Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门
https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6EmUbbW&id=564564604865
数据源
http://118.114.237.85:8081/searchbio.aspx
采集内容字段有的对不整齐,
def Get_one_table()函数需要修改

# -*- coding: utf-8 -*-
"""
Spyder Editor
采集思路:采一页,保存一页
This is a temporary script file.
"""
import requests,bs4,csv,time,selenium
from selenium import webdriver
list_allContent=[]
site="http://piqianfa.scsyjs.org/"
site1="http://118.114.237.85:8081/searchbio.aspx"
charset="gb2312"
browser=webdriver.Firefox()
browser.get(site1)
pages=196
#这种方式采集下来很粗糙,容易错位
def Get_one_table():
elems=browser.find_elements_by_tag_name("tr")
content=elems[0].text
list_content=content.split("
")
#列表内个数
num=len(list_content)
list_content2=list_content[3:num]
list_allContent.append(list_content2)
return list_content2
'''
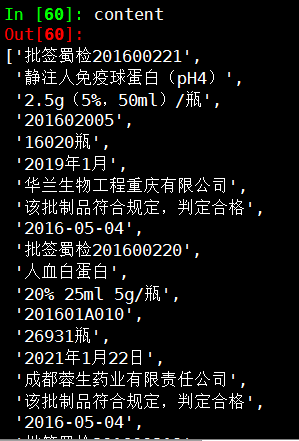
list_content2[2]
Out[13]: '批签蜀检201600220 人血白蛋白 20% 25ml 5g/瓶 201601A010 26931瓶 2021年1月22日
成都蓉生药业有限责任公司 该批制品符合规定,判定合格 2016-05-04'
'''
def Write_table_to_csv(fileName,list_tableContent):
#对列表格式修改,字符串写入的格式不对
list_tableContent1=[i.split(" ") for i in list_tableContent]
file=open(fileName,'w',newline='')
writer1=csv.writer(file)
writer1.writerows(list_tableContent1)
file.close()
def Click_next_page():
linkElem=browser.find_element_by_link_text("下一页")
linkElem.click()
def Get_fileName():
pass
for i in range(1,pages+1):
list_tableContent=Get_one_table()
Click_next_page()
fileName=str(i)+".csv"
Write_table_to_csv(fileName,list_tableContent)
def Get_one_table()函数需要修改
# -*- coding: utf-8 -*-
"""
Created on Fri May 6 10:24:18 2016
@author: Administrator
"""
import requests,bs4,csv,time,selenium
from selenium import webdriver
site1="http://118.114.237.85:8081/searchbio.aspx"
charset="gb2312"
browser=webdriver.Firefox()
browser.get(site1)
elems=browser.find_elements_by_class_name("tb")
elems1= elems[1:]
content=[i.text for i in elems1]
'''
elems=browser.find_elements_by_class_name("tr")
elems
Out[33]: []
elems=browser.find_elements_by_class_name("tb")
elems[1].text
Out[25]: '批签蜀检201600221'
elems[2].text
Out[26]: '静注人免疫球蛋白(pH4)'
elems[3].text
Out[27]: '2.5g(5%,50ml)/瓶'
elems[4].text
Out[28]: '201602005'
content
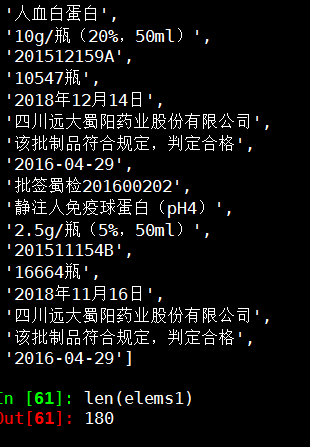
Out[60]:
['批签蜀检201600221',
'静注人免疫球蛋白(pH4)',
'2.5g(5%,50ml)/瓶',
'201602005',
'16020瓶',
'2019年1月',
'华兰生物工程重庆有限公司',
'该批制品符合规定,判定合格',
'2016-05-04',
'批签蜀检201600220',
'人血白蛋白',
'20% 25ml 5g/瓶',
'批签蜀检201600202',
'静注人免疫球蛋白(pH4)',
'2.5g/瓶(5%,50ml)',
'201511154B',
'16664瓶',
'2018年11月16日',
'四川远大蜀阳药业股份有限公司',
'该批制品符合规定,判定合格',
'2016-04-29']
len(elems1)
Out[61]: 180
'''
'''
content=elems[0].text
list_content=content.split("
")
#列表内个数
num=len(list_content)
list_content2=list_content[3:num]
'''