python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)
https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm_source=cp-400000000398149&utm_medium=share

决策树优点和缺点
决策树优点
1.简单易懂,很好解读,可视化
2.可以变量筛选

缺点
1.决策树不稳定,容易过渡拟合
2.决策树用的贪婪算法,返回局部最优,而非全局最优,最后得到有偏见的树
(用随机森林改善)

分类树VS回归树
回归树应用场景:变量是连续性的,使用平均数参数
分类树应用场景:变量是分类型的,使用众数参数
树的延伸太多,会造成过渡拟合,返回局部最优,即对测试数据表现良好,但对未知数据表现很差,可以限制树深度和叶子节点来改善准确性

pruning是可以限制树深度和叶子节点来改善准确性

决策树应用
1.信用评分
2.泰坦尼克号生存分析
3.根据身高和体重判断人的性别
................

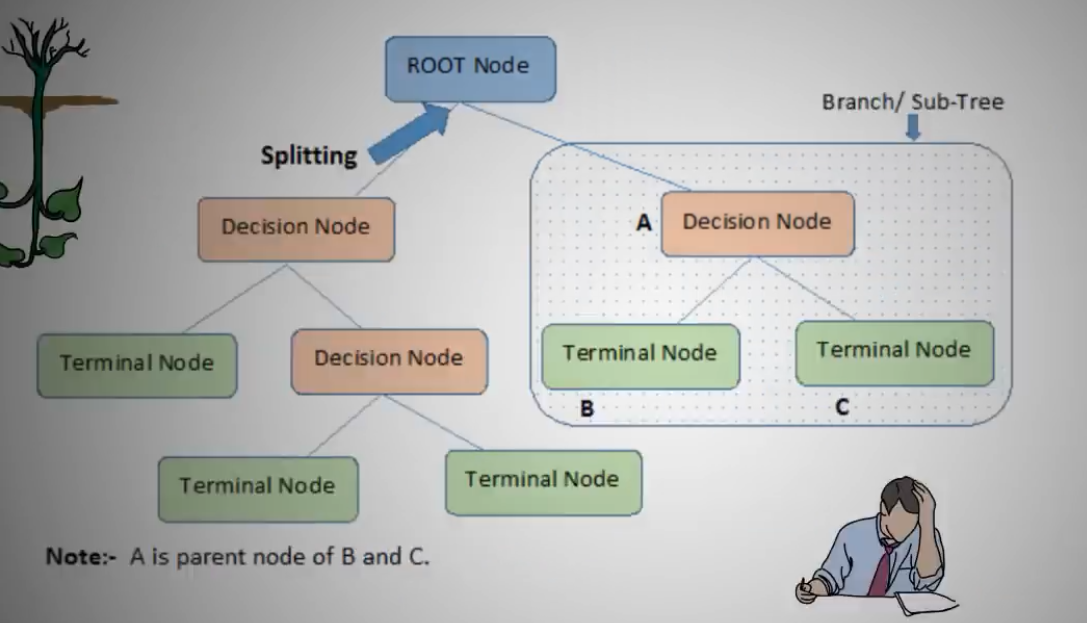
决策树组成
决策树由root node根节点,decision node决策点,terminall node终端点组成


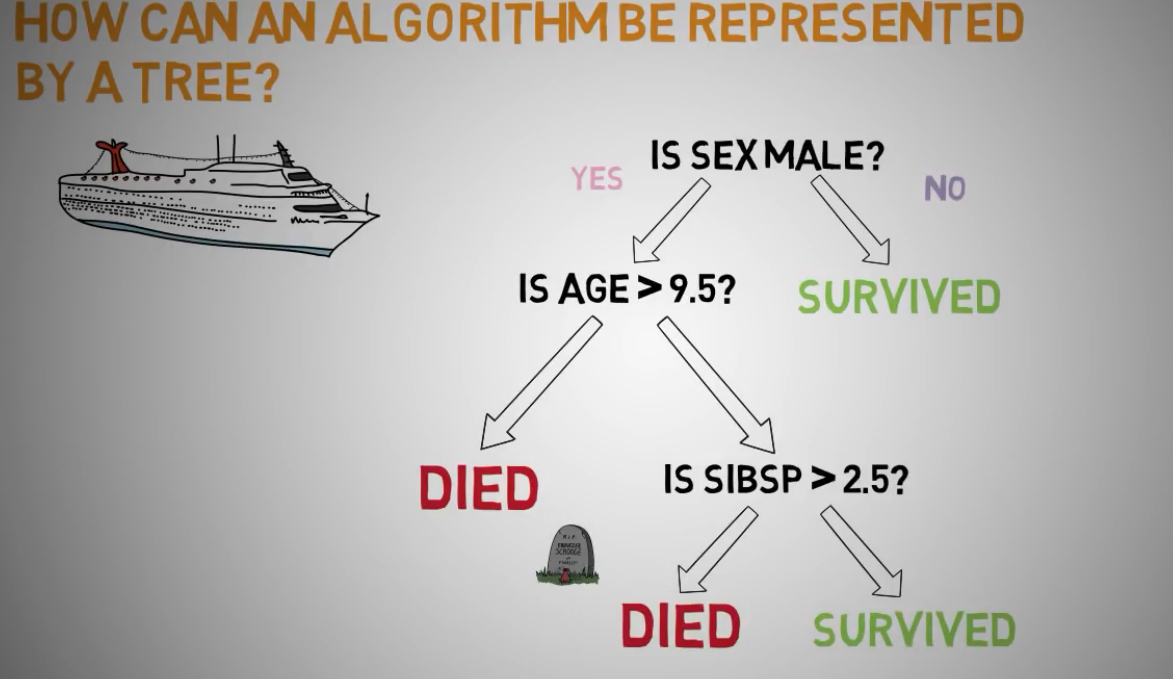
泰坦尼克号决策树的应用分析
第一个最显著因子是性别,如果是女性存活
如果是男性,有的死了,有的活了
如果是年龄大于9.5岁男性,死了
如果年龄小于9.5岁男性,且有兄弟姐妹年龄大于2.5岁的,死了
如果年龄小于9.5岁男性,且有兄弟姐妹年龄小于2.5岁的,存活
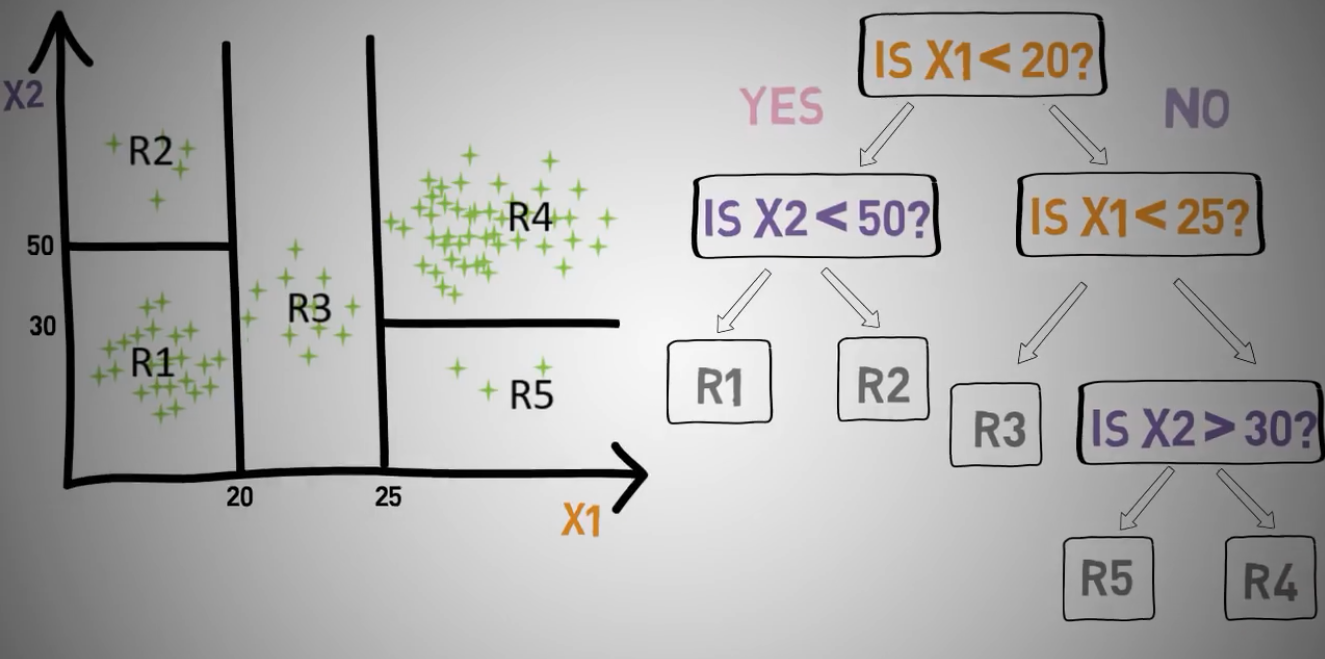
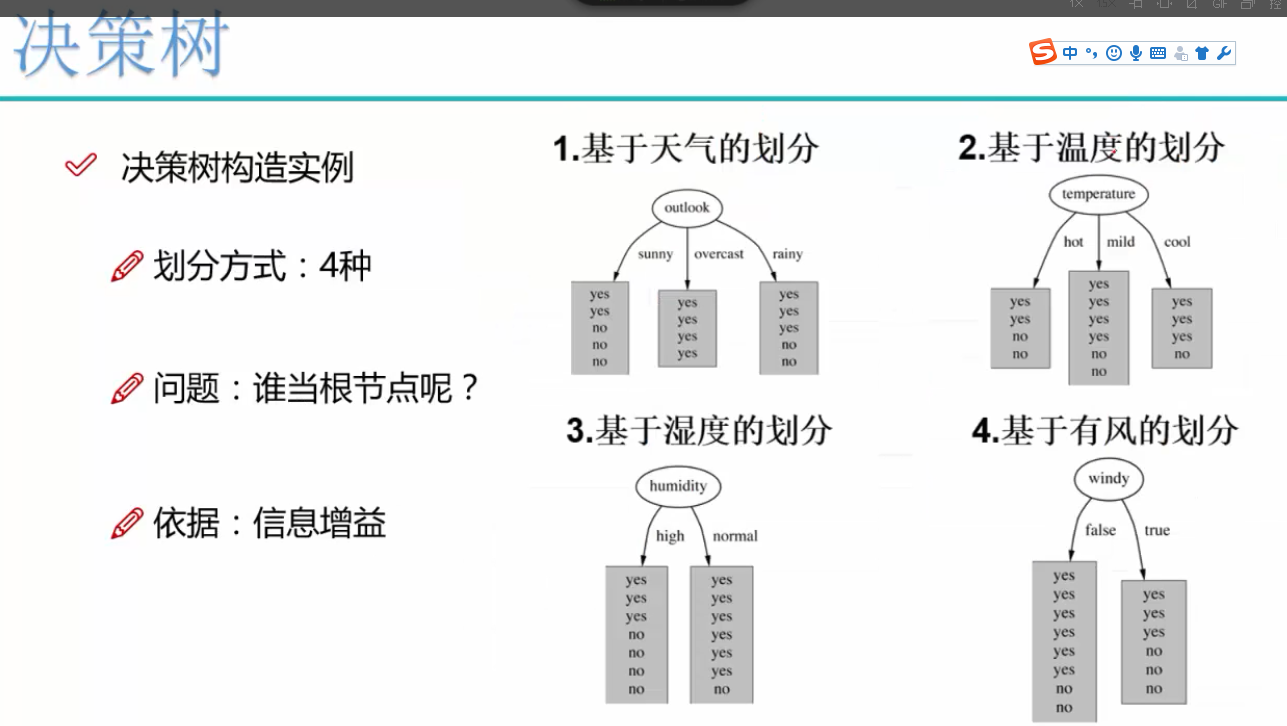
决策树举例
把一组数据划分为五个对象,通过x1的两个节点20和25
x2的两个节点30和50,来划分这五个对象
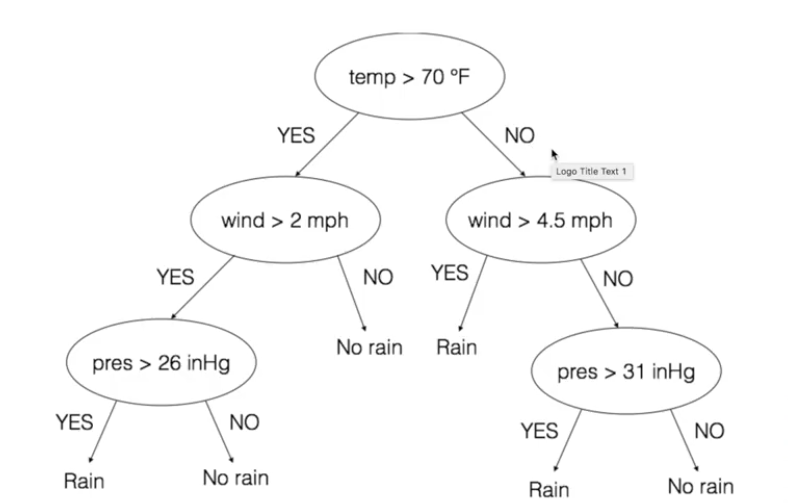
决策树举例:降雨是由气温,风速,气压共同决定
决策树对水果分类应用



先选大当家,再选二当家,根据熵值

熵值越大,混乱程度和不确定性越大

x概率越大,熵值y越小
x概率越小,熵值y越大
因为x取值范围是从0-1,得到log值是负数,所以公式前面有个负号,让值最终为正数
求和符号是对一个数据集的每个数字求熵值,然后累加
log底数是2

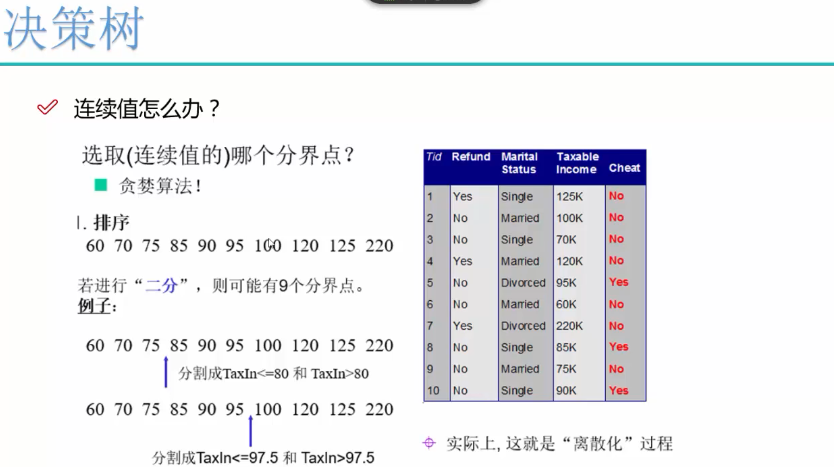
信息增益

举例



ID3算法对于小样本数据效果差,算出来信息增益很大
C4.5算法考虑自身熵,做了改进
cart和Gini系数算法现在用的多
另外还有卡方算法和减少方差算法


基尼系数GINI index
用于区分两个类别的分离程度如何,基尼系数=0.5,说明两个类别数量一致,无区分程度,如果基尼系数=0,说明两个类别区分度最明显



预剪枝用的比较多,避免过渡拟合

sklearn有很好可视化效果
信息增益小于某个值时,也可以限制

限制叶子节点个数
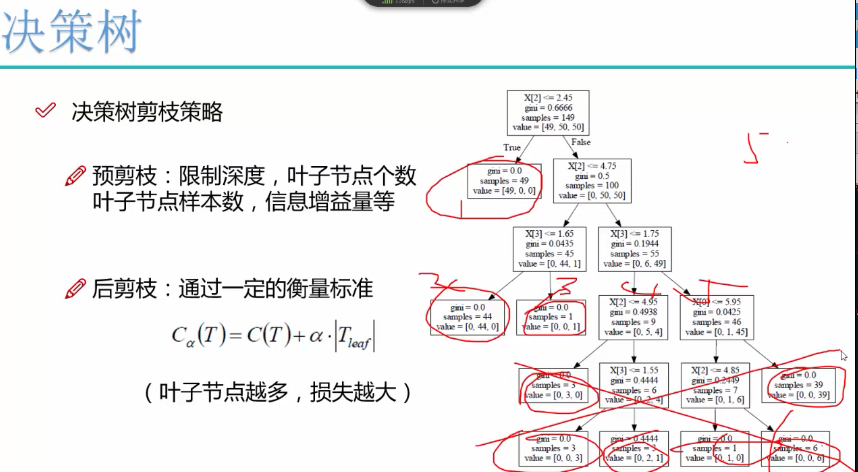
限制叶子节点深度

python代码构建乳腺癌细胞分类器
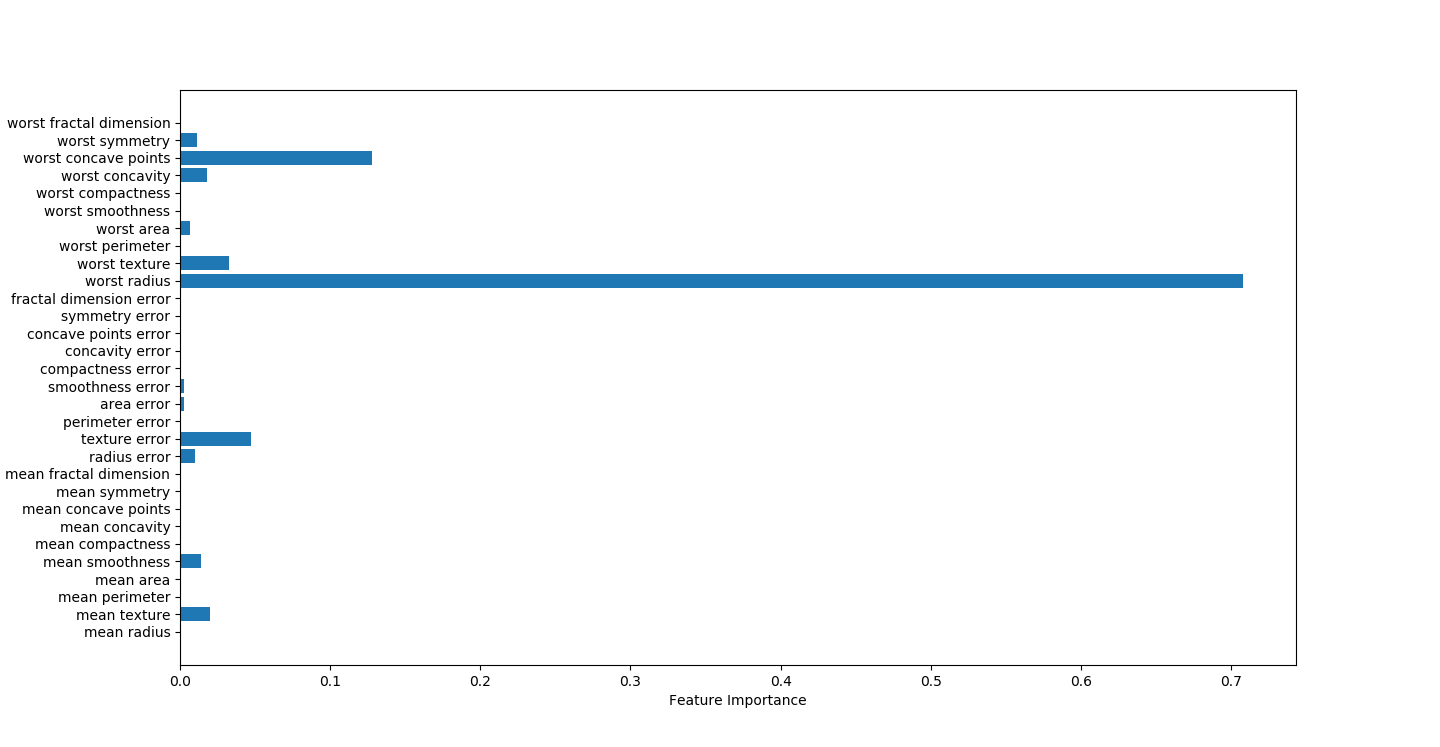
决策树可视化因子结果,worst radius影响因素最大
# -*- coding: utf-8 -*-
"""
Created on Tue Mar 27 22:59:44 2018
@author: Toby,项目合作QQ:231469242
radius半径
texture结构,灰度值标准差
symmetry对称
决策树找出强因子
worst radius
worst symmetry
worst texture
texture error
"""
import csv,pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import pydotplus
from IPython.display import Image
import graphviz
from sklearn.tree import export_graphviz
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
cancer=load_breast_cancer()
featureNames=cancer.feature_names
#random_state 相当于随机数种子
X_train,x_test,y_train,y_test=train_test_split(cancer.data,cancer.target,stratify=cancer.target,random_state=42)
list_average_accuracy=[]
depth=range(1,30)
for i in depth:
#max_depth=4限制决策树深度可以降低算法复杂度,获取更精确值
tree= DecisionTreeClassifier(max_depth=i,random_state=0)
tree.fit(X_train,y_train)
accuracy_training=tree.score(X_train,y_train)
accuracy_test=tree.score(x_test,y_test)
average_accuracy=(accuracy_training+accuracy_test)/2.0
#print("average_accuracy:",average_accuracy)
list_average_accuracy.append(average_accuracy)
max_value=max(list_average_accuracy)
#索引是0开头,结果要加1
best_depth=list_average_accuracy.index(max_value)+1
print("best_depth:",best_depth)
best_tree= DecisionTreeClassifier(max_depth=best_depth,random_state=0)
best_tree.fit(X_train,y_train)
accuracy_training=best_tree.score(X_train,y_train)
accuracy_test=best_tree.score(x_test,y_test)
print("decision tree:")
print("accuracy on the training subset:{:.3f}".format(best_tree.score(X_train,y_train)))
print("accuracy on the test subset:{:.3f}".format(best_tree.score(x_test,y_test)))
#print('Feature importances:{}'.format(best_tree.feature_importances_))
#绘图,显示因子重要性
n_features=cancer.data.shape[1]
plt.barh(range(n_features),best_tree.feature_importances_,align='center')
plt.yticks(np.arange(n_features),cancer.feature_names)
plt.title("Decision Tree:")
plt.xlabel('Feature Importance')
plt.ylabel('Feature')
plt.show()
#生成一个dot文件,以后用cmd形式生成图片
export_graphviz(tree,out_file="cancertree.dot",class_names=['malignant','benign'],feature_names=cancer.feature_names,impurity=False,filled=True)
决策树可视化
安装graphviz官网介绍
https://blog.csdn.net/lanchunhui/article/details/49472949
安装包graphviz
pip install graphviz
#生成一个dot文件,文件存放于脚本所在位置
以后用cmd形式生成图片,
export_graphviz(tree,out_file="cancertree.dot",class_names=['malignant','benign'],feature_names=cancer.feature_names,impurity=False,filled=True)
cmd切换路径到脚本所在位置,然后输入dot -Tpng cancertree.dot -o cancertree.png
生成一个决策树的图片
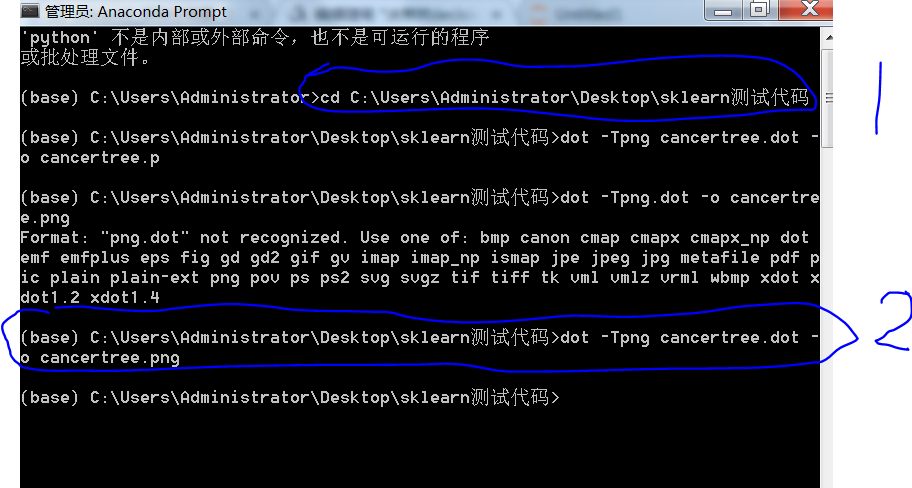
生成图片打开预览

决策树交叉验证代码
交叉验证结果0.92左右

import csv,pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import pydotplus
from IPython.display import Image
import graphviz
from sklearn.tree import export_graphviz
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
from sklearn.model_selection import train_test_split
#交叉验证样本平均测试,评分更加
from sklearn.cross_validation import cross_val_score
#交叉验证得分,返回数组
#score_decisionTree=cross_val_score(decisionTree,x,y,cv=5,scoring='accuracy')
#print("cross value decisionTree= score:",score_decisionTree.mean())
cancer=load_breast_cancer()
#数据
data=cancer.data
#分类
target=cancer.target
x=data
y=target
featureNames=cancer.feature_names
#5.决策树
#建立决策树分类器
decisionTree= tree.DecisionTreeClassifier(max_depth=5)
#交叉验证得分,返回数组
score_decisionTree=cross_val_score(decisionTree,x,y,cv=10,scoring='accuracy')
print("cross value decisionTree= score:",score_decisionTree.mean())

微信扫二维码,免费学习更多python资源
