python信用评分卡建模(附代码,博主录制)

测试数据结果:用非B4数据
肉毒素-横力 申请金额 是市场价格 平均倍数 4.4 最高16.666 最低0.433
B4状态5.14倍 最高16.666 最低0.433
D1 平均4.14倍 最高 最低
眼部_双眼皮_切开
B4平均价: 16314
非B4平均价:12697
注射类_玻尿酸_进口
平均价19560
B4平均价 21374
非B4平均价18497
鼻部_鼻综合_鼻综合
以前价格:63000
平均价:31497
B4平均价 :32926
非B4平均价:29637
据了解京东医美汇实际是成都市悦好医疗美容与京东合作的一个项目,相当于你的公司在京东开一个整形专营店,在打着京东的旗号起全国各地招募整形机构,整形机构看好的是京东的巨大流量,实际京东商城并不给流量的入口,京东医美汇也没有新颖的商业模式
像京东这种大平台,能够让医疗美容入驻平台,也是因为新氧,更美,悦美等医疗美容互联网平台这2年受风投追捧有关,京东也想作为一个尝试,看看医美的数据到底怎么样,如果数据乐观,按医美线下市场千亿级规模来看,一定是快大蛋糕,自上线一年多的观察来看,京东医美汇并没有在互联网医疗美容行业,掀起什么波浪,在看这二年新氧更美等主流平台的业绩发展,医疗美容行业还处于初级发展阶段,社会对医美的认识和熟悉程度还不够,对医美用户的唤醒和教育工作仍是未来几年的重任,待机会成熟BAT等企业一定会进入,不再会静观其变。
像京东这种大平台,能够让医疗美容入驻平台,也是因为新氧,更美,悦美等医疗美容互联网平台这2年受风投追捧有关,京东也想作为一个尝试,看看医美的数据到底怎么样,如果数据乐观,按医美线下市场千亿级规模来看,一定是快大蛋糕,自上线一年多的观察来看,京东医美汇并没有在互联网医疗美容行业,掀起什么波浪,在看这二年新氧更美等主流平台的业绩发展,医疗美容行业还处于初级发展阶段,社会对医美的认识和熟悉程度还不够,对医美用户的唤醒和教育工作仍是未来几年的重任,待机会成熟BAT等企业一定会进入,不再会静观其变。
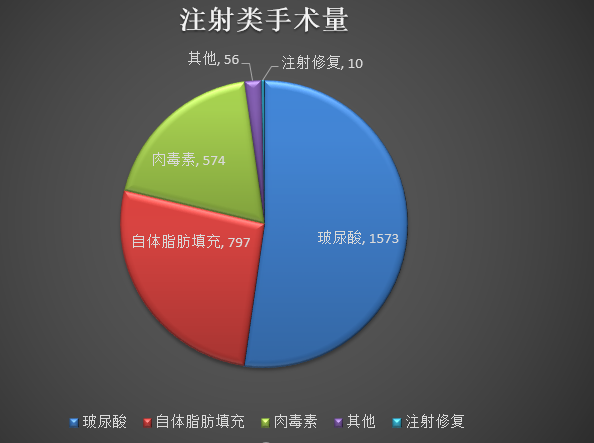
医美手术市场价格(旧)


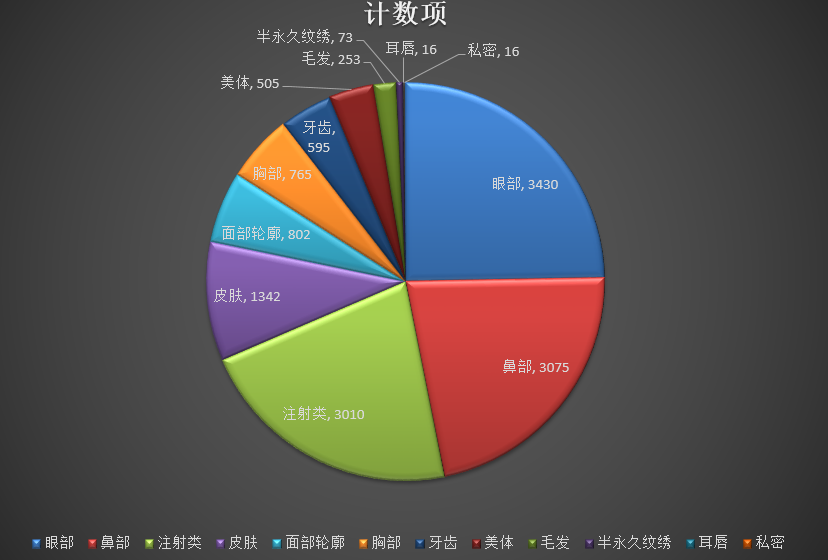
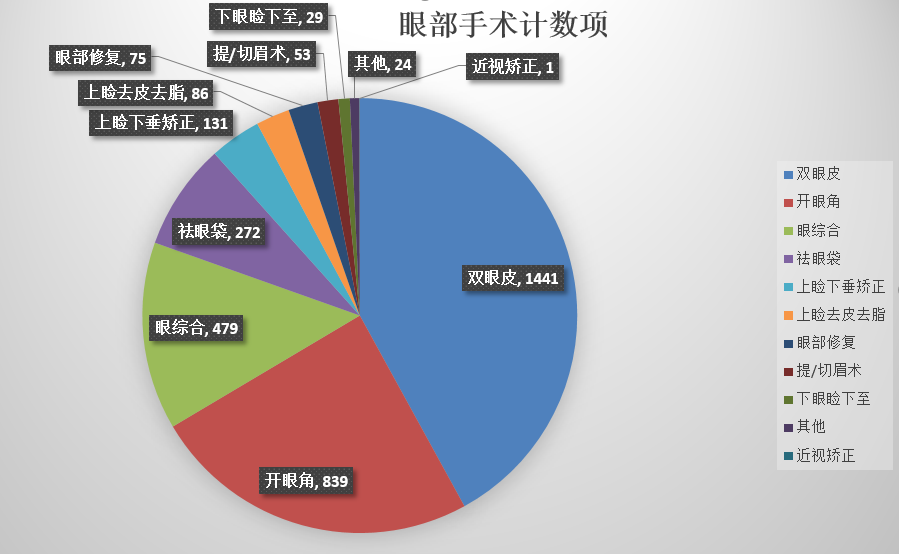
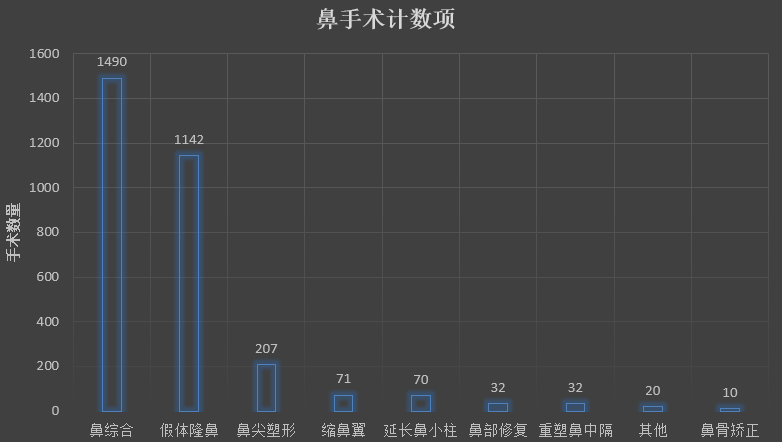
玻尿酸 2000,5000 价位
肉毒素3000,6000价位
手术名——市场价格

https://jingyan.baidu.com/article/a948d65109e4f90a2dcd2ea0.html
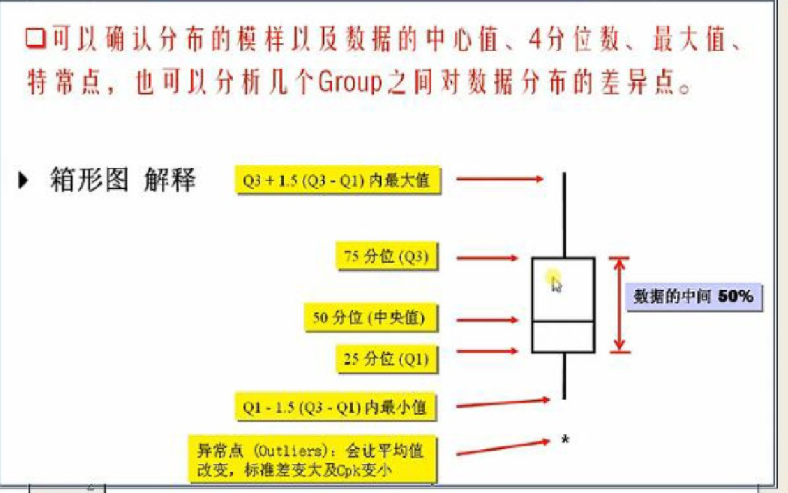
分位数是将总体的全部数据按大小顺序排列后,处于各等分位置的变量值。如果将全部数据分成相等的两部分,它就是中位数;如果分成四等分,就是四分位数;八等分就是八分位数等。四分位数也称为四分位点,它是将全部数据分成相等的四部分,其中每部分包括25%的数据,处在各分位点的数值就是四分位数。四分位数有三个,第一个四分位数就是通常所说的四分位数,称为下四分位数,第二个四分位数就是中位数,第三个四分位数称为上四分位数,分别用Q1、Q2、Q3表示[1] 。
第一四分位数 (Q1),又称“较小四分位数”,等于该样本中所有数值由小到大排列后第25%的数字。
第二四分位数 (Q2),又称“中位数”,等于该样本中所有数值由小到大排列后第50%的数字。
第三四分位数 (Q3),又称“较大四分位数”,等于该样本中所有数值由小到大排列后第75%的数字。
第三四分位数与第一四分位数的差距又称四分位距(InterQuartile Range,IQR)。

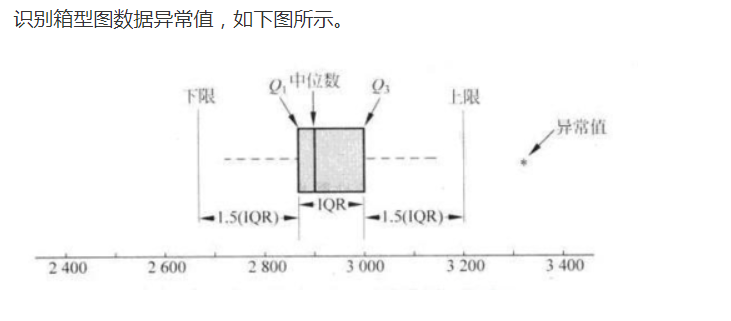

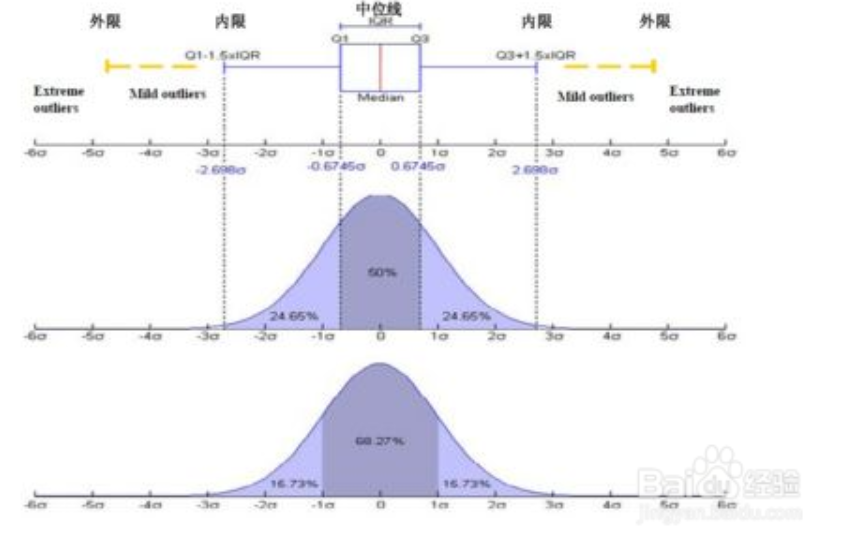
箱形图算法修正,如果
异常值上线=四分之三位数+1.5*IQR 如果异常值上线大于数组最大值,就取数组最大值
异常值下线=四分之一位数-1.5*IQR,如果异常值下线小于数组最小值,就取数组最小值
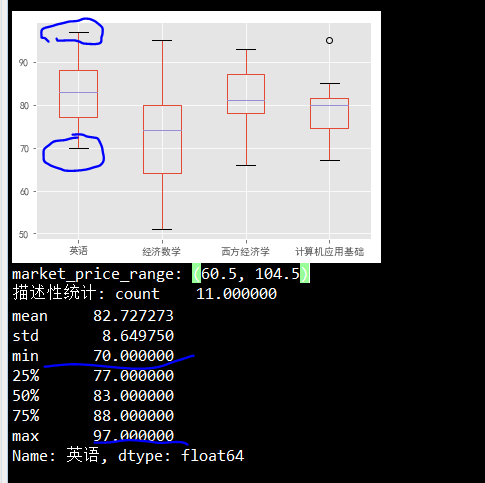
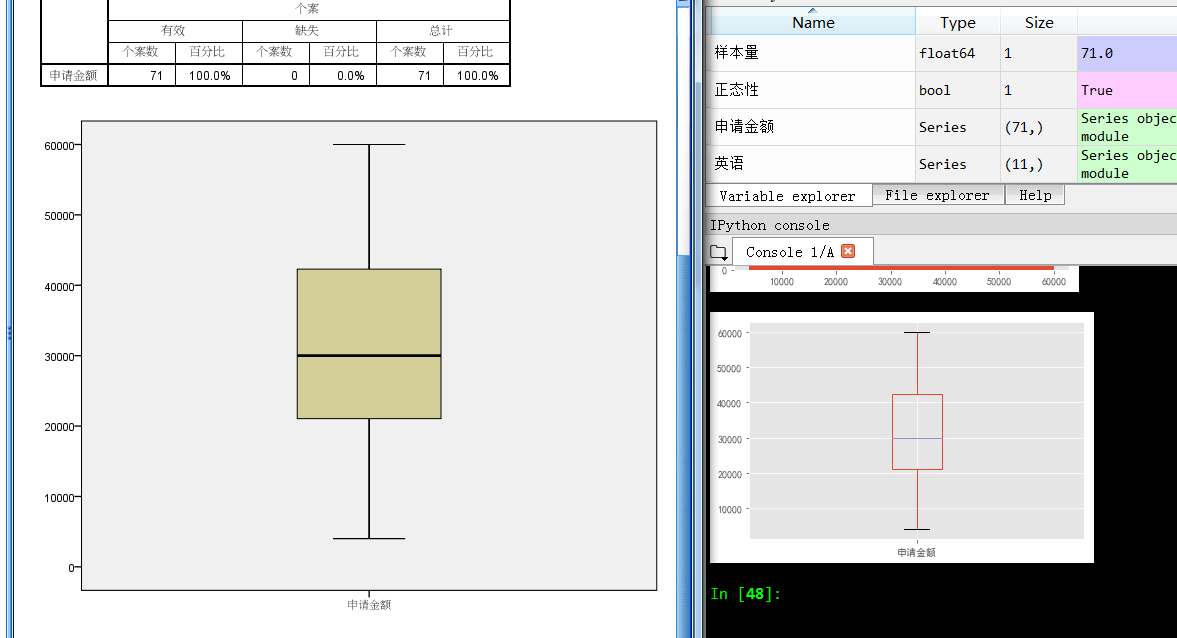
箱型图异常值判断脚本
# -*- coding: utf-8 -*-
"""
Created on Fri Mar 9 10:18:04 2018
@author: Administrator
"""
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
#读取文件
FileName="眼部_双眼皮_切开.xlsx"
#读取excel
df=pd.read_excel("save/"+FileName)
申请金额=df['申请金额']
series_子类标准价格=df['子类标准价格']
#手术名
名字=df['手术名'].values[0]
dict_申请金额_描述统计={}
样本量=描述性统计[0]
子类标准价格=series_子类标准价格.values[0]
描述性统计=申请金额.describe()
最小值=申请金额.min()
最大值=申请金额.max()
平均数=申请金额.mean()
中位数=申请金额.median()
众数=float(申请金额.mode())
四分之一位数=描述性统计[4]
四分之三位数=描述性统计[6]
标准差=描述性统计[2]
dict_申请金额_描述统计["子类手术名"]=名字
dict_申请金额_描述统计["样本量"]=样本量
dict_申请金额_描述统计["子类标准价格"]=子类标准价格
dict_申请金额_描述统计["最小值"]=最小值
dict_申请金额_描述统计["最大值"]=最大值
dict_申请金额_描述统计["平均数"]=平均数
dict_申请金额_描述统计["中位数"]=中位数
dict_申请金额_描述统计["众数"]=众数
dict_申请金额_描述统计["四分之一位数"]=四分之一位数
dict_申请金额_描述统计["四分之三位数"]=四分之三位数
dict_申请金额_描述统计["标准差"]=标准差
'''
a=list(dict_申请金额_描述统计)
b=list(dict_申请金额_描述统计.values())
c=[(a[i],b[i]) for i in range(len(a))]
'''
print (dict_申请金额_描述统计)
#绘制正太分布图
申请金额.hist()
df1=pd.DataFrame(申请金额)
a=df1.boxplot()
IQR=四分之三位数-四分之一位数
异常值上线=四分之三位数+1.5*IQR
异常值下线=四分之一位数-1.5*IQR
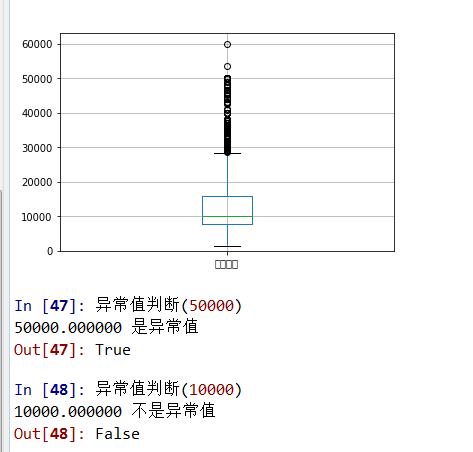
def 异常值判断(数字):
if 数字>异常值上线 or 数字<异常值下线:
print("%f 是异常值"%数字)
return True
else:
print("%f 不是异常值"%数字)
return False
python风控建模实战lendingClub(博主录制,catboost,lightgbm建模,2K超清分辨率)
https://study.163.com/course/courseMain.htm?courseId=1005988013&share=2&shareId=400000000398149

微信扫二维码,免费学习更多python资源
