python金融风控评分卡模型和数据分析微专业课(博主亲自录制视频):http://dwz.date/b9vv

在我们开发完信用分模型后,经常需要计算如下的一些指标:
● 区分度的指标: ○ AUC ○ KS ○ GINI
● 稳定性的指标: ○ PSI
● 分数分布: ○ 总人数比例 ○ 坏用户比例 接下来,本文从如下5个模块为读者朋友们介绍如何利用Python实现这些指标数据。
目录
Part 1. 生成样本
Part 2. 计算AUC、KS、GINI
Part 3. PSI
Part 4. 分数分布
Part 5. 完整工程代码
致谢
01
生成样本
首先,本文用以示例,故使用代码创造的一些假样本。
import numpy as np
import pandas as pd
n_sample = 1000
df_score = pd.DataFrame({
'user_id': [u for u in range(n_sample)],
'label':np.random.randint(2, size=n_sample),
'score': 900*np.random.random(size=n_sample),
'term': 20201+np.random.randint(5, size=n_sample)
})
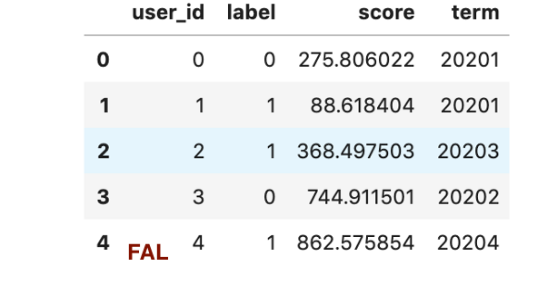
然后我们统计下分term的总人数,坏人数和坏人比例:
df_score.groupby('term').agg(total=('label', 'count'),
bad=('label', 'sum'),
bad_rate=('label', 'mean'))

02
区分度指标
计算区分度指标KS、AUC、GINI的helper function如下:
from sklearn.metrics import roc_auc_score, roc_curve
def get_auc(ytrue, yprob):
auc = roc_auc_score(ytrue, yprob)
if auc < 0.5:
auc = 1 - auc
return auc
def get_ks(ytrue, yprob):
fpr, tpr, thr = roc_curve(ytrue, yprob)
ks = max(abs(tpr - fpr))
return ks
def get_gini(ytrue, yprob):
auc = get_auc(ytrue, yprob)
gini = 2 * auc - 1
return gini
这里对原有sklearn的auc计算做了一点修改,如果AUC<0.5的话会返回1-AUC, 这样能忽略区分度的方向性。
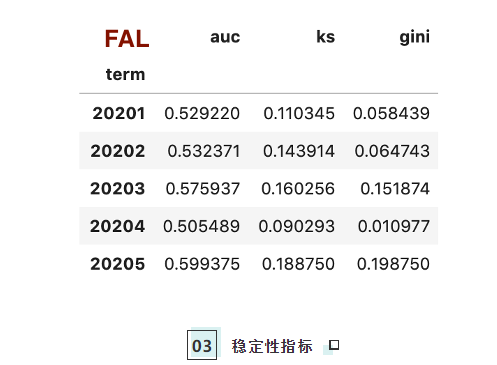
然后对每个term做区分度的计算:
df_metrics = pd.DataFrame({
'auc': df_score.groupby('term').apply(lambda x: get_auc(x['label'], x['score'])),
'ks': df_score.groupby('term').apply(lambda x: get_ks(x['label'], x['score'])),
'gini': df_score.groupby('term').apply(lambda x: get_gini(x['label'], x['score']))
})
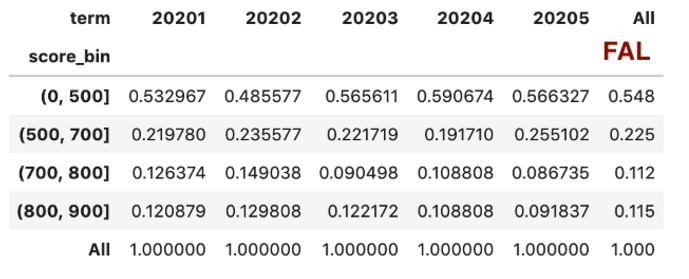
这里先分成2步:
-
简单对随机生成的信用分按固定分数区间分段;
-
按照分段计算PSI:使用pivot_table把数据按照term进行排列计算每个term上的人数比例。
df_score['score_bin'] = pd.cut(df_score['score'], [0, 500, 700, 800, 900])
df_total = pd.pivot_table(df_score,
values='user_id',
index='score_bin',
columns=['term'],
aggfunc="count",
margins=True)
df_ratio = df_total.div(df_total.iloc[-1, :], axis=1)
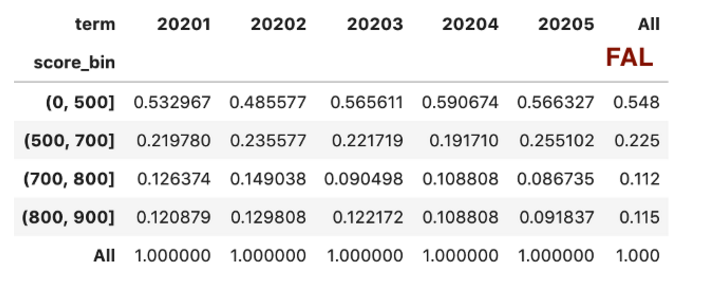
根据人数比例计算PSI再放回表格内
eps = np.finfo(np.float32).eps
lst_psi = list()
for idx in range(1, len(df_ratio.columns)-1):
last, cur = df_ratio.iloc[0, -1: idx-1]+eps, df_ratio.iloc[0, -1: idx]+eps
psi = sum((cur-last) * np.log(cur / last))
lst_psi.append(psi)
df_ratio.append(pd.Series([np.nan]+lst_psi+[np.nan],
index=df_ratio.columns,
name='psi'))

统计总人数分布和坏用户比例的分布,其实在上面计算PSI的时候已经计算出人数分布,就是上面的df_ratio:
df_total = pd.pivot_table(df_score,
values='user_id',
index='score_bin',
columns=['term'],
aggfunc="count",
margins=True)
df_ratio = df_total.div(df_total.iloc[-1, :], axis=1)
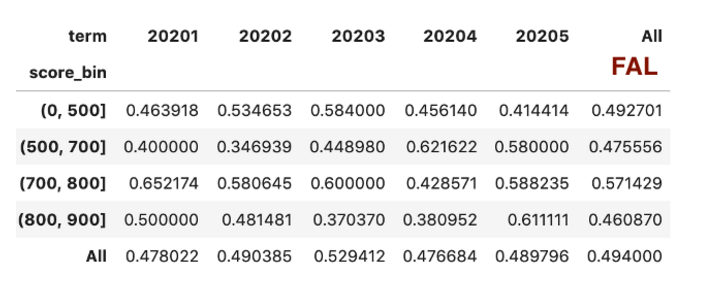
所以,这里照葫芦画瓢把坏用户抽取出来再重复一遍,就可以把坏用户比例计算出来。
df_bad = pd.pivot_table(df_score[df_score['label']==1],
values='user_id',
index='score_bin',
columns=['term'],
aggfunc="count",
margins=True)
df_bad_rate = df_bad/df_total
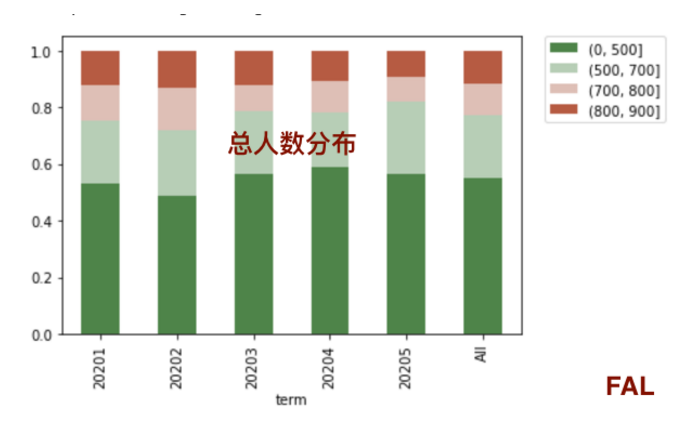
可以使用seaborn的stacked line和stacked bar来做出总用户的分布和坏用户的比列分布。
4.1.总人数分布:
import seaborn as sns
colormap = sns.diverging_palette(130, 20, as_cmap=True)
df_ratio.drop('All').T.plot(kind='bar', stacked=True, colormap=colormap)
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
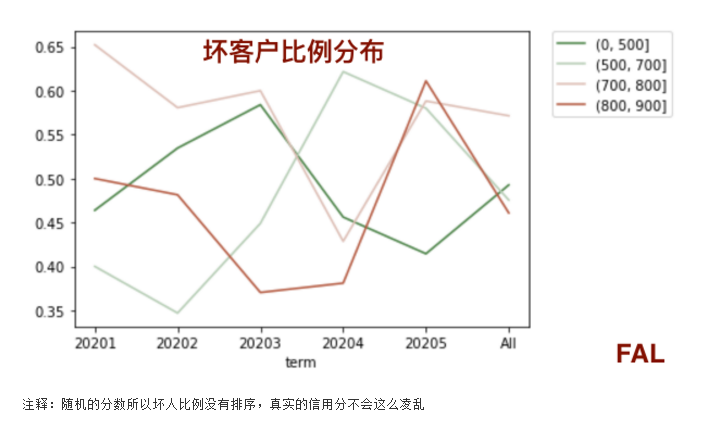
4.2.坏人比例分布:
colormap = sns.diverging_palette(130, 20, as_cmap=True)
df_bad_rate.drop('All').T.plot(kind='line', colormap=colormap)
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
05
完整Python代码
至此,本文已经把信用风控模型6大核心指标的计算过程都展示出来了。最后附上完整工程Python代码,供FALers学习使用。
import numpy as np
import pandas as pd
n_sample = 1000
df_score = pd.DataFrame({
'user_id': [u for u in range(n_sample)],
'label':np.random.randint(2, size=n_sample),
'score': 900*np.random.random(size=n_sample),
'term': 20201+np.random.randint(5, size=n_sample)
})
df_score.groupby('term').agg(total=('label', 'count'),
bad=('label', 'sum'),
bad_rate=('label', 'mean'))
#KS,GINI,AUC
from sklearn.metrics import roc_auc_score, roc_curve
def get_auc(ytrue, yprob):
auc = roc_auc_score(ytrue, yprob)
if auc < 0.5:
auc = 1 - auc
return auc
def get_ks(ytrue, yprob):
fpr, tpr, thr = roc_curve(ytrue, yprob)
ks = max(abs(tpr - fpr))
return ks
def get_gini(ytrue, yprob):
auc = get_auc(ytrue, yprob)
gini = 2 * auc - 1
return gini
df_metrics = pd.DataFrame({
'auc': df_score.groupby('term').apply(lambda x: get_auc(x['label'], x['score'])),
'ks': df_score.groupby('term').apply(lambda x: get_ks(x['label'], x['score'])),
'gini': df_score.groupby('term').apply(lambda x: get_gini(x['label'], x['score']))
})
#PSI
df_score['score_bin'] = pd.cut(df_score['score'], [0, 500, 700, 800, 900])
df_total = pd.pivot_table(df_score,
values='user_id',
index='score_bin',
columns=['term'],
aggfunc="count",
margins=True)
df_ratio = df_total.div(df_total.iloc[-1, :], axis=1)
eps = np.finfo(np.float32).eps
lst_psi = list()
for idx in range(1, len(df_ratio.columns)-1):
last, cur = df_ratio.iloc[0, -1: idx-1]+eps, df_ratio.iloc[0, -1: idx]+eps
psi = sum((cur-last) * np.log(cur / last))
lst_psi.append(psi)
df_ratio.append(pd.Series([np.nan]+lst_psi+[np.nan],
index=df_ratio.columns,
name='psi'))
#总人数比例和坏客户比例
df_total = pd.pivot_table(df_score,
values='user_id',
index='score_bin',
columns=['term'],
aggfunc="count",
margins=True)
df_ratio = df_total.div(df_total.iloc[-1, :], axis=1)
df_bad = pd.pivot_table(df_score[df_score['label']==1],
values='user_id',
index='score_bin',
columns=['term'],
aggfunc="count",
margins=True)
df_bad_rate = df_bad/df_total
#做图
import seaborn as sns
colormap = sns.diverging_palette(130, 20, as_cmap=True)
df_ratio.drop('All').T.plot(kind='bar', stacked=True, colormap=colormap)
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
colormap = sns.diverging_palette(130, 20, as_cmap=True)
df_bad_rate.drop('All').T.plot(kind='line', colormap=colormap)
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
转载:https://mp.weixin.qq.com/s/9o-u7zRM0mv-3wXPTv8oAQ
python信用评分卡建模(附代码,博主录制)
