1、需求分析
1.1、当日新增付费用户分析
按省份|用户性别|用户年龄段,统计当日新增付费用户首单平均消费及人数占比无论是省份名称、用户性别、用户年龄,订单表中都没有这些字段,需要订单(事实表)和维度表(省份、用户)进行关联,形成宽表后将数据写入到ES,通过Kibana进行分析以及图形展示。
1.2、整体实时计算框架
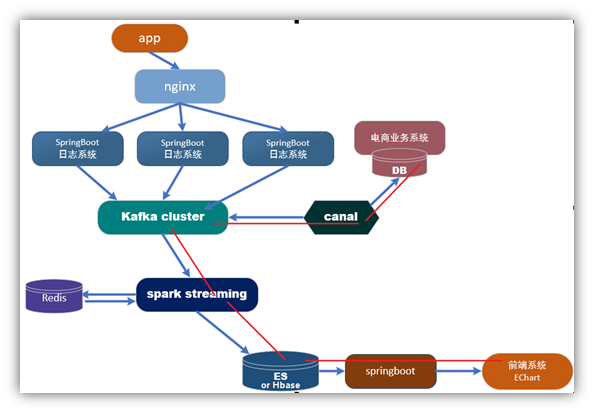
1.3、具体业务流程
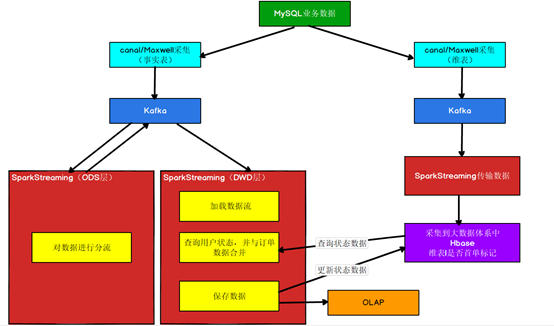
1.4、实现方案
第一步:从MySQL数据库中采集业务数据到Kafka,并对数据进行分流处理(ODS层),分流数据处理之后,将数据写回Kafka。我们这里使用canal和Maxwell两种方式实现
第二步:每笔订单都要判断是否是该用户的首单判断是否首单的要点,在于该用户之前是否参与过消费(下单)。那么如何知道用户之前是否参与过消费,如果临时从所有消费记录中查询,是非常不现实的。那么只有将“用户是否消费过”这个状态进行保存并长期维护起来。在有需要的时候通过用户id进行关联查询。在实际生产中,这种用户状态是非常常见的比如“用户是否退过单”、“用户是否投过诉”、“用户是否是高净值用户”等等。我们要想保存状态,大家可能会想到在Redis中保存,Reids可以实现,但是这个状态可能包含历史数据,数据量比较大,而且历史数据保存在内存中,对内存压力也比较大。所以考虑到
- 这是一个保存周期较长的数据。
- 必须可修改状态值。
- 查询模式基本上是k-v模式的查询
所以综上这三点比较,状态适合保存在Hbase中
第3步:在查询订单的时候,订单与Hbase中省份和用户的维度表进行关联,才能获取省份名称、用户性别、用户年龄等对应字段,完成后面的统计。
2、数据采集——canal 实现
2.1、canal 入门
2.1.1、canal 是什么
阿里巴巴B2B公司,因为业务的特性,卖家主要集中在国内,买家主要集中在国外,所以衍生出了同步杭州和美国异地机房的需求,从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务。canal是用java开发的基于数据库增量日志解析,提供增量数据订阅&消费的中间件。目前,canal主要支持了MySQL的binlog解析,解析完成后才利用canal client来处理获得的相关数据。(数据库同步需要阿里的otter中间件,基于canal)。
2.1.2、canal 使用场景
(1) 原始场景: 阿里otter中间件的一部分otter是阿里用于进行异地数据库之间的同步框架,canal是其中一部分。
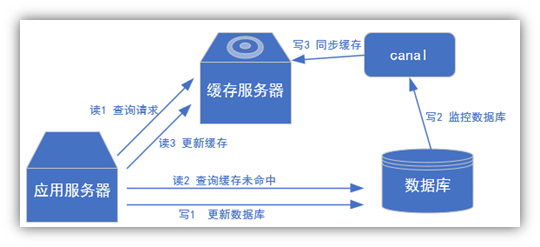
(2) 常见场景1:更新缓存
(3) 常见场景2:抓取业务数据新增变化表,用于制作拉链表。
(4) 常见场景3:抓取业务表的新增变化数据,用于制作实时统计(此处就是这种场景)
2.1.3、canal 工作原理
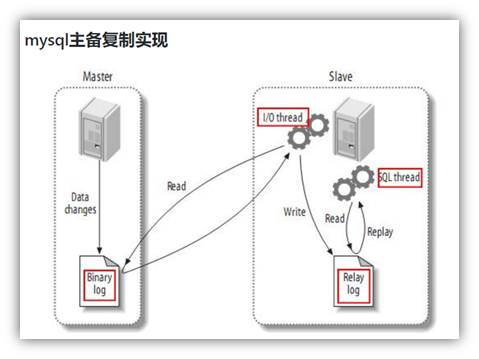
(1) MySQL主从复制过程
- Master主库将变更记录,写到二进制日志(binary log)中
- Slave从库向mysql master发送dump协议,将master主库的binary log events拷贝到它的中继日志(relay log);
- Slave从库读取并重做中继日志中的事件,将改变的数据同步到自己的数据库
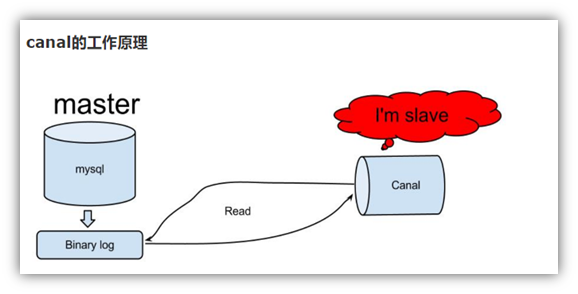
(2) canal的工作原理
很简单,就是把自己伪装成slave,假装从master复制数据
2.1.4、Mysql binlog
什么是binlog?
MySQL的二进制日志可以说MySQL最重要的日志了,它记录了所有的DDL和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的。般来说开启二进制日志大概会有1%的性能损耗。二进制有两个最重要的使用场景:
- 其一:MySQL Replication在Master端开启binlog,Master把它的二进制日志传递给slaves来达到master-slave数据一致的目的。
- 其二:自然就是数据恢复了,通过使用mysqlbinlog工具来使恢复数据。
二进制日志包括两类文件:二进制日志索引文件(文件名后缀为.index)用于记录所有的二进制文件,二进制日志文件(文件名后缀为.00000*)记录数据库所有的DDL和DML(除了数据查询语句)语句事件。
如何开启 binlog?
找到MySQL配置文件的位置
[hui@hadoop201 ~]$ locate my.cnf
/etc/my.cnf
使用root 用户编辑该配置文件
在[mysqld] 区块,设置/添加 log-bin=mysql-bin
这个表示binlog日志的前缀是mysql-bin,以后生成的日志文件就是 mysql-bin.123456 的文件后面的数字按顺序生成,每次mysql重启或者到达单个文件大小的阈值时,新生一个文件,按顺序编号。
binlog的分类设置
mysql binlog的格式有三种,分别是STATEMENT,MIXED,ROW。在配置文件中可以选择配置 binlog_format= statement|mixed|row
n statement
语句级,binlog会记录每次一执行写操作的语句。
相对row模式节省空间,但是可能产生不一致性,比如
update tt set create_date=now()
如果用binlog日志进行恢复,由于执行时间不同可能产生的数据就不同。
优点: 节省空间
缺点: 有可能造成数据不一致。
n row
行级, binlog会记录每次操作后每行记录的变化。
优点:保持数据的绝对一致性。因为不管sql是什么,引用了什么函数,他只记录执行后的效果。
缺点:占用较大空间。
n mixed
statement的升级版,一定程度上解决了,因为一些情况而造成的statement模式不一致问题
默认还是statement,在某些情况下譬如:
当函数中包含 UUID() 时;
包含 AUTO_INCREMENT 字段的表被更新时;
执行 INSERT DELAYED 语句时;
用 UDF 时;
会按照 ROW的方式进行处理
优点:节省空间,同时兼顾了一定的一致性。
缺点:还有些极个别情况依旧会造成不一致,另外statement和mixed对于需要对binlog的监控的情况都不方便。
综合上面对比,Cannel想做监控分析,选择row格式比较合适
2.2、mysql 数据库准备
2.2.1、创建数据库
创建数据库
CREATE DATABASE `gmall0423` /*!40100 DEFAULT CHARACTER SET utf8 */
执行初始化建表脚本
2.2.2、修改 my.cnf
server-id= 1 log-bin=mysql-bin binlog_format=row binlog-do-db=gmall0423 #注意:binlog-do-db根据自己的情况进行修改,指定具体要同步的数据库 #若监控多个数据库,可以再写一行 binlog-do-db=db_name
sudo systemctl restart mysqld
创建canal 数据库并赋权
CREATE DATABASE `canal` /*!40100 DEFAULT CHARACTER SET utf8 */ mysql> SET GLOBAL validate_password_length=4; mysql> SET GLOBAL validate_password_policy=0; mysql> GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%' IDENTIFIED BY 'canal' ;
2.3、canal 安装
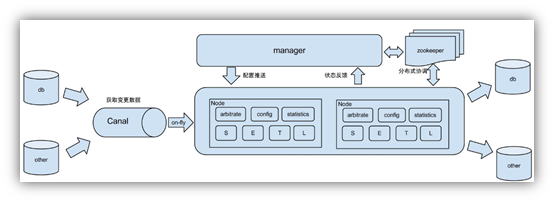
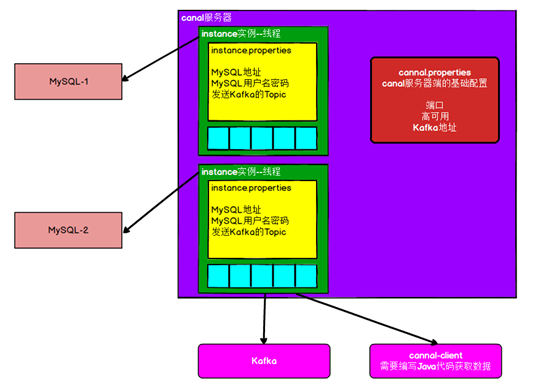
2.3.1、canal 架构
2.3.2、canal 安装&配置
注意:canal解压后是散的,我们在指定解压目录的时候需要将canal指定上
mkdir /opt/module/canal
tar -zxvf canal.deployer-1.1.4.tar.gz -C /opt/module/canal
配置
/opt/module/canal/conf [hui@hadoop201 conf]$ less canal.properties # tcp, kafka, RocketMQ #更改 canal的输出model,默认tcp,改为输出到kafka,tcp就是输出到canal客户端,通过编写Java代码处理 canal.serverMode = kafka #修改Kafka集群的地址 canal.mq.servers = hadoop201:9092,hadoop202:9092,hadoop203:9092
注意:如果创建多个实例通过前面canal架构,我们可以知道,一个canal服务中可以有多个instance,conf/下的每一个example即是一个实例,每个实例下面都有独立的配置文件。默认只有一个实例example,如果需要多个实例处理不同的MySQL数据的话,直接拷贝出多个example,并对其重新命名,命名和配置文件中指定的名称一致,然后修改canal.properties中的canal.destinations=实例1,实例2,实例3。
################################################# ######### destinations ############# ################################################# canal.destinations = example
修改instance.properties:这里只读取一个MySQL数据,所以只有一个实例,这个实例的配置文件在conf/example目录下
#mysql 地址 canal.instance.master.address=hadoop201:3306 # username/password canal.instance.dbUsername=canal canal.instance.dbPassword=canal # mq config #输出的topic canal.mq.topic=gmall0426_db_canal # dynamic topic route by schema or table regex #canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..* #canal.mq.partition=0 # hash partition config #注意:默认还是输出到指定Kafka主题的一个kafka分区,因为多个分区并行可能会打乱binlog的顺序 #如果要提高并行度,首先设置kafka的分区数>1,然后设置canal.mq.partitionHash属性 canal.mq.partitionsNum=4 canal.mq.partitionHash=*\\..*${pk}$
2.3.4、canal 测试
启动canal
[hui@hadoop201 example]$ /opt/module/canal/bin/stop.sh [hui@hadoop201 example]$ jps 1562 Jps 1548 CanalLauncher
启动zk,kafka 开启消费测试
bin/kafka-console-consumer.sh --bootstrap-server hadoop201:9092 --topic gmall0426_db_canal
启动数据库模拟生成数据,观察消费情况
[hui@hadoop201 rt_dblog]$ java -jar gmall2020-mock-db-2020-05-18.jar
消费到数据格式:
{ "data":[ { "id":"344", "activity_id":"2", "order_id":"3488", "create_time":"2022-04-23 04:45:53" } ], "database":"gmall0423", "es":1651783554000, "id":20, "isDdl":false, "mysqlType":{ "id":"bigint(20)", "activity_id":"bigint(20)", "order_id":"bigint(20)", "create_time":"datetime" }, "old":null, "pkNames":[ "id" ], "sql":"", "sqlType":{ "id":-5, "activity_id":-5, "order_id":-5, "create_time":93 }, "table":"activity_order", "ts":1651783563724, "type":"INSERT" }
2.4、canal 版本的 ods 层数据分流
2.4.1、数据格式
样例SQL
INSERT INTO user_info VALUES(16,'zhang3','13810001010'),(17,'zhang3','13810001010');
canal 接收的数据格式
{"data":[{"id":"16","user_name":"zhang3","tel":"13810001010"},{"id":"17","user_name":"zhang3","tel":"13810001010"}],"database":"gmall-2020-04","es":1589196502000,"id":4,"isDdl":false,"mysqlType":{"id":"bigint(20)","user_name":"varchar(20)","tel":"varchar(20)"},"old":null,"pkNames":["id"],"sql":"","sqlType":{"id":-5,"user_name":12,"tel":12},"table":"user_info","ts":1589196502433,"type":"INSERT"}
2.4.2、分流逻辑
canal会追踪整个数据库的变更,把所有的数据变化都发到一个topic中了,但是为了后续处理方便,应该把这些数据根据不同的表,分流到不同的主题中去。
kafka 发送工具类
import java.util.Properties
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
/**
* 发送数据到 kafka
*/
object MyKafkaSink {
//加载配置文件
private val properties: Properties = MyPropertiesUtil.load("config.properties")
//获取kafka连接信息
val broker_list = properties.getProperty("kafka.broker.list")
var kafkaProducer: KafkaProducer[String, String] = null
//创建 producer
def createKafkaProducer: KafkaProducer[String, String] = {
val properties = new Properties
properties.put("bootstrap.servers", broker_list)
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
properties.put("enable.idempotence", (true: java.lang.Boolean))
var producer: KafkaProducer[String, String] = null
try
producer = new KafkaProducer[String, String](properties)
catch {
case e: Exception =>
e.printStackTrace()
}
producer
}
def send(topic: String, msg: String): Unit = {
if (kafkaProducer == null) kafkaProducer = createKafkaProducer
kafkaProducer.send(new ProducerRecord[String, String](topic, msg))
}
def send(topic: String, key: String, msg: String): Unit = {
if (kafkaProducer == null) kafkaProducer = createKafkaProducer
kafkaProducer.send(new ProducerRecord[String, String](topic, key, msg))
}
}
分流逻辑
package org.wdh01.gmall.realtime.ods
import com.alibaba.fastjson.{JSON, JSONArray, JSONObject}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{HasOffsetRanges, OffsetRange}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.wdh01.gmall.realtime.util.{MyKafkaSink, MyKafkaUtil, OffsetManagerUtil}
/**
* 从 kafka 读取数据,根据表名进行分流
*/
object BaseDBCanalApp {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("BaseDBCanalApp").setMaster("local[4]")
val ssc: StreamingContext = new StreamingContext(conf, Seconds(5))
var topic: String = "gmall0426_db_canal"
var groupid: String = "base_db_db_canal_group"
//从 redis 获取偏移量信息
var recordDstream: InputDStream[ConsumerRecord[String, String]] = null
val offsetMap: Map[TopicPartition, Long] = OffsetManagerUtil.getOffset(topic, groupid)
if (offsetMap != null && offsetMap.size > 0) {
//从偏移量位置开始小飞虫
recordDstream = MyKafkaUtil.getKafkaStream(topic, ssc, offsetMap, groupid)
} else {
//从起始位置开始小飞虫
recordDstream = MyKafkaUtil.getKafkaStream(topic, ssc, groupid)
}
var ranges: Array[OffsetRange] = Array.empty[OffsetRange]
//获取当前批次的偏移量信息
val offsetDStream: DStream[ConsumerRecord[String, String]] = recordDstream.transform {
rdd => {
ranges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
}
rdd
}
//对接收数据进行结构转换
val jsonObjDstream: DStream[JSONObject] = offsetDStream.map {
record => {
//json 格式字符串
val jsonStr: String = record.value()
val jsonObj: JSONObject = JSON.parseObject(jsonStr)
jsonObj
}
}
//分流 根据表名 发送到不同的 topic
jsonObjDstream.foreachRDD {
rdd => {
rdd.foreach {
jsonObj => {
//获取操作类型
val opType: String = jsonObj.getString("type")
if ("INSERT".equals(opType)) {
//获取表名
val tabName: String = jsonObj.getString("table")
//获取数据
val dataArray: JSONArray = jsonObj.getJSONArray("data")
//拼接要要发送的topic
val sednTopic: String = "ods_" + tabName
//遍历数组
import scala.collection.JavaConverters._
for (data <- dataArray.asScala) {
//根据表名分流
MyKafkaSink.send(sednTopic, data.toString)
}
}
}
}
//提交偏移量
OffsetManagerUtil.saveOffset(topic, groupid, ranges)
}
}
ssc.start()
ssc.awaitTermination()
}
}