[原文源码下载]
[翻译]ASP.NET AJAX之内部揭秘
原文发布日期:2006.12.22
作者:About Omar Al Zabir
翻译:webabcd
审校:Tony Qu
介绍
微软最近发布了ASP.NET AJAX的Beta 2版。虽然它是一个非常强大的框架,但是当你在web 2.0的世界中要开发一个真正的AJAX web站点的话,就会遇到很多问题,而且你几乎找不到任何相关文档。本文中,我将介绍一些在开发Pageflakes中所学习到的高级经验。我们将会看到ASP.NET AJAX一些功能的优缺点,如批调用(Batch Call),调用超时,浏览器调用拥堵问题,ASP.NET 2.0中web service响应缓存的bug等等。
本文最后更新:2006年12月22日,针对ASP.NET AJAX RC更新(译注:适用于ASP.NET AJAX v1.0)
为什么要使用ASP.NET AJAX
一些人在看到Pageflakes的时候,首先问我的问题就是“为什么不使用Protopage或者Dojo库?而是Atlas?”微软的Atlas(已重命名为ASP.NET AJAX)是一个非常有前途的AJAX框架。微软为了这个框架做了很多努力,制作了大量可重用的组件,这样可以减少你的开发时间,这样的话,只要很少的工作量即可让你的web应用程序有一个完美的界面。它与ASP.NET融为一体,并且兼容ASP.NET的Membership和Profile。AJAX Control Toolkit项目包括了28个扩展(译注:现在有34个),你可以把它们拖拽到页面上,然后通过设置一些属性就可以产生非常酷的效果。看看那些例子你就会知道ASP.NET AJAX给我们带来了多么强大的功能。
在我们最初开发Pageflakes的时候,Atlas还处于幼儿阶段。我们只能使用page method和Web Service方法来调用Atlas的特性。我们不得不开发我们自己的拖拽、组件构造、弹出、伸缩/展开等特性。但是现在,Atlas提供了所有这些功能,所以可以大大节省我们的开发时间。最令人惊奇的是Atlas提供了web service代理的特性。你可以指定<script>标签到一个.asmx文件,然后你会得到一个JavaScript类,它会根据web service的定义被正确的生成。这使得添加或移除一个web service变得非常简单,而且你在web service中添加或移除方法都不需要客户端作任何改变。Atlas也提供了很多基于AJAX调用的控件,并且提供了在JavaScript中捕获丰富异常信息的特性。服务器端的异常可以被精确的抛给客户端的JavaScript代码,你可以捕获它们并格式化这些错误信息,然后显示给用户。Atlas与ASP.NET 2.0结合起来工作得非常出色,完全消除了整合问题。你不需要担心page method和web service的验证和授权问题,所以可以大大减少你的客户端代码的开发量(当然,也正是因为如此,Atlas运行时也变得非常巨大),相对于其它的AJAX框架来说,你可以把更多的精力放到自己的代码开发上来。
Atlas最近的版本可以与ASP.NET的Membership、Profile完美的结合,为你提供了在JavaScript中登录和注销的特性,而不用发postback给服务器,你也可以直接从JavaScript中读取和写入Profile。当你在web应用程序中使用Membership和Profile的时候,这将变得非常容易,例如我们做的Pageflakes
在Atlas的早些版本中,没有使用HTTP GET调用的方法。所有的调用都是HTTP POST,所以调用的代价是非常大的。而现在,你可以说,哪个调用是HTTP GET的(而哪个不是)。一旦你使用了HTTP GET,你就可以利用HTTP响应缓存特性,我将很快介绍这一特性。
批调用并不一定快
ASP.NET AJAX的CTP版本(之前的版本)里有一个特性,就是允许在一个请求里包含多个请求。它工作时你不会注意到任何事情,而且也不需要写任何特殊的代码。一旦你使用了批调用特性,那么在一次批调用期间,其中所有的web service调用都会被执行,所以它将减少回发时间和总响应时间。
实际的响应时间可能减少了,但是我们感觉到的延迟却变长了。如果有3个web service被批量调用,那么第一个调用不会最先完成,而是所有3个调用会在相同的时间完成。如果你的每一个web service调用完成后都更新UI的话,将不会一步一步更新,而是在所有调用一起完成后再一起更新UI。结果,你不会看到UI被快速更新,而是在UI被更新之前有一个长时间的延迟。如果说调用中的任何一个(比如第3个调用)下载了大量数据,那么在所有的3个调用完成之前用户不会看到任何变化。所以第一个调用的执行时间几乎接近3个调用的总执行时间。虽然减少了实际的总计处理时间,但是会感觉有更长的延迟。当每个调用都只传输少量数据的时候批调用是非常好的,这样,3个小型调用就会在一次回发中执行完。
让我们看看3个调用是如何一个一个被完成的,这将说明这些调用实际上是如何被执行的。

第二个调用到达服务端的时间要比第一个调用长,因为第一个调用吃光了带宽。同样的原因,下载也就会花更多的时间。浏览器同时打开了两个连接到服务器端的连接,所以在同一时间,只能处理两个调用。一旦第一个调用或第二个调用完成后,第三个调用才能被处理。
当3个web service在一次请求中被批调用的时候:

这里总计下载时间将会有所减少(如果IIS的压缩功能启用的话),并且只需一次网络响应。所有的3个调用一次被发往到服务端后全部执行,组合而成的三个调用的响应是在一次调用中下载。但是对于用户来讲,他们会感觉速度变慢了,因为UI的更新发生在所有批调用完成之后。这个批调用完成的总时间总是要长于两个调用的。并且,如果你有大量的一个又一个的UI更新,IE将会冻结一段时间,这将给用户带来一个糟糕的体验。一些时候,时间较长的UI更新会导致浏览器出现“白屏”,但是FireFox和Opera不会有此问题。
批调用也是有一些优点的。如果你的IIS启用了gzip压缩功能的话,将对全部结果进行压缩而不是分别压缩每个结果,那么总下载时长就会少于单独调用的下载时长。所以,通常批调用都是一些小型调用的话会比较好。但是如果调用会发送或者返回较大数据的话,比如20KB,那么最好就别使用批调用了。批调用还有另一个问题,比如说前两个调用非常小,第3个调用十分大,如果这3个调用被批调用的话,那么前两个小的调用就要延迟很长时间,因为第3个很大。
糟糕的调用会使好的调用超时
如果有两个HTTP调用不知何故执行了很长的时间,那么这两个糟糕的调用也将会使好的调用超时,同时这两个调用会进入队列。这里就有一个例子:
 function TestTimeout()
function TestTimeout() {
{

 debug.trace("--Start--"); TestService.set_defaultFailedCallback( function(result, userContext, methodName)
debug.trace("--Start--"); TestService.set_defaultFailedCallback( function(result, userContext, methodName) {
{ var timedOut = result.get_timedOut(); if( timedOut ) debug.trace( "Timedout: " + methodName ); else debug.trace( "Error: " + methodName );
var timedOut = result.get_timedOut(); if( timedOut ) debug.trace( "Timedout: " + methodName ); else debug.trace( "Error: " + methodName ); }); TestService.set_defaultSucceededCallback( function(result) { debug.trace( result ); }); TestService.set_timeout(5000); TestService.HelloWorld("Call 1"); TestService.Timeout("Call 2"); TestService.Timeout("Call 3"); TestService.HelloWorld("Call 4"); TestService.HelloWorld("Call 5"); TestService.HelloWorld(null); // 这句将导致错误
}); TestService.set_defaultSucceededCallback( function(result) { debug.trace( result ); }); TestService.set_timeout(5000); TestService.HelloWorld("Call 1"); TestService.Timeout("Call 2"); TestService.Timeout("Call 3"); TestService.HelloWorld("Call 4"); TestService.HelloWorld("Call 5"); TestService.HelloWorld(null); // 这句将导致错误 }
}服务端的web service也非常简单:
[WebService(Namespace = "http://tempuri.org/")][WebServiceBinding(ConformsTo = WsiProfiles.BasicProfile1_1)][ScriptService]public class TestService : System.Web.Services.WebService { public TestService () { // 如果使用设计的组件,请取消注释以下行 // InitializeComponent(); } [WebMethod][ScriptMethod(UseHttpGet=true)] public string HelloWorld(string param) { Thread.Sleep(1000); return param; } [WebMethod][ScriptMethod(UseHttpGet=true)] public string Timeout(string param) { Thread.Sleep(10000); return param; }}我调用了服务端的名为“Timeout”的方法,它不会做任何事情,而只是等待一个较长的时间以使调用超时。之后,我再调用一个不会超时的方法。但是你猜猜输出的是什么:
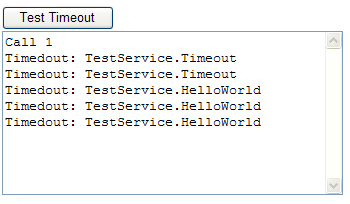
只有第一个调用成功了。所以,任何时候如果浏览器的两个连接都处在拥堵状态的话,那么你期待的其他调用也都将会超时。
在Pageflakes的运营中,我们曾经几乎每天都从客户端得到400个到600个超时错误报告,我们从未发现这是怎么发生的。起初,我们怀疑是互联网连接过慢造成的,但是不可能如此多的用户都发生这种情况。后来,我们猜测是主机提供商的网络出现了问题。我们做了大量的网络析去发现问题是否是出现在网络上,但是我们没有发现任何异常。我们使用了SQL Profiler去查找是否是长时间运行的查询导致了ASP.NET请求执行时的超时。但是不幸,我们最终发现的是,大部分超时错误出现的情况都是先有一些坏的调用,然后好的调用也超时了。所以我们修改了Atlas运行时,引进了自动重试的功能,问题终于完全消失了。然而,自动重试需要对ASP.NET AJAX框架的Javascript做一次“心脏外科手术”,这个方法会要求每个调用在超时后都重试一次。为了实现它,我们需要截获所有web method调用并且在onFailure回调函数中作个钩子,如果失败的原因是超时,onFailure将再次调用相同的web method
另一个需要关注的发现是当我们外出旅行感到疲惫时,想通过酒店或机场的无线网络连接到互联网访问Pageflakes的时候,首次访问总是不成功,并且所有的web service调用在第一次尝试中总是失败。直到我们刷新之前都不会工作。这也是我们要实现web service调用立即自动重试的另一个主要原因,它正好可以解决这个问题。
这里我会告诉你怎么做。Sys$Net$WebServiceProxy$invoke函数是负责处理所有web service调用的。所以,我们需要通过一个自定义onFailure回调函数来替换这个函数。只要有错误或者超时就会激发这个自定义回调函数。所以,当有超时发生的时候,就会再次调用这个函数,重试就会发生。
Sys.Net.WebServiceProxy.retryOnFailure = function(result, userContext, methodName, retryParams, onFailure){ if( result.get_timedOut() ) { if( typeof retryParams != "undefined" ) { debug.trace("Retry: " + methodName); Sys.Net.WebServiceProxy.original_invoke.apply(this, retryParams ); } else { if( onFailure ) onFailure(result, userContext, methodName); } } else { if( onFailure ) onFailure(result, userContext, methodName); }}Sys.Net.WebServiceProxy.original_invoke = Sys.Net.WebServiceProxy.invoke;Sys.Net.WebServiceProxy.invoke = function Sys$Net$WebServiceProxy$invoke(servicePath, methodName, useGet, params, onSuccess, onFailure, userContext, timeout){ var retryParams = [ servicePath, methodName, useGet, params, onSuccess, onFailure, userContext, timeout ]; // 初始调用失败 // 处理自动重试 var newOnFailure = Function.createDelegate( this, function(result, userContext, methodName) { Sys.Net.WebServiceProxy.retryOnFailure(result, userContext, methodName, retryParams, onFailure); } ); Sys.Net.WebServiceProxy.original_invoke(servicePath, methodName, useGet, params, onSuccess, newOnFailure, userContext, timeout);}运行的时候,它将把每个超时调用都重试一次
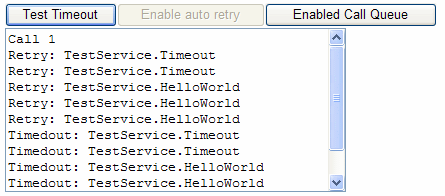
这里你可以看到第一个方法成功了,所有其他超时的调用都会被重试。而且你也会看到重试一次后的调用都成功了。发生这种情况是因为在重试中服务端的方法不会做超时处理。所以,这证明了我们的实现方法是正确的。
浏览器只允许同一时间内有两个调用,此时不会执行其他任何命令
浏览器在同一时间内只能对一个域名处理两个并发的AJAX调用。如果你有5个AJAX调用,那么浏览器首先将会处理两个,然后等其中一个完成后,再处理另一个调用,直到剩下的4个调用都被完成。此外,你不要指望调用的执行顺序会与你处理调用的顺序相同,这是为什么呢?
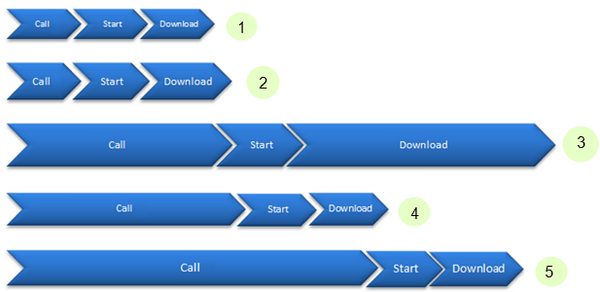
正如你所见,调用3需要下载比较大的数据,所以它所需的时间就会比调用5要长,事实上,调用5会在调用3之前执行完。
所以,在HTTP的世界里,这些都是不可预知的。
当队列里有多于两个调用的时候浏览器将不会响应
尝试这样做,在首次访问时打开任何一个加载了大量RSS的页(如Pageflakes, Netvibes, Protopage),在加载期间,你可以尝试着单击一个链接到另一个站点或者试着直接访问另一个站点,那么你就会发现浏览器不会有任何响应。直到浏览器里所有队列的AJAX调用都完成之后,浏览器才能接受另一个活动。这是IE的一个比较糟糕的地方,但是Firefox和Opera就不会有此问题。
这个问题是,当你有大量的AJAX调用的时候,浏览器会将所有的调用放到一个队列里,在同一时间内只执行其中的两个。所以,如果你单击了某个链接或者转向另一个站点,那么浏览器必须等待在得到另一个调用之前正在执行的调用完成之后才会去处理。解决这个问题的办法就是防止浏览器在同一时间内有多于两个的调用在队列里。我们需要维持一个自己的队列,然后从我们的队列里将一个一个调用的发到浏览器的队列中。
这个解决方案是很棒,它可以防止调用间的冲突:
var GlobalCallQueue = { _callQueue : [], // 保存web method的调用列表 _callInProgress : 0, // 浏览器目前处理的web method的编号 _maxConcurrentCall : 2, // 同一时间内执行调用的最大数 _delayBetweenCalls : 50, // 调用执行之间的延迟 call : function(servicePath, methodName, useGet, params, onSuccess, onFailure, userContext, timeout) { var queuedCall = new QueuedCall(servicePath, methodName, useGet, params, onSuccess, onFailure, userContext, timeout); Array.add(GlobalCallQueue._callQueue,queuedCall); GlobalCallQueue.run(); }, run : function() { /// 从队列里执行一个调用 if( 0 == GlobalCallQueue._callQueue.length ) return; if( GlobalCallQueue._callInProgress < GlobalCallQueue._maxConcurrentCall ) { GlobalCallQueue._callInProgress ++; // 得到第一个调用队列 var queuedCall = GlobalCallQueue._callQueue[0]; Array.removeAt( GlobalCallQueue._callQueue, 0 ); // 调用web method queuedCall.execute(); } else { // 达到最大并发数,不能运行另一个调用 // 处理中的webservice method } }, callComplete : function() { GlobalCallQueue._callInProgress --; GlobalCallQueue.run(); }};QueuedCall = function( servicePath, methodName, useGet, params, onSuccess, onFailure, userContext, timeout ){ this._servicePath = servicePath; this._methodName = methodName; this._useGet = useGet; this._params = params; this._onSuccess = onSuccess; this._onFailure = onFailure; this._userContext = userContext; this._timeout = timeout;}QueuedCall.prototype = { execute : function() { Sys.Net.WebServiceProxy.original_invoke( this._servicePath, this._methodName, this._useGet, this._params, Function.createDelegate(this, this.onSuccess), // 调用处理完成 Function.createDelegate(this, this.onFailure), // 调用处理完成 this._userContext, this._timeout ); }, onSuccess : function(result, userContext, methodName) { this._onSuccess(result, userContext, methodName); GlobalCallQueue.callComplete(); }, onFailure : function(result, userContext, methodName) { this._onFailure(result, userContext, methodName); GlobalCallQueue.callComplete(); } };QueueCall封装了一个web method调用,它拥有真实web服务调用的所有参数,并且重写了onSuccess和onFailure回调函数。我们想知道当一个调用完成或者失败了的时候,如何从我们的队列里调出另一个调用。GlobalCallQueue保存了web服务调用的列表。无论何时,当一个web method被调用时,我们先要对GlobalCallQueue中的调用进行排队,并从我们自己的队列里一个一个的执行调用。这样就可以保证浏览器在相同的时间里不会有多于两个的调用,所以浏览器就不会停止响应。
为了确保队列是基于调用的,我们需要像之前那样再次重写ASP.NET AJAX的web method
Sys.Net.WebServiceProxy.original_invoke = Sys.Net.WebServiceProxy.invoke;Sys.Net.WebServiceProxy.invoke = function Sys$Net$WebServiceProxy$invoke(servicePath, methodName, useGet, params, onSuccess, onFailure, userContext, timeout){ GlobalCallQueue.call(servicePath, methodName, useGet, params, onSuccess, onFailure, userContext, timeout);}在浏览器中缓存web服务响应可以显著节省带宽
浏览器可以在用户的硬盘里缓存图片、JavaScript、CSS文件,如果XML HTTP调用是一个HTTP GET的话也是可以缓存的。这个缓存是基于URL的。如果是相同URL,且保存在同一个电脑里,那么数据将从缓存里加载,而不会向服务器再次请求。基本上,浏览器可以缓存任何HTTP GET请求并且返回基于URL的被缓存数据。如果你把一个XML HTTP调用作为HTTP Get方式的话,那么服务端将返回一些特殊的头信息,用于通知浏览器对相应做缓存,之后再次调用相同的内容,结果就会立即从缓存中被返回,从而减少了网络传输延迟和下载时间。
在Pageflakes中,我们对用户的状态做了缓存,所以当用户再次访问的时候会从浏览器的缓存里立即得到缓存数据,而不用通过服务端。因此第二次加载时间会变得非常快。我们也缓存了用户的某些行为所产生的结果。当用户再次做相同行为时,缓存结果就会立即从用户的本地缓存中加载,从而减少了网络传输时间。用户会体验到一个快速加载和高响应的站点,获得速度会有明显增长。
这个方法就是处理Atlas web service调用时要使用HTTP GET方式,并且要返回一些明确的HTTP头信息告知浏览器具体要缓存多长时间。如果在响应期间你返回了一个“Expires”头信息,那么浏览器就会缓存这个XML HTTP结果。这里你需要返回两个头信息去通知浏览器缓存结果。
HTTP/1.1 200 OK Expires: Fri, 1 Jan 2030 Cache-Control: public该信息将通知浏览器要缓存结果直到2030年1月1日。在你处理具有相同参数的同一个XML HTTP调用的时候,就将从电脑的缓存中加载数据,而不会通过服务端。这里还有更多的控制缓存的高级方法。例如,有一个头信息通知浏览器缓存60秒,那么浏览器要在60秒之后才能接触到服务端并获取新的结果。当60秒后浏览器本地缓存过期的时候,它也会防止从代理服务器端获得已缓存的响应。
HTTP/1.1 200 OK Cache-Control: private, must-revalidate, proxy-revalidate, max-age=60让我们来尝试着在一个ASP.NET web service方法中产生这样的头信息:
[WebMethod][ScriptMethod(UseHttpGet=true)]public string CachedGet(){ TimeSpan cacheDuration = TimeSpan.FromMinutes(1); Context.Response.Cache.SetCacheability(HttpCacheability.Public); Context.Response.Cache.SetExpires(DateTime.Now.Add(cacheDuration)); Context.Response.Cache.SetMaxAge(cacheDuration); Context.Response.Cache.AppendCacheExtension( "must-revalidate, proxy-revalidate"); return DateTime.Now.ToString();}结果就是下列头信息:

“Expires”头信息被正确的设置。但是问题发生在“Cache-Control”,它显示了“max-age”的值被设置成零,这将阻止浏览器从任何缓存中读取数据。如果你真的想禁用缓存,当然要发送这样一条Cache-Control头信息。结果像是发生了相反的事情。
输出的结果依然是错的,并没有被缓存
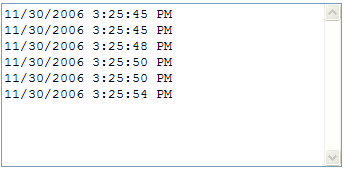
不能改变“max-age”头信息是ASP.NET 2.0中的bug。因为“max-age”被设置成零,而“max-age”的值等于零就意味着不需要缓存,所以ASP.NET 2.0才把“Cache-Control”设置为“private”。所以使ASP.NET 2.0返回正确的缓存响应的头信息是不可行的。
简短节说。反编译HttpCachePolicy类(Context.Response.Cache对象的类)之后,我发现了如下代码:
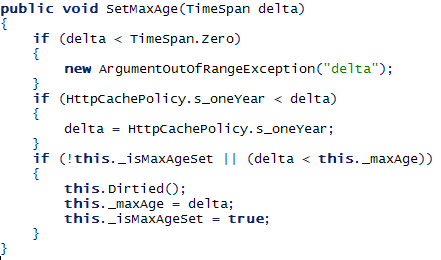
不知何故,this._maxAge的值会被设置成零,看一下这段代码“if (!this._isMaxAgeSet || (delta < this._maxAge))”,它用于防止_maxAge被设置得过大。由于这个问题,我们需绕过SetMaxAge函数,然后使用反射去直接的设置_maxAge的值。
[WebMethod][ScriptMethod(UseHttpGet=true)]public string CachedGet2(){ TimeSpan cacheDuration = TimeSpan.FromMinutes(1); FieldInfo maxAge = Context.Response.Cache.GetType().GetField("_maxAge", BindingFlags.Instance|BindingFlags.NonPublic); maxAge.SetValue(Context.Response.Cache, cacheDuration); Context.Response.Cache.SetCacheability(HttpCacheability.Public); Context.Response.Cache.SetExpires(DateTime.Now.Add(cacheDuration)); Context.Response.Cache.AppendCacheExtension( "must-revalidate, proxy-revalidate"); return DateTime.Now.ToString();}它将返回下列头信息:
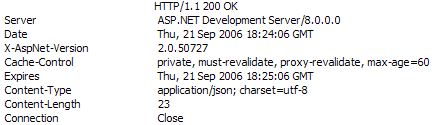
现在“max-age”被设置成了60,所以浏览器将把数据缓存60秒。如果60秒内你使用了相同的调用,那么它将返回相同的结果。下面是一个显示从服务端返回日期的输出结果:

1分钟后,缓存过期并且浏览器再次向服务器发送一个请求。客户端代码如下:
function testCache(){ TestService.CachedGet(function(result) { debug.trace(result); });}这里还有另一个问题需要解决。在web.config文件中,你会看到ASP.NET AJAX增加了下面这个元素:
<system.web> <trust level="Medium"/>它会防止我们设置响应对象的_maxAge,因为它需要反射。所以你必须删除trust元素或者设置它的level属性为Full
<system.web> <trust level="Full"/>当“this”不是你认为的“this”的时候
Atlas回调函数不会在它们被调用的相同上下文中执行 。例如,如果你在一个JavaScript类里像这样使用一个web method
function SampleClass(){ this.id = 1; this.call = function() { TestService.DoSomething( "Hi", function(result) { debug.dump( this.id ); } ); }}当你调用“call”方法的时候会发生什么?你会在debug中得到“1”吗?不会,你将在debug中得到“null”,因为这个“this”不再是类的实例。这是每一个人经常会犯的错误。这在Atlas的文档里仍然没有相关说明,我发现好多开发人员都花费时间去查找这是什么错误。
原因是这样的。我们知道只要JavaScript事件被触发,那么“this”就是指导致事件发生的那个HTML元素,所以如果你像下面这样写的话:
function SampleClass(){ this.id = 1; this.call = function() { TestService.DoSomething( "Hi", function(result) { debug.dump( this.id ); } ); }}<input type="button" id="ButtonID" onclick="o.onclick" />如果你单击了这个按钮,就会发现“ButtonID”代替了“1”。原因就是这个按钮正在调用“call”方法。所以,这个调用在按钮对象的上下文中完成,而“this”就被映射为这个按钮对象。
同样的,当XML HTTP触发了可以捕获和激发回调函数的onreadystatechanged事件的时候,代码执行仍然在XML HTTP的上下文中。它是触发了这个事件的XML HTTP对象。结果,“this”就指向了XML HTTP对象,而不是你自己的在回调函数被声明处的类。
为了使回调函数在类的实例的上下文中激发,所以要让“this”指向类的实例,你需要做如下改变。
function SampleClass(){ this.id = 1; this.call = function() { TestService.DoSomething( "Hi", Function.createDelegate( this, function(result) { debug.dump( this.id ); } ) ); }}这里的Function.createDelegate用来创建一个调用“this”上下文下的特定函数的委托。它可以给函数提供“this”的上下文。Function.createDelegate被定义在Atlas运行时。
Function.createDelegate = function(instance, method) { return function() { return method.apply(instance, arguments); }}HTTP POST要比HTTP GET慢,但是ASP.NET AJAX默认用的是HTTP POST
默认情况下,ASP.NET AJAX的所有web service调用都使用HTTP POST方式。HTTP POST方式要比HTTP GET方式付出更多的代价,它通过网络传输更多的字节,因此就要占用宝贵的网络传输时间,也使得ASP.NET要在服务端做一些额外处理。所以,在可能的情况下你应该使用HTTP GET方式。但是,HTTP GET方式不允许你将对象作为参数传输,你只能传输数字、字符串和日期。当你处理一个HTTP GET调用的时候,Atlas会构造一个被编码的URL并使用它。所以,你不应该传输很多内容而使URL超过2048个字符。据我目前所知,这是任何URL的最大长度。
为了在一个web service方法中使用HTTP GET方式,你需要用[ScriptMethod(UseHttpGet=true)]属性修饰这个方法:
[WebMethod] [ScriptMethod(UseHttpGet=true)] public string HelloWorld(){}POST与GET的另一个问题是,POST需要两次网络传输。当你使用POST的时候,web服务器会先发送一个“HTTP 100 Continue”,这意味着web服务器已经准备好了接收内容。之后,浏览器才会发送实际数据。所以,因为POST请求的初始阶段要比GET方式花费更多的时间,在AJAX程序里网络延迟(你的电脑和服务器之间的数据传输)是要给与足够重视的,因为AJAX适合处理一些小的需要在毫秒级的时间内完成的调用。否则程序会不流畅并且让用户觉得厌烦。
Ethereal是一个很好的工具,它可以侦测到POST和GET的情况下到底发生了什么:

从上面的图中,你可以看到POST方式在准备发送实际数据之前,要从web服务器请求一段“HTTP 100 Continue”的确认信息,这之后才会传输数据。另一方面,GET方式传输数据是不需要任何确认的。
所以,当你要从服务端下载页的某一部分、一个表格或者是一段文本之类的时候就应该使用HTTP GET方式。而如果要像web form那样以提交的方式发送数据到服务端的话就不应该使用HTTP GET方式。
结论
上面所说的这些高级技巧都已经在Pageflakes中实现了,这里我并没有提及它的详细实现方法,但是原理都提到了,所以,你可以放心地使用这些技术。这些技术将节省你解决问题的时间,也许在开发环境中你从来没认识到这些问题,但是当你大规模部署网站之后,来自世界各地的访问者就将面对这些问题。一开始就正确的实现这些技巧将会大大节省你的开发和客户支持的时间。请同时关注我的博客以获得更多的技巧。