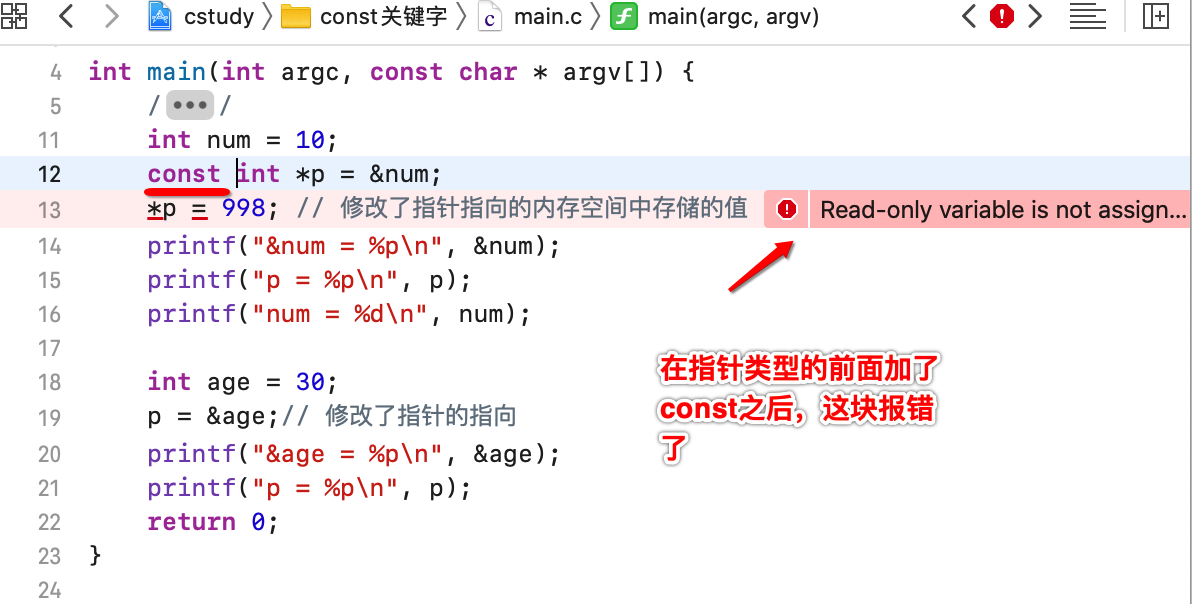
是不是这里可以说明:如果const写在指针类型的左边, 那么意味着指向的内存空间中的值不能改变, 但是指针的指向可以改变。
接下来继续修改:
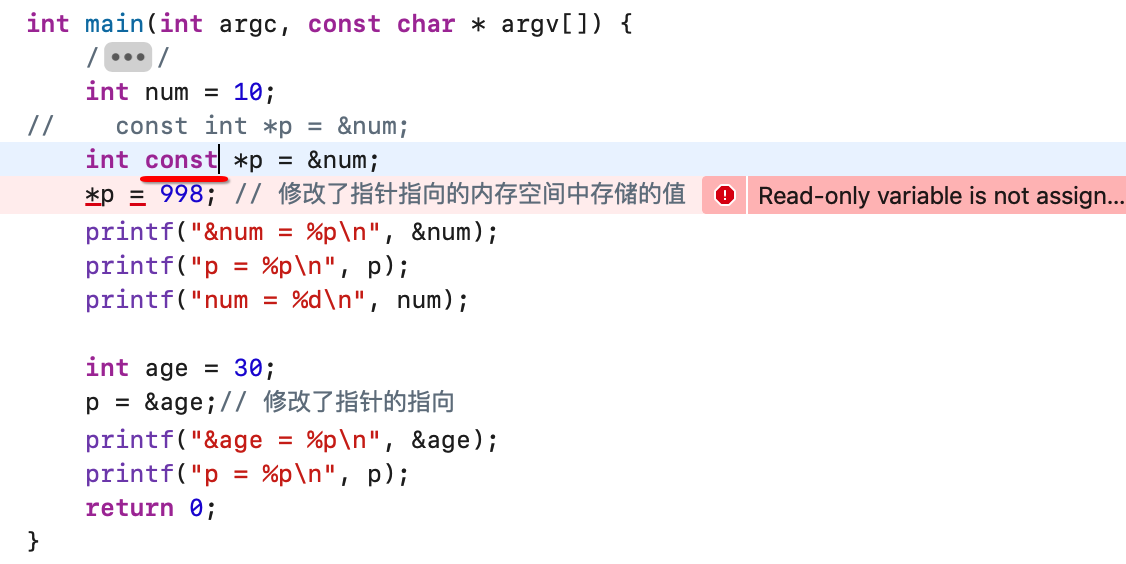
同样报错,这里又说明:如果const写在指针的数据类型和*号之间, 那么意味着指向的内存空间中的值不能改变, 但是指针的指向可以改变。
接下来再来修改:
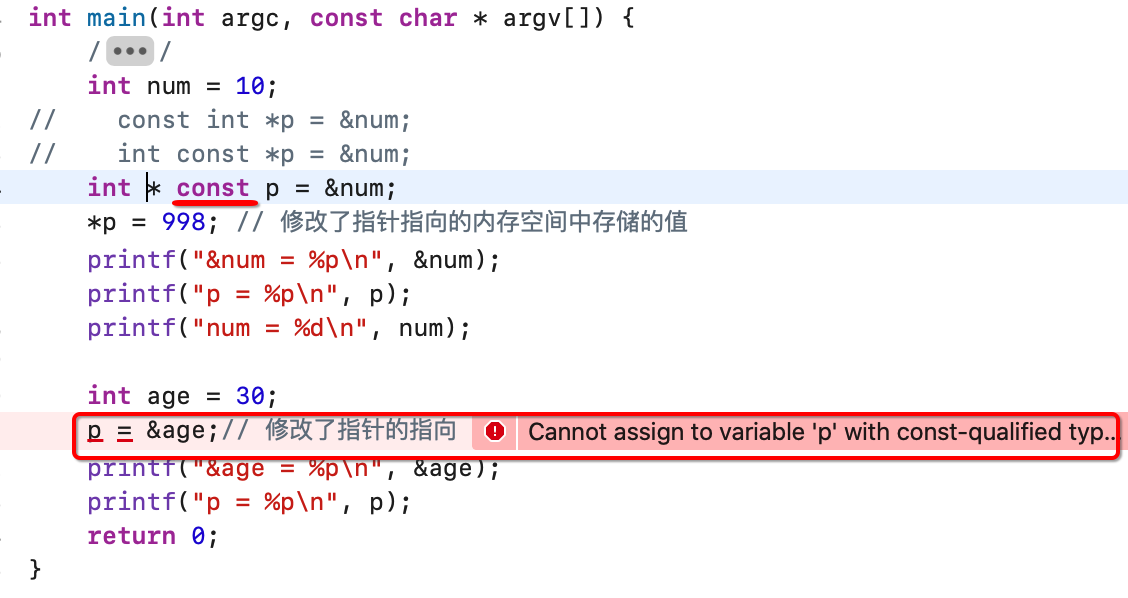
说明:如果const写在指针的右边(数据类型 * const), 那么意味着指针的指向不可以改变, 但是指针指向的存储空间中的值可以改变
所以对以上情况总结一下:
1、如果const写在指针类型的左边, 那么意味着指向的内存空间中的值不能改变, 但是指针的指向可以改变;
2、如果const写在指针的数据类型和*号之间, 那么意味着指向的内存空间中的值不能改变, 但是指针的指向可以改变;
3、如果const写在指针的右边(数据类型 * const), 那么意味着指针的指向不可以改变, 但是指针指向的存储空间中的值可以改变;
规律:
1、如果const写在指针变量名的旁边, 那么指针的指向不能变, 而指向的内存空间的值可以变;
2、如果const写在数据类型的左边或者右边, 那么指针的指向可以改变, 但是指向的内存空间的值不能改变;
其实有一种比较简单的记法就是:

只要const修饰的是指针变量名,那么就代表指针的指向是不能变,但其指向的存储空间的值可以变,除这种情况之外,都是相反的。
总结:
至此,终于把C基础相关的知识点基本给学完了,接下来则开启跟IOS相关的OC语言的学习了,回顾整个学习过程,说实话很多都不是很难,之前都有学过,但是也有很多新的知识点是之前不知道的,这就是所谓的温故知新吧,虽说整个学习的节奏非常慢【光C就学了一年多。。】,但是整个学习是比较踏实的,戒骄戒躁是学习任何技能的大前提,期待下次OC的学习之旅~~