
这是简易数据分析系列的第 13 篇文章。
在前面的课程里,我们抓取的数据都是在同一个层级下的内容,探讨的问题主要是如何应对市面上的各种分页类型,但对于详情页内容数据如何抓取,却一直没有介绍。
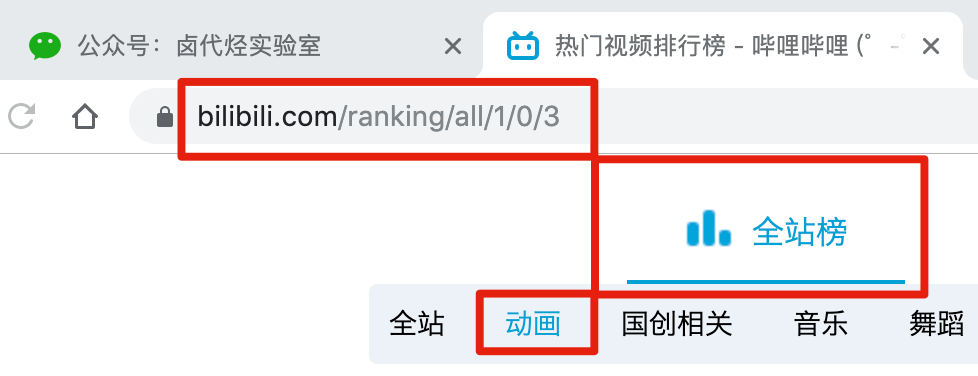
比如说我们想抓取 b 站的动画区 TOP 排行榜的数据:
https://www.bilibili.com/ranking/all/1/0/3
按之前的抓取逻辑,我们是把这个榜单上和作品有关的数据抓取一遍,比如说下图里的排名、作品名字、播放量、弹幕数和作者名。

经常逛 B 站的小伙伴也知道,UP 主经常暗示观看视频小伙伴三连操作(点赞+投币+收藏),由此可见,这 3 个数据对视频的排名有一定的影响力,所以这些数据对我们来说也有一定的参考价值。

但遗憾的是,在这个排名列表里,并没有相关数据。这几个数据在视频详情页里,需要我们点击链接进去才能看到:

今天的教程内容,就是教你如何利用 Web Scraper,在抓取一级页面(列表页)的同时,抓取二级页面(详情页)的内容。
1.创建 SiteMap
首先我们找到要抓取的数据的位置,关键路径我都在下图的红框里标出来了,大家可以对照一下:
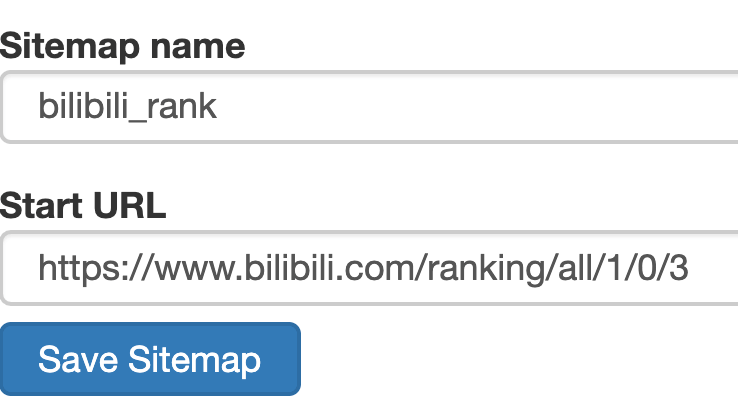
然后创建一个相关的 SiteMap,这里我取了个 bilibili_rank 的名字:
2.创建容器的 selector
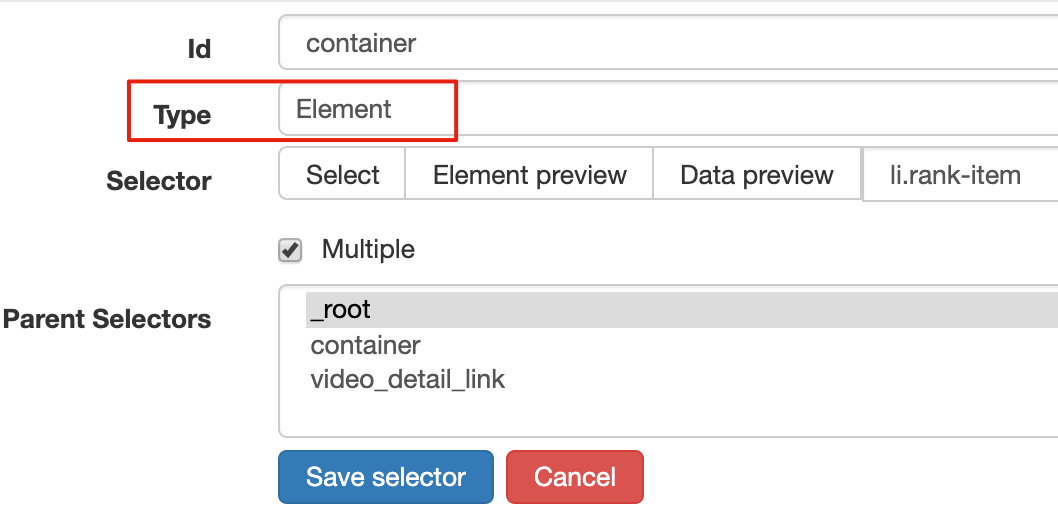
设置之前我们先观察一下,发现这个网页的排行榜数据是 100 条数据一次性加载完的,没有分页的必要,所以这里的 Type 类型选为 Element 就行。
其他的参数都比较简单,就不细说了(不太懂的可以看我之前的基础教程)这里截个图大家可以做个参考:
3.创建列表页子选择器
这次子选择器要抓取的内容如下,也都比较简单,截个图大家可以参考一下:
- 排名(num)
- 作品标题(title)
- 播放量(play_amount)
- 弹幕量(danmu_count)
- 作者:(author)

如果做到这一步,其实已经可以抓到所有已知的列表数据了,但本文的重点是:如何抓取二级页面(详情页)的三连数据?
跟着做了这么多爬虫,可能你已经发现了,Web Scraper 本质是模拟人类的操作以达到抓取数据的目的。
那么我们正常查看二级页面(详情页)是怎么操作的呢?其实就是点击标题链接跳转:

Web Scraper 为我们提供了点击链接跳转的功能,那就是 Type 为 Link 的选择器。
感觉有些抽象?我们对照例子来理解一下。
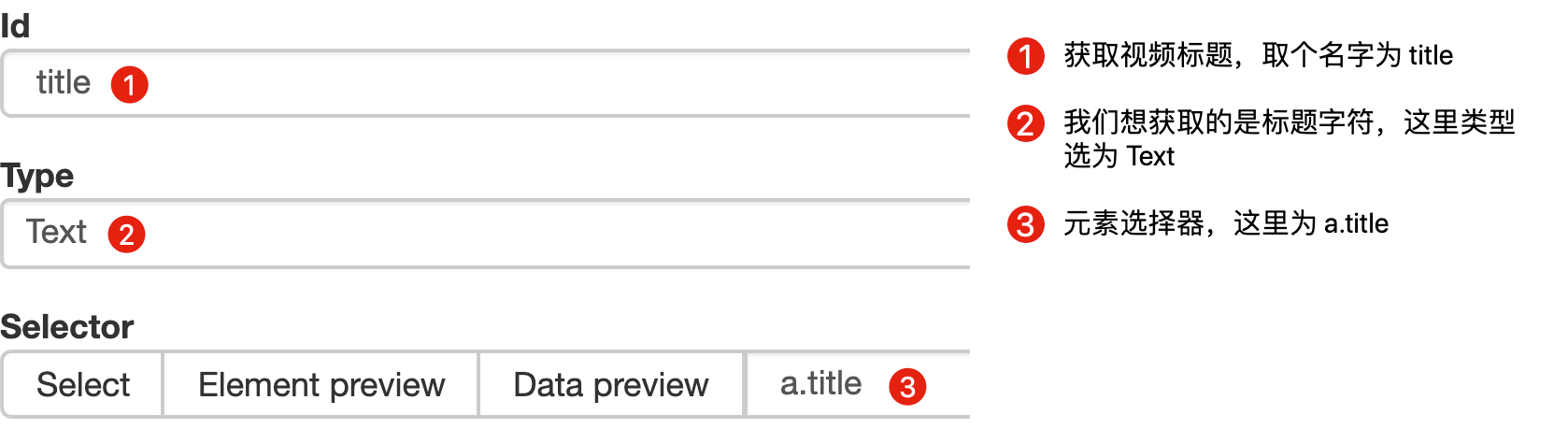
首先在这个案例里,我们获取了标题的文字,这时的选择器类型为 Text:
当我们要抓取链接时,就要再创建一个选择器,选的元素是一样的,但是 Type 类型为 Link:

创建成功后,我们点击这个 Link 类型的选择器,进入他的内部,再创建相关的选择器,下面我录了个动图,注意看我鼠标强调的导航路由部分,可以很清晰的看出这几个选择器的层级关系:
4.创建详情页子选择器
当你点击链接后就会发现,浏览器会在一个新的 Tab 页打开详情页,但是 Web Scraper 的选择窗口开在列表页,无法跨页面选择想要的数据。
处理这个问题也很简单,你可以复制详情页的链接,拷贝到列表页所在的 Tab 页里,然后回车重新加载,这样就可以在当前页面选择了。
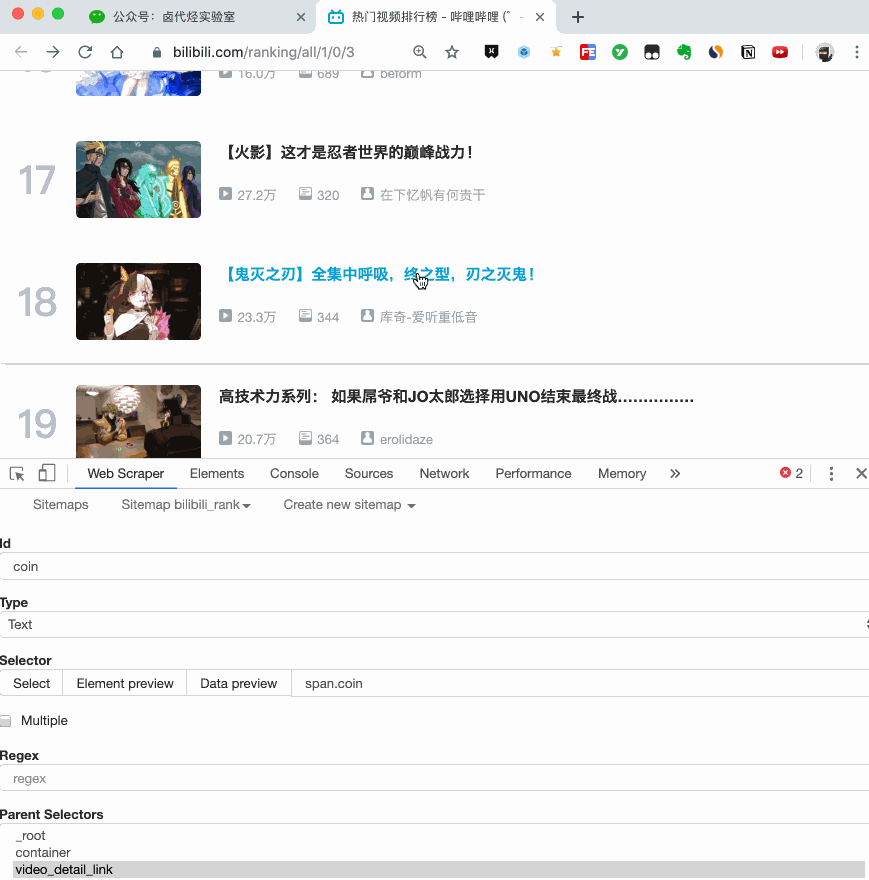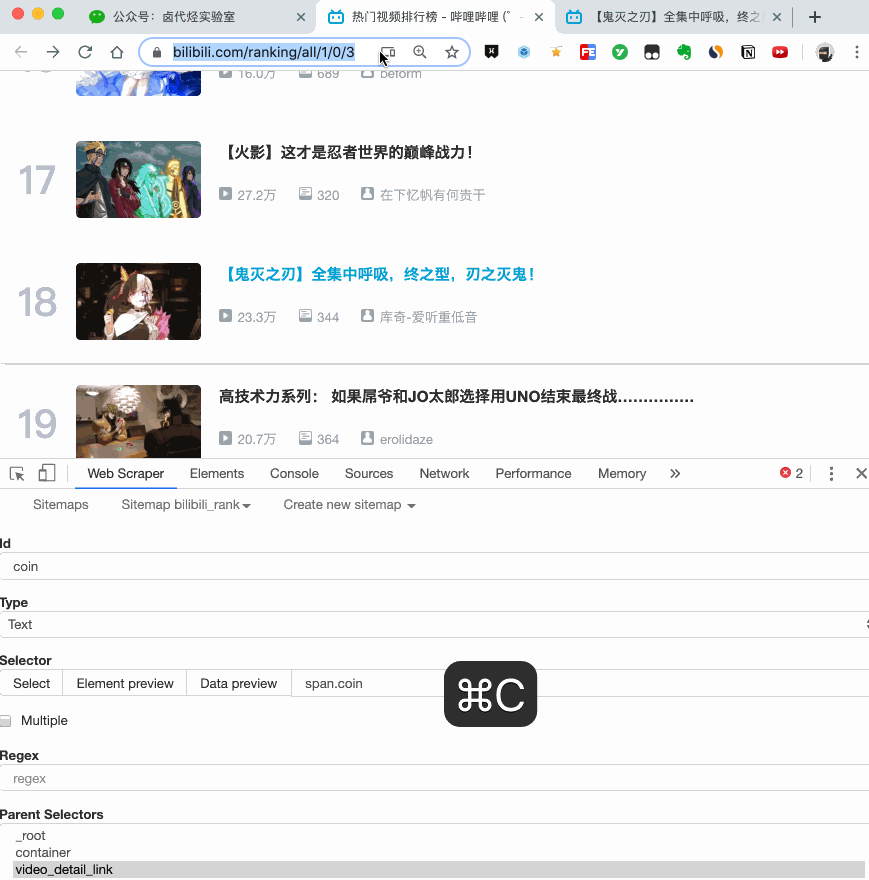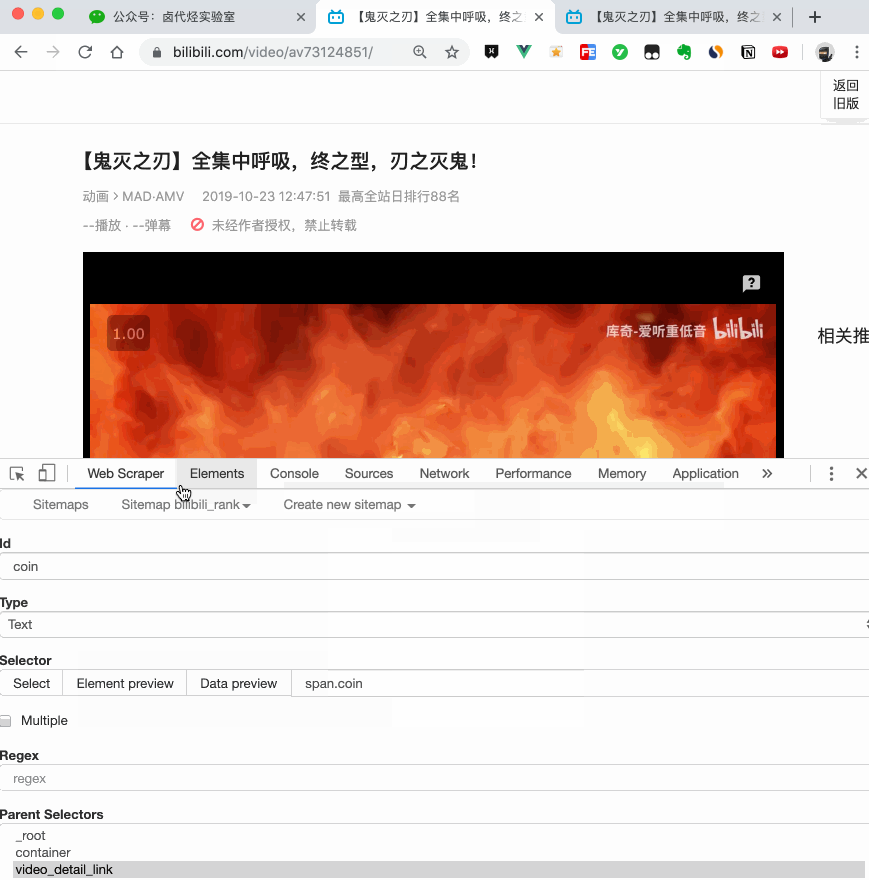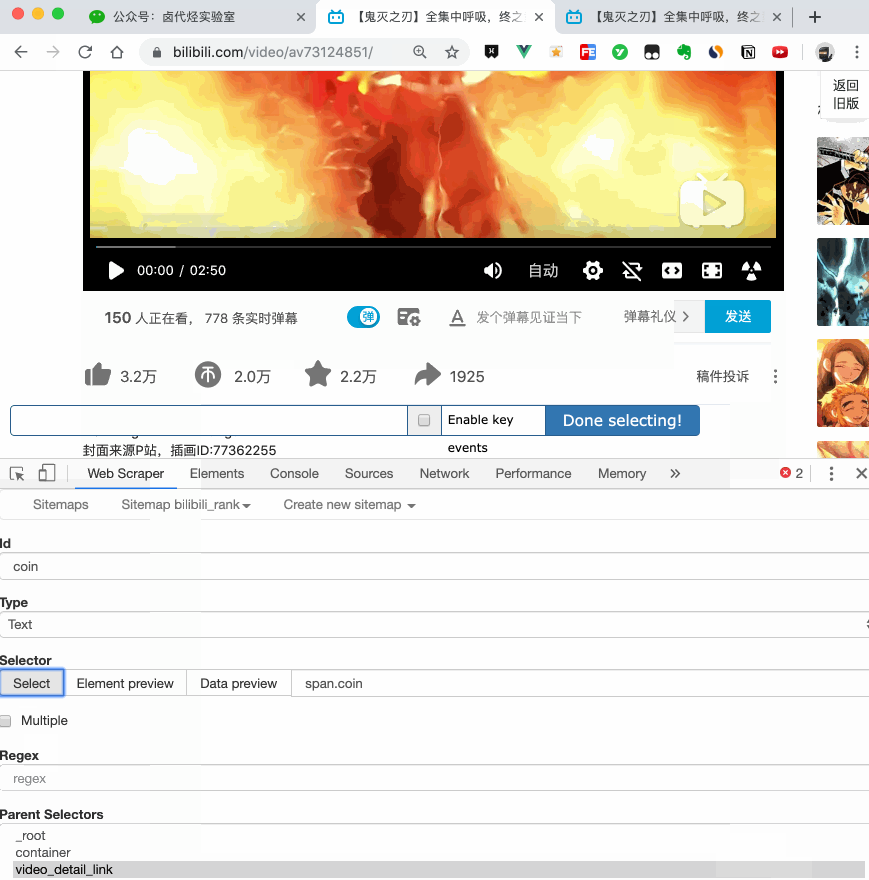
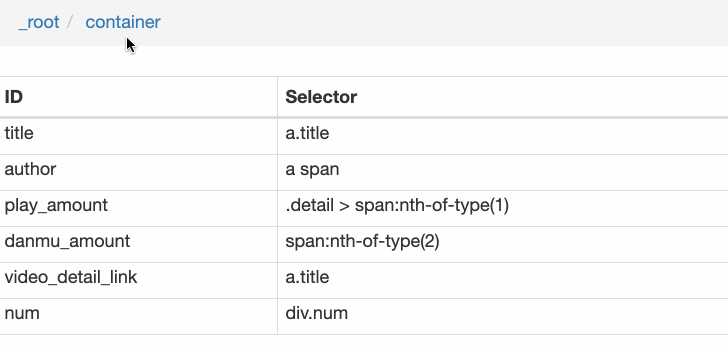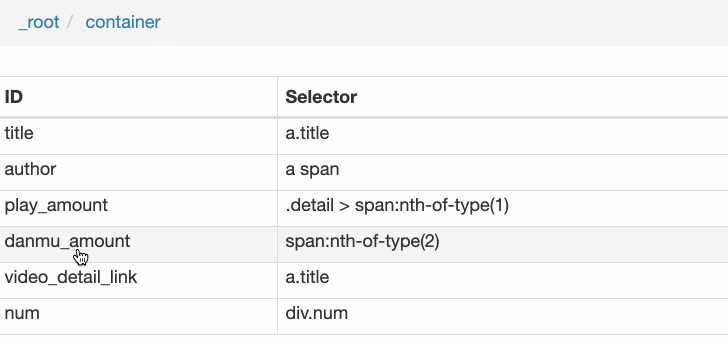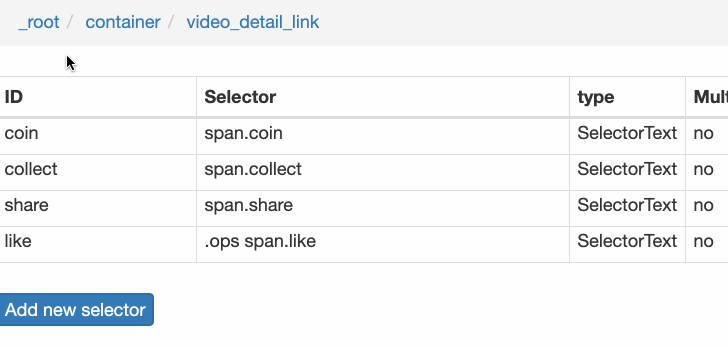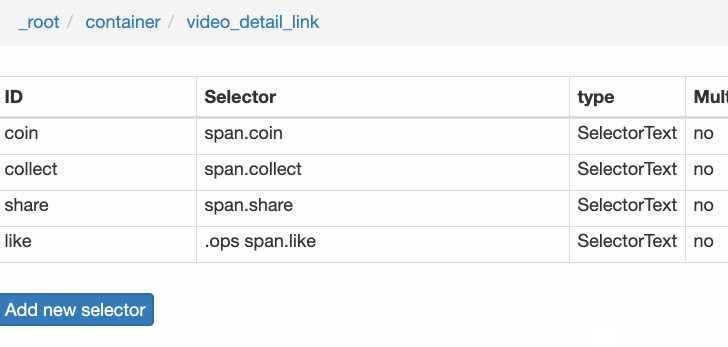
我们在类型为 Link 的选择器内部多创建几个选择器,这里我选择了点赞数、硬币数、收藏数和分享数 4 个数据,这个操作也很简单,这里我就不详细说了。

所有选择器的结构图如下:
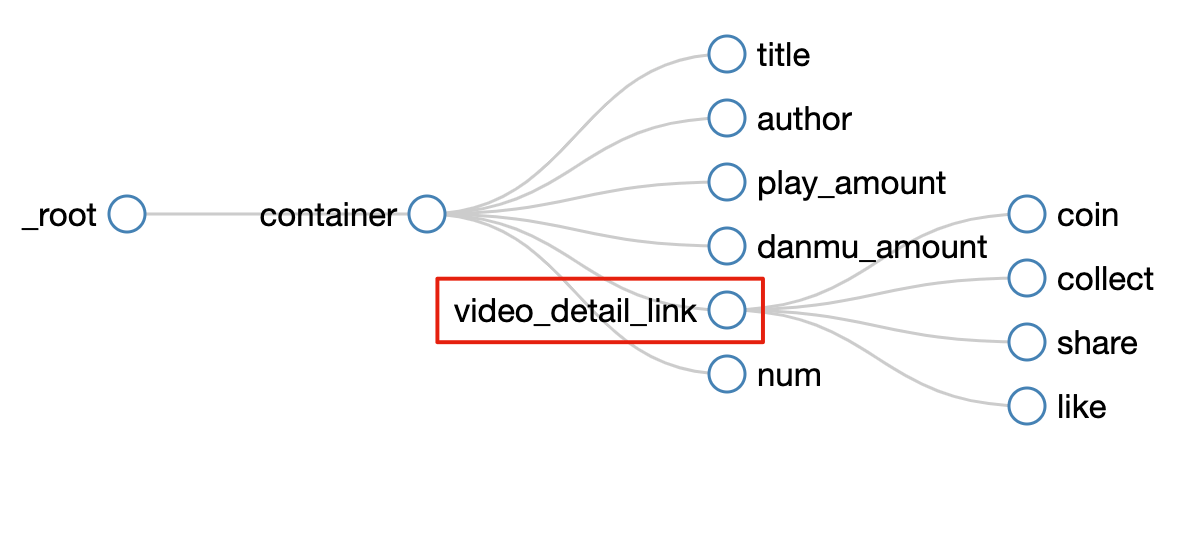
我们可以看到 video_detail_link 这个节点包含 4 个二级页面(详情页)的数据,到此为止,我们的子选择器已经全部建立好了。
5.抓取数据
终于到了激动人心的环节了,我们要开始抓取数据了。但是抓取前我们要把等待时间调整得大一些,默认时间是 2000 ms,我这里改成了 5000 ms。

为什么这么做?看了下图你就明白了:

首先,每次打开二级页面,都是一个全新的页面,这时候浏览器加载网页需要花费时间;
其次,我们可以观察一下要抓取的点赞量等数据,页面刚刚加载的时候,它的值是 「--」,等待一会儿后才会变成数字。
所以,我们直接等待 5000 ms,等页面和数据加载完成后,再统一抓取。
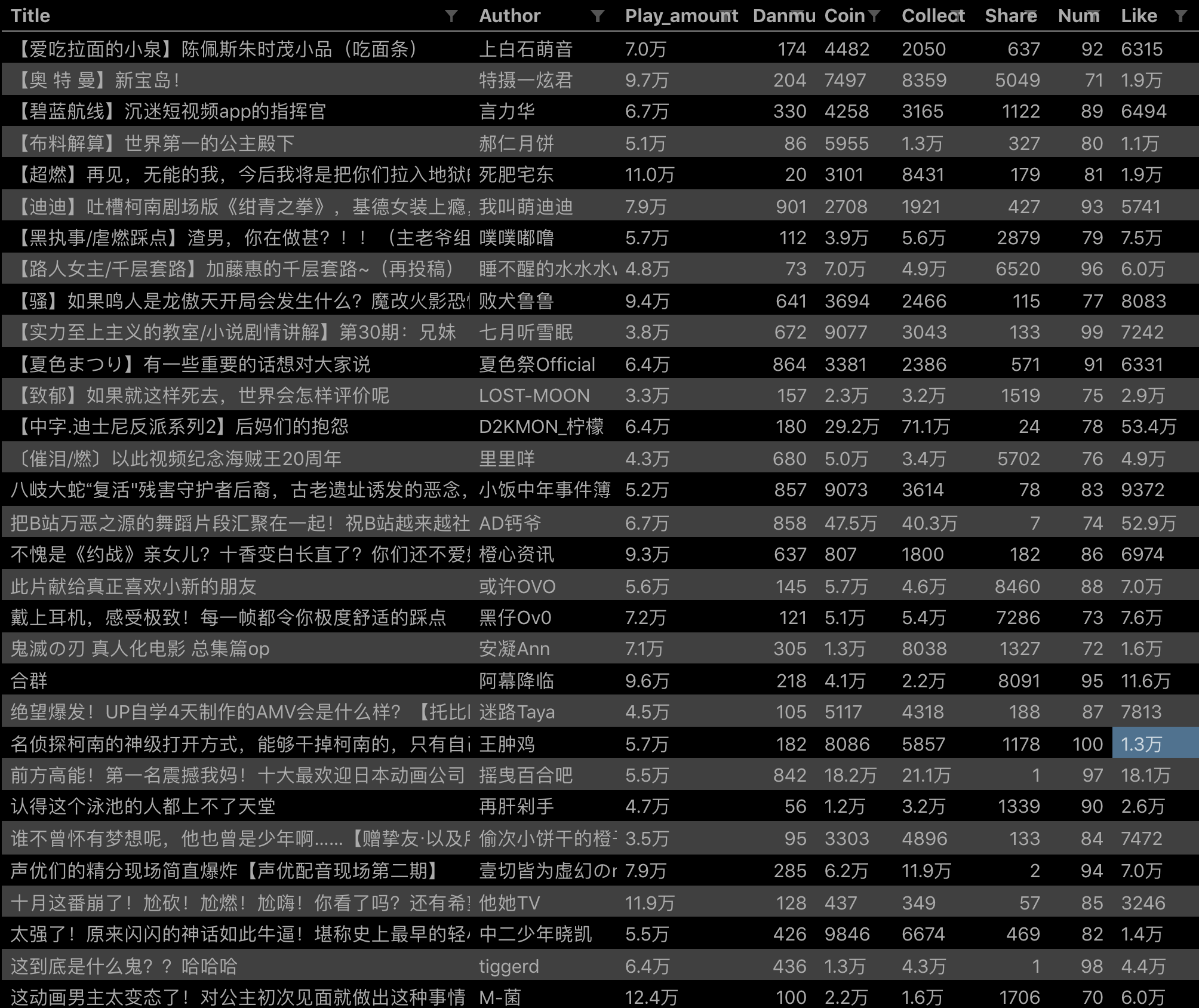
配置好参数后,我们就可以正式抓取并下载了。下图是我抓取数据的一部分,特此证明此方法有用:
6.总结
这次的教程可能有些难度,我把我的 SiteMap 分享出来,制作的时候如果遇到难题,可以参考一下我的配置,SiteMap 导入的功能我在第 6 篇教程里详细说明了,大家可以配合食用:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
当你掌握了二级页面的抓取方式后,三级页面、四级页面也不在话下。因为套路都是一样的:都是在 Link 选择器指向的下一个页面抓取数据,因为原理是一样的,我就不演示了。
7.推荐阅读
简易数据分析 06 | 如何导入别人已经写好的 Web Scraper 爬虫
简易数据分析 05 | Web Scraper 翻页——控制链接批量抓取数据
简易数据分析 08 | Web Scraper 翻页——点击「更多按钮」翻页
简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页
简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页
8.联系我
因为文章发在各大平台上,账号较多不能及时回复评论和私信,有问题可关注公众号 ——「卤蛋实验室」,(或 wx 搜索 egglabs)关注上车防失联。
