谈谈openjdk:
在正式往下学习JVM之前,这里谈谈openjdk这个网站,这个在学习java并发时也用过它来分析过锁的底层实现,如:https://www.cnblogs.com/webor2006/p/11442551.html,为啥要说它,目前学习JVM已经记录了80多篇了,从纯小白到目前的学习貌似对JVM有东东了解得还不错了,但是!!其实还只是了解了个冰山一角,主要是JVM是一个太庞大的知识领域了,毕境不是真正在商业公司里做过JVM相关的工作,所以对于它的新知识在未来会一直出现,那在面对网上新出的一些理论上的说明,怎么知道它是真的还是假的,或者说这些理论的来源是在哪里呢?如果有想法验证的话就可以通过这个openjdk的底层JVM的源代码来进行,所以这里打开openjdk再提一下:


然后随便打开一个目录则就可以看到大量的底层C++实现:
谈这么一个小点就是假如未来想再进一步的探讨JVM自己来求验的话可以通过这种方式来进行,仅此而已。
G1回收器日志内容详细分析:
在前面学习了大量的关于G1收集器相关的理论之后,下面则编写一个实际的例子来看一下G1回收器产生日志跟之前咱们学习的其它的回收器产生的日志有啥区别,其实区别是非常之大的,如下:
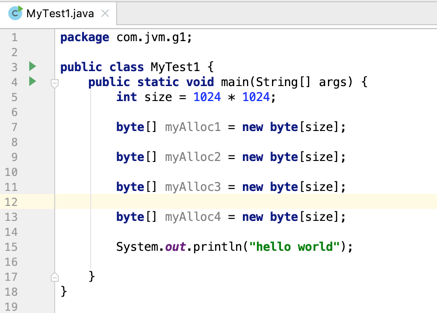
就是在内存中申请了4M的大小,如果不加任何参数运行当然比较简单:

好,接下来就是配置一下运行参数,我们目前用的JDK版本是1.8,默认它的收集器并非是G1收集器,而1.9之后则默认收集器就变为G1了,所以得显示的指定一下,如下:
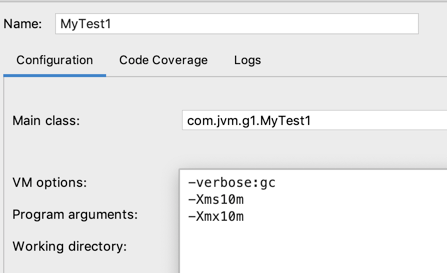
这三个参数之前都配过,这里再解释一下:
-verbose:gc:此代表会输出GC的详细日志。
-Xms10m、-Xmx10m:堆内存指定10m,不可以扩容,为了更容易打出相关日志这里将堆内存指定小一点。
接着第三个参数,这个就比较重要了:
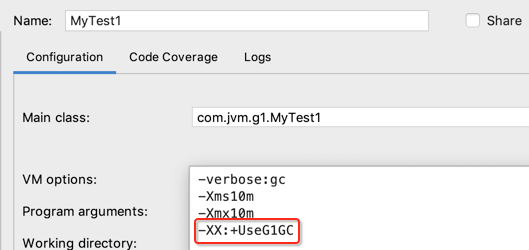
指定用G1垃圾收集器,接着再继续添加其它参数:
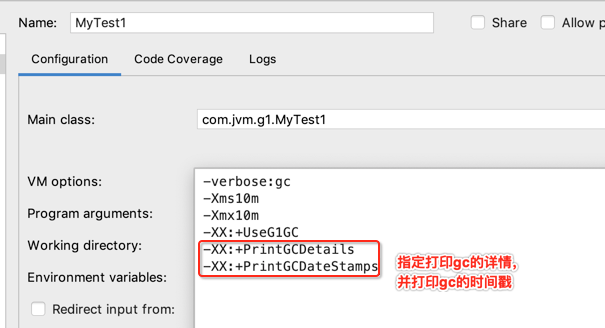
接下来再来指定最大的停顿时间,这个在之前的理论中也已经提及过,回忆下:
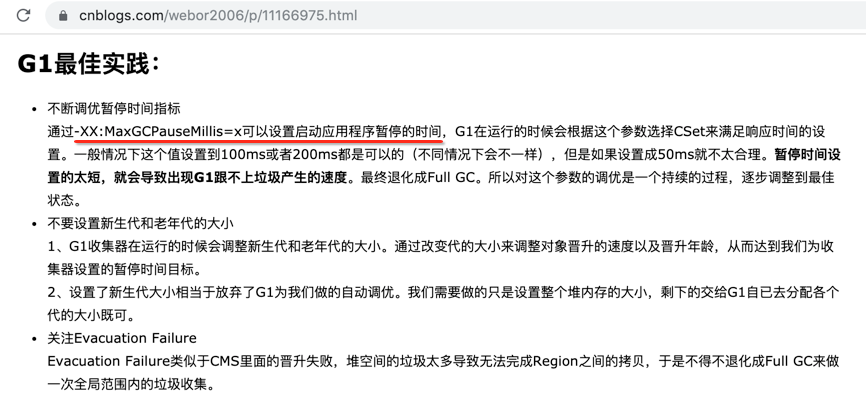
配置一下:

好,此时再运行一下:
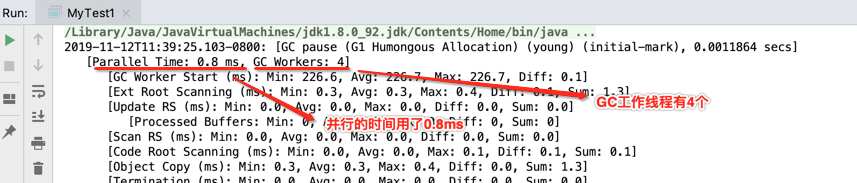
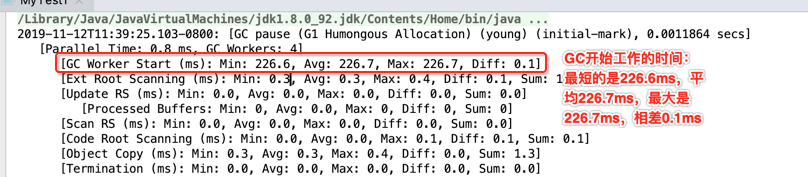
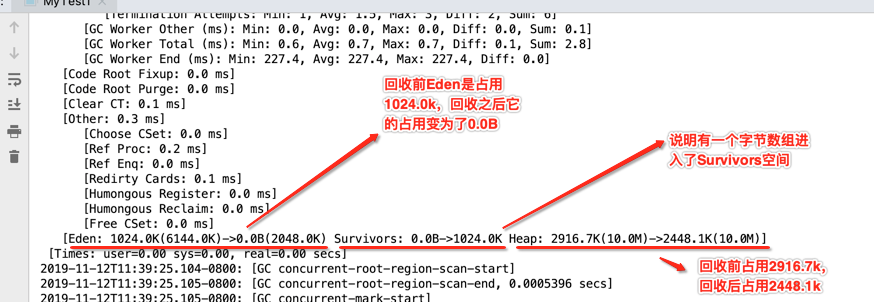
2019-11-12T11:39:25.103-0800: [GC pause (G1 Humongous Allocation) (young) (initial-mark), 0.0011864 secs] [Parallel Time: 0.8 ms, GC Workers: 4] [GC Worker Start (ms): Min: 226.6, Avg: 226.7, Max: 226.7, Diff: 0.1] [Ext Root Scanning (ms): Min: 0.3, Avg: 0.3, Max: 0.4, Diff: 0.1, Sum: 1.3] [Update RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0] [Processed Buffers: Min: 0, Avg: 0.0, Max: 0, Diff: 0, Sum: 0] [Scan RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0] [Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.1, Diff: 0.1, Sum: 0.1] [Object Copy (ms): Min: 0.3, Avg: 0.3, Max: 0.4, Diff: 0.0, Sum: 1.3] [Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0] [Termination Attempts: Min: 1, Avg: 1.5, Max: 3, Diff: 2, Sum: 6] [GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1] [GC Worker Total (ms): Min: 0.6, Avg: 0.7, Max: 0.7, Diff: 0.1, Sum: 2.8] [GC Worker End (ms): Min: 227.4, Avg: 227.4, Max: 227.4, Diff: 0.0] [Code Root Fixup: 0.0 ms] [Code Root Purge: 0.0 ms] [Clear CT: 0.1 ms] [Other: 0.3 ms] [Choose CSet: 0.0 ms] [Ref Proc: 0.2 ms] [Ref Enq: 0.0 ms] [Redirty Cards: 0.1 ms] [Humongous Register: 0.0 ms] [Humongous Reclaim: 0.0 ms] [Free CSet: 0.0 ms] [Eden: 1024.0K(6144.0K)->0.0B(2048.0K) Survivors: 0.0B->1024.0K Heap: 2916.7K(10.0M)->2448.1K(10.0M)] [Times: user=0.00 sys=0.00, real=0.00 secs] 2019-11-12T11:39:25.104-0800: [GC concurrent-root-region-scan-start] 2019-11-12T11:39:25.105-0800: [GC concurrent-root-region-scan-end, 0.0005396 secs] 2019-11-12T11:39:25.105-0800: [GC concurrent-mark-start] 2019-11-12T11:39:25.105-0800: [GC concurrent-mark-end, 0.0000373 secs] 2019-11-12T11:39:25.106-0800: [GC remark 2019-11-12T11:39:25.106-0800: [Finalize Marking, 0.0068794 secs] 2019-11-12T11:39:25.113-0800: [GC ref-proc, 0.0000470 secs] 2019-11-12T11:39:25.113-0800: [Unloading, 0.0008433 secs], 0.0080039 secs] [Times: user=0.00 sys=0.00, real=0.01 secs] 2019-11-12T11:39:25.114-0800: [GC cleanup 3472K->3472K(10M), 0.0002695 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] hello world Heap garbage-first heap total 10240K, used 4496K [0x00000007bf600000, 0x00000007bf700050, 0x00000007c0000000) region size 1024K, 2 young (2048K), 1 survivors (1024K) Metaspace used 2656K, capacity 4486K, committed 4864K, reserved 1056768K class space used 287K, capacity 386K, committed 512K, reserved 1048576K Process finished with exit code 0
呃,看着头晕。。输出了这么多信息。。要想理解G1,分析日志是必须经历过的,所以接下来硬着头皮大致来分析一下:
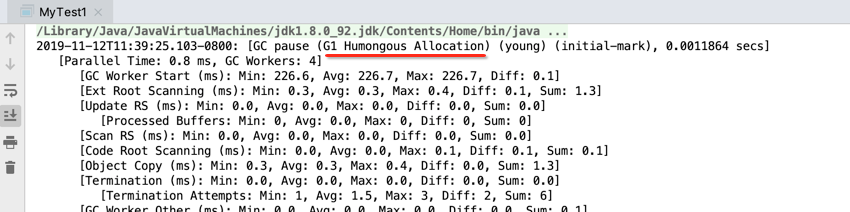
啥意思?这个得回忆一下之前学的理论了,当时提到过这个“Humongous”,https://www.cnblogs.com/webor2006/p/11142839.html,如下:

因为咱们每个数组都申请的1M,肯定是超出标准区域的50%,所以当成了巨大的区域了,所以日志中会有“Humongous”,继续分析:


这里回顾一下理论:


其实它刚好对应之前咱们学习的G1 Young GC的步骤之一,如下:
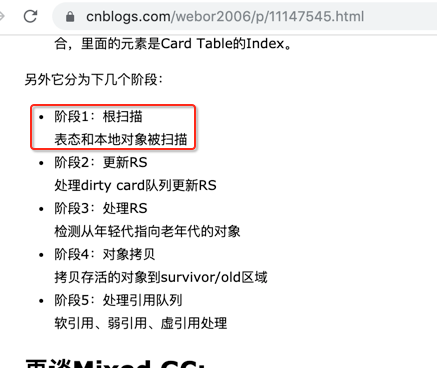

其中Rset是干啥用的,这里回忆一下,都是在之前的理论中有提及到的:

它其实就对应G1 Young GC的这个流程:
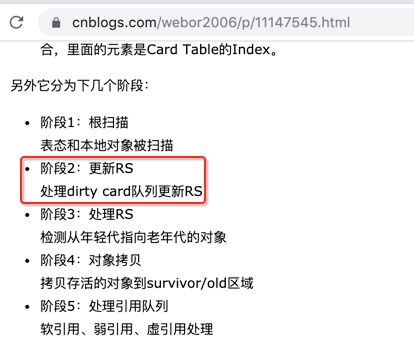
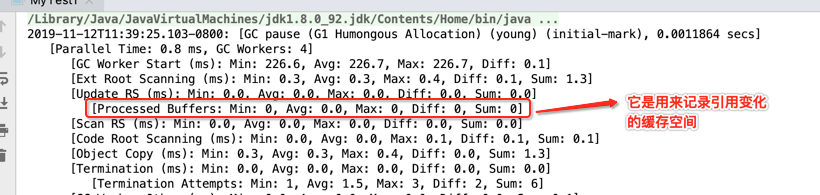
对应G1 Young GC这个流程:
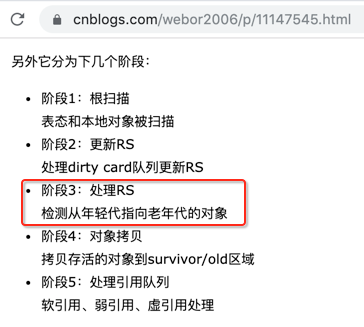
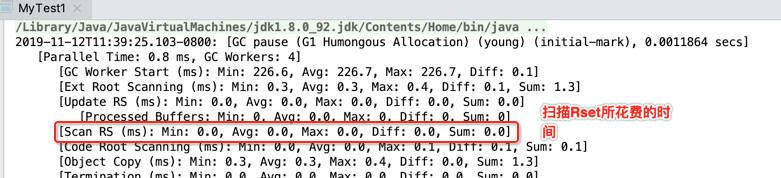

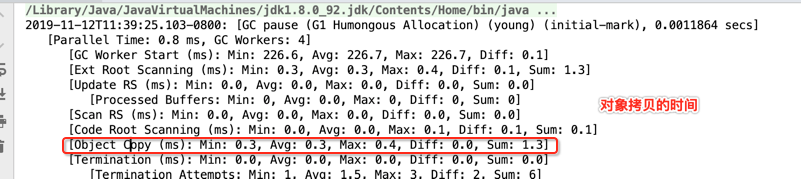
这块在之前G1 Young GC中也有提及,如下:

这里再来回顾个之前的东东,就是gc常见的算法有:

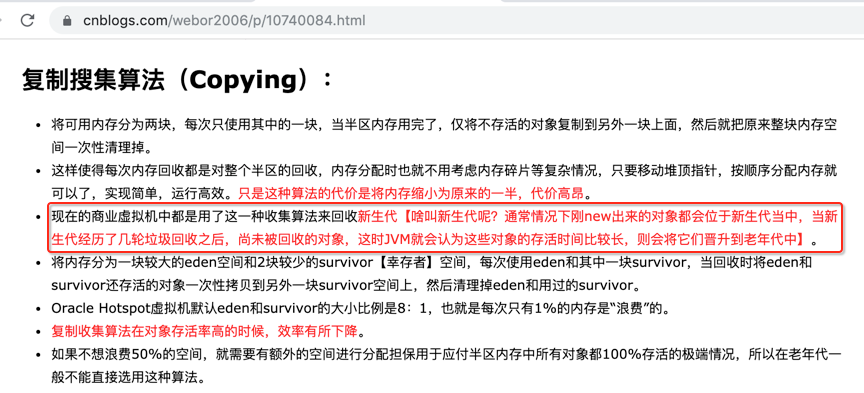
而且在老年代中不可能使用这个复制算法,所以再回顾一下这个图:

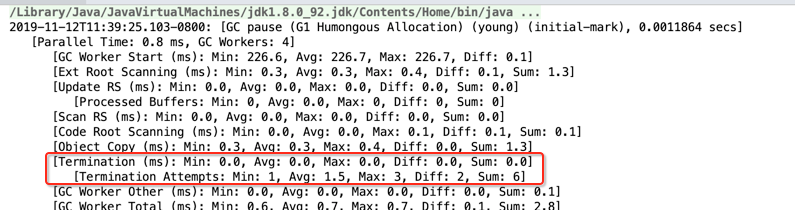
也就是对就G1 Young GC的最后一个步骤:

继续分析:
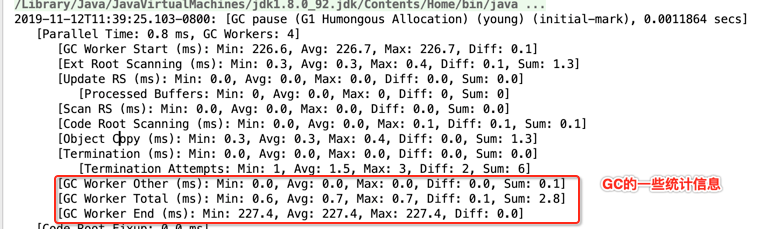
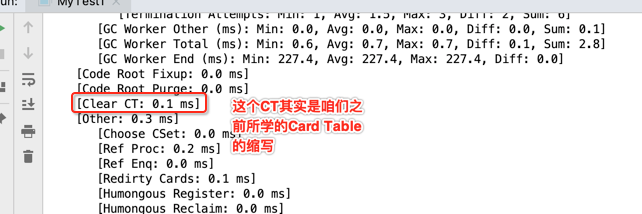
也是来自于G1 Young GC中的理论,回忆一下:
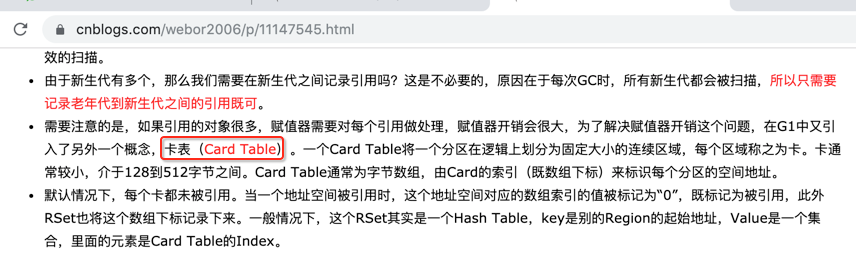
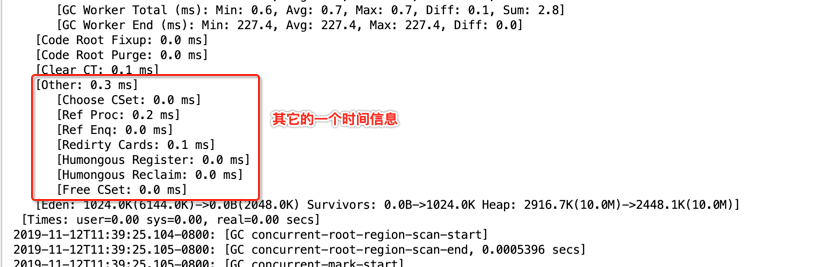
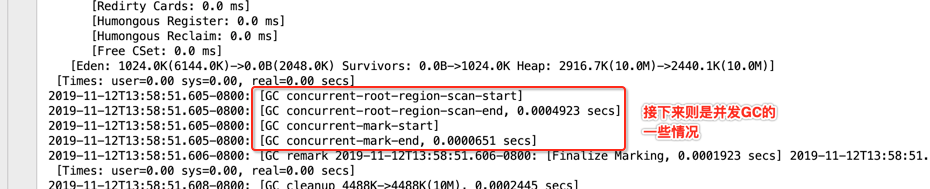

这些其实都是global concurrent marking的过程,回忆一下:

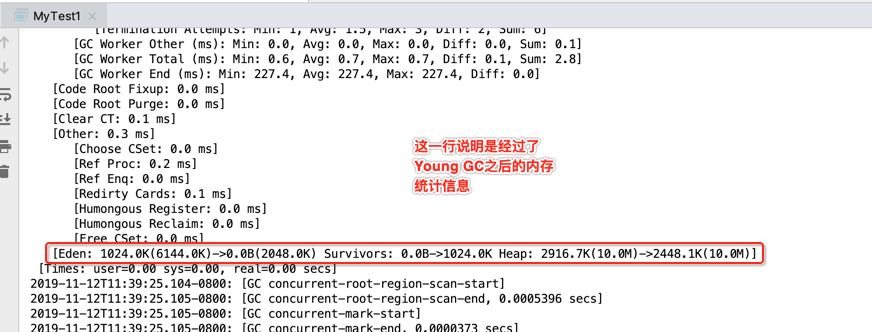
最后看一下整个堆的信息:

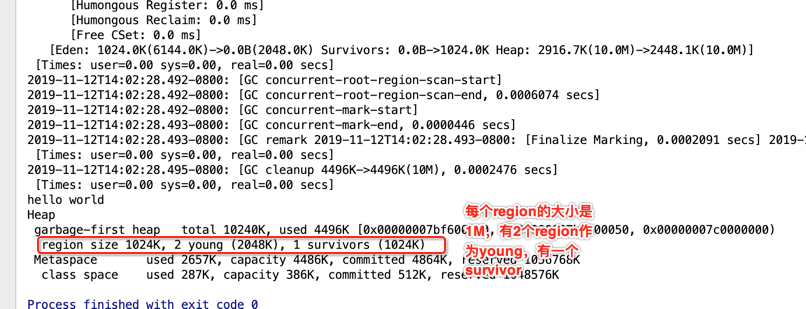
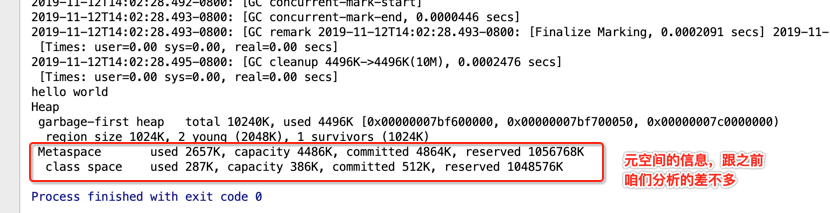
以上就是对于第一个G1日志的大体的认识,有很多细节还待未来进行进一步挖掘。