MapReduce定义
Map Reduce 是一个分布式运算程序的编程框架,是用户开发“基于 Hadoop 的数据分析” 应用的核心框架 ,Map Reduce 的核心功能是将用户编写的业务逻辑代码和自带的默认组件,整合成完整的分布式应用程序,并发运行在 Hadoop 集群上。
为什么要引入 MapReduce?
- 海量数据如果在单个节点上处理因为硬件资源限制,无法胜任;
- 而一旦将单节点程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难度;
- 引入 MapReduece 框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将分布式计算中的复杂性交由框架来处理;
MapReduce 特点
1、Map Reduce 易于编程 它简单实现了一些接口,就可以完成一个分布式程序,这个分布式程序可以分发到大量的廉价的PC机器上进行运行,也就是说:这里写一个分布式程序和写一个普通的程序是一样的,因此:使 Map Reduce 编程很是流行;
2、适合 PB 级以上海量数据的离线处理;可以实现成千台服务器集群并发工作;提供数据处理能力;
3、不擅长实时数据计算:Map Reduce 无法像 Mysql 一样在毫秒或秒级内返回结果;
4、不擅长流式计算;流式的数据计算的输入是动态的,而 Map Reduce 的输入是静态的,不能动态变化,这是由于 Map Reduce 的设计特点决定了其输入数据是静态数据;
5、不擅长(DAG) 右向图计算 多个应用程序存在依赖关系,后一个应用程序的输入为前一个应用程序的输出,在这种情况下,Map Redeuce 并不是不能做,而是使用后,每个 Map Reduce 的输出结果都会写入磁盘,导致大量的磁盘IO,从而使性能下降。
MapReduce 核心思想
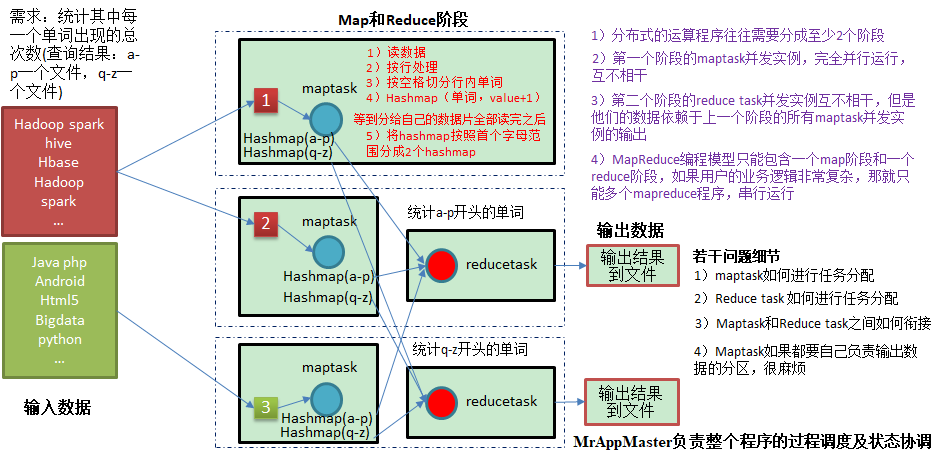
1)分布式的运算程序往往需要分成至少2个阶段。
2)第一个阶段的MapTask并发实例,完全并行运行,互不相干。
3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
总结:分析WordCount数据流走向深入理解MapReduce核心思想。
MapReduce 进程:
- MrAppMaster:负责整个程序的过程调度和状态协调;
- MapTask 负责整个 Map 阶段的数据处理流程;
- ReduceTask 负责整个 Reduce 阶段数据处理流程
MapReduce 官方 pi 程序演示
[hui@hadoop103 data]$ cd /opt/module/hadoop-2.7.2/share/hadoop/mapreduce/ [hui@hadoop103 mapreduce]$ pwd /opt/module/hadoop-2.7.2/share/hadoop/mapreduce [hui@hadoop103 mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.7.2.jar pi 5 5
MapReduce 官方 wordcount 程序演示
数据准备:
[hui@hadoop103 wcinput]$ cat wc.input tianyi huichao lihua zhangchen xiaoheng xinbo xinbo gaoyang gaoyang yanjing yanjing [hui@hadoop103 wcinput]$ pwd /opt/module/hadoop-2.7.2/wcinput
[hui@hadoop103 mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.7.2.jar wordcount /wcinput/ /wcoutput/
结果就是一个统计单词的频次的数据结果;
Windows 系统 wordcount 程序


package org.wdh01.mr.wordcount; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; /** * Map 阶段处理 * * @author hui * */ //KEYIN LongWritable 输入数据 Key //VALUEIN 输入数据的 Value //KEYOUT 输出数据类型 //VALUEOUT 输出数据Value 类型 public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { Text k = new Text(); IntWritable v = new IntWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // hui hu1 // 1、|获取一行 String line = value.toString(); // 2、切割单词 String[] words = line.split(" "); // 3、循环输出 for (String word : words) { k.set(word); context.write(k, v); } } }
package org.wdh01.mr.wordcount; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; //KEYIN, VALUEIN map 阶段的输出 public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> { IntWritable v = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; // 1、累加求和 for (IntWritable value : values) { sum += value.get(); } v.set(sum); // 2、写出 context.write(key, v); } }
package org.wdh01.mr.wordcount; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.Job; public class WordCountDriver { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); // 1、获取 job 对象 Job job = Job.getInstance(conf); // 2、设置 jar 存放位置通过 反射查找 job.setJarByClass(WordCountDriver.class); // 3、关联 MR job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReduce.class); // 4、设置 Map 阶段输出数据的 KV 类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 5、设置 最终数据的 KV 类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 6、设置程序的输入路径和输出路径 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 7、提交 job Boolean result = job.waitForCompletion(true); } }
MapReduce 编码规范
用户编写程序分为 3 个部分:Map 、Reduce 和 Driver
1、Mapper 阶段
用户编写的 Mapper 要继承自己的父类;
Mapper 阶段的输入类型时 KV 形式;
Mapper 的业务逻辑写在 map() 方法中;
Mapper 的输出使是 KV 形式;
map() 方法(MapTask 进程) 对每一个 KV 调用一次
2、Reduce 阶段
用户自己编写的Reduce 程序要继承自己的父类;
Reduce 程序的输入对应的是 Map 程序的输出,也是 KV 形式;
Reduec 的业务逻辑写在 reduce() 方法中;
Reduce 对每个相同的 K 的 KV 数据只调用一次;
3、Driver 阶段
相当于 YARN 集群的客户端,用于提交整个程序到 YARN 集群,提交的是 封装了 MR 带有参数的 JOB 对象;