在有些场景下,我们要处理的时间间隔可能并不是固定的。比如,在交易系统中,需要实时地对每一笔交易进行核验,保证两个账户转入转出数额相等,也就是所谓的“实时对账”。两次转账的数据可能写入了不同的日志流,它们的时间戳应该相差不大,所以我们可以考虑只统计一段时间内是否有出账入账的数据匹配。这时显然不应该用滚动窗口或滑动窗口来处理——因为匹配的两个数据有可能刚好“卡在”窗口边缘两侧,于是窗口内就都没有匹配了;会话窗口虽然时间不固定,但也明显不适合这个场景。基于时间的窗口联结已经无能为力了。为了应对这样的需求,Flink提供了一种叫作“间隔联结”(interval join)的合流操作。顾名思义,间隔联结的思路就是针对一条流的每个数据,开辟出其时间戳前后的一段时间间隔,看这期间是否有来自另一条流的数据匹配。
1、间隔联结的原理
间隔联结具体的定义方式是,我们给定两个时间点,分别叫作间隔的“上界”(upperBound)和“下界”(lowerBound);于是对于一条流(不妨叫作A)中的任意一个数据元素a,就可以开辟一段时间间隔:[a.timestamp + lowerBound, a.timestamp + upperBound],即以a的时间戳为中心,下至下界点、上至上界点的一个闭区间:我们就把这段时间作为可以匹配另一条流数据的“窗口”范围。所以对于另一条流(不妨叫B)中的数据元素b,如果它的时间戳落在了这个区间范围内,a和b就可以成功配对,进而进行计算输出结果。所以匹配的条件为:
a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound
这里需要注意,做间隔联结的两条流A和B,也必须基于相同的key;下界lowerBound应该小于等于上界upperBound,两者都可正可负;间隔联结目前只支持事件时间语义。如下图所示,我们可以清楚地看到间隔联结的方式:
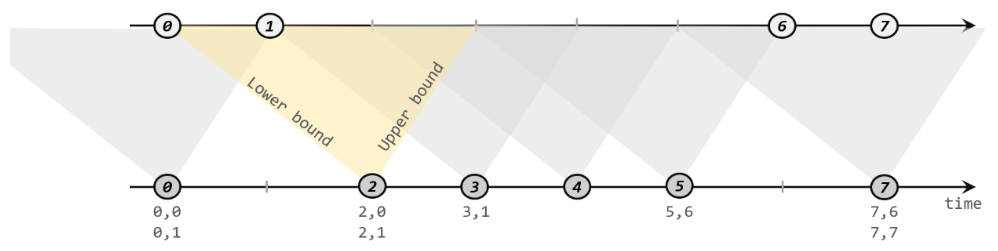
下方的流A去间隔联结上方的流B,所以基于A的每个数据元素,都可以开辟一个间隔区间。我们这里设置下界为-2毫秒,上界为1毫秒。于是对于时间戳为2的A中元素,它的可匹配区间就是[0, 3],流B中有时间戳为0、1的两个元素落在这个范围内,所以就可以得到匹配数据对(2, 0)和(2, 1)。同样地,A中时间戳为3的元素,可匹配区间为[1, 4],B中只有时间戳为1的一个数据可以匹配,于是得到匹配数据对(3, 1)。所以我们可以看到,间隔联结同样是一种内连接(inner join)。与窗口联结不同的是,interval join做匹配的时间段是基于流中数据的,所以并不确定;而且流B中的数据可以不只在一个区间内被匹配。
2、间隔联结的调用
间隔联结在代码中,是基于KeyedStream的联结(join)操作。DataStream在keyBy得到KeyedStream之后,可以调用.intervalJoin()来合并两条流,传入的参数同样是一个KeyedStream,两者的key类型应该一致;得到的是一个IntervalJoin类型。后续的操作同样是完全固定的:先通过.between()方法指定间隔的上下界,再调用.process()方法,定义对匹配数据对的处理操作。调用.process()需要传入一个处理函数,这是处理函数家族的最后一员:“处理联结函数”ProcessJoinFunction。
/** * Interval Join */ public class IntervalJoinTest { public static void main(String[] args) throws Exception { //1、获取执行时间 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //1.1、便于测试,测试环境设置并行度为 1,生产环境记得设置为 kafka topic 的分区数 env.setParallelism(1); //2.1、读取数据 声明水位线 SingleOutputStreamOperator<Tuple2<String, Long>> stream = env.fromElements( Tuple2.of("依琳", 5000L), Tuple2.of("令狐冲", 5000L), Tuple2.of("依琳", 20000L), Tuple2.of("令狐冲", 20000L), Tuple2.of("依琳", 51000L)) .assignTimestampsAndWatermarks(WatermarkStrategy .<Tuple2<String, Long>>forBoundedOutOfOrderness(Duration.ofSeconds(2)) .withTimestampAssigner(new SerializableTimestampAssigner<Tuple2<String, Long>>() { @Override public long extractTimestamp(Tuple2<String, Long> element, long recordTimestamp) { return element.f1; } })); //2.2、读取数据 声明水位线 SingleOutputStreamOperator<Event> stream1 = env.fromElements( new Event("令狐冲", "/home", 1000L), new Event("依琳", "/cat", 9000L), new Event("任盈盈", "/pay", 36000L), new Event("依琳", "/info?id=2", 30000L), new Event("任盈盈", "/home", 23000L), new Event("依琳", "/error", 33000L)) .assignTimestampsAndWatermarks(WatermarkStrategy .<Event>forBoundedOutOfOrderness(Duration.ofSeconds(2)) .withTimestampAssigner(new SerializableTimestampAssigner<Event>() { @Override public long extractTimestamp(Event event, long recordTimestamp) { return event.timestamp; } })); //keyby 后 进行 intervalJoin stream.keyBy(data -> data.f0) .intervalJoin(stream1.keyBy(data -> data.user)) .between(Time.seconds(-5), Time.seconds(10)) .process(new ProcessJoinFunction<Tuple2<String, Long>, Event, String>() { @Override public void processElement(Tuple2<String, Long> left, Event right, Context ctx, Collector<String> out) throws Exception { out.collect(right + " -> " + left); } }).print(); env.execute(); } }
运行效果
Event{user='令狐冲', url='/home', timestamp=1970-01-01 08:00:01.0} -> (令狐冲,5000)
Event{user='依琳', url='/cat', timestamp=1970-01-01 08:00:09.0} -> (依琳,5000)
Event{user='依琳', url='/info?id=2', timestamp=1970-01-01 08:00:30.0} -> (依琳,20000)