Elasticsearch查询原理浅析
由于最近参与的项目中用到了Elasticsearch,所以学习了解了一下,这里做一个简单对ES的查询原理做一个学习总结,限于作者水平,如有错误,欢迎批评指正。
一、概述
Elasticsearch作为一个开源的高扩展的分布式全文搜索引擎。最为人称道就是它对于海量数据近乎实时的强大搜索能力了。这里我们从索引的角度来分析一下,为什么Elasticsearch能够实现快速的检索。
二、索引结构
Elasticsearch索引的精髓:
一切设计都是为了提高搜索的性能
为了提高搜索的性能,难免会牺牲某些其他方面的性能,比如插入、更新。假如我们插入一个JSON的对象,Elasticsearch会为每一个Field建立索引。Elasticsearch底层使用的Lucene的倒排索引技术来实现比关系型数据库更快的过滤的。所以要想了解Lucene的倒排索引,需要先介绍一下Lucene的数据模型。
2.1 Lucene的数据模型
Lucene中包含四种基本数据类型,分别是:
- Index: 索引,由很多Document组成。相当与MySQL中数据库的概念。
- Document:由很多Field组成。相当与MySQL中Row的概念。也是查询结果的最小单位。
- Field: 由很多Term组成,包括Field Name和Field Value.
- Term: 由很多字节组成。常译为单词,一般将Text类型中的Field Value分词之后的最小单元叫做Term,如果是数值类型或者布尔型这种不可分的类型,那Field Value直接就是Term。
2.2 倒排索引
倒排索引(Inverted Index)又称反向索引,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引。
Lucene的倒排索引结构如下;

下面通过具体的例子来介绍一下,这三个结构的具体概念。
假设有如下数据:
| docid | name | age | sex |
|---|---|---|---|
| 1 | Kate | 18 | Female |
| 2 | John | 18 | Male |
| 3 | Bill | 20 | Male |
这里每一个行都是一个document, 每个document都是一个文档编号docid,由Lucene自建的文档唯一标识。
那么,Elasticsearch建立的索引如下:
name:
| Term | PostingList |
|---|---|
| Kate | 1 |
| John | 2 |
| Bill | 3 |
age:
| Term | PostingList |
|---|---|
| 18 | 1, 2 |
| 20 | 3 |
sex:
| Term | PostingList |
|---|---|
| Female | 1 |
| Male | 2, 3 |
2.2.1 Posting List
从上面例子可以看出,Elastictsearch为每个Field都建立了一个倒排索引。
Posting List就是一个int的数组,存储了所有符合某个Term的文档id。
优点:
- 通过这种方式,我们已经可以快速地通过属性值,查找到相应的文档,而不用遍历所有的文档来查询。从而大大提升了查询效率。
问题:
- 如果Term的候选值很多,成千上百万,那该如何查询?
2.2.2 Term Dictionary
Term Dictionary是所有单词(Term)的不重复有序列表。
为了解决上面的这个问题,提升查找效率,Elasticsearch需要预先将Term Dictionary排序,这样才能二分查找,实现logN的查询效率。
2.2.3 Term Index
B树/B+树索引,为了提升查询性能,减少磁盘寻道次数,会将索引树频繁使用的上几层换入内存。
而ES中,一般来讲Term Dictionary会很大,放内存不现实,而且也不是树形结构,没办法像B树/B+树那样部分换入内存,提高性能。
所以,Lucene又单独为Term Dictionary创建了一个索引——Term Index。用来记录以不同前缀开头的Term分别在Term Dictionary的起始位置。
这个Term Index可以用HashMap来实现,当需要查找一个Term时,可以通过Hash前缀找到目标在Term Dictionary的起止点,然后二分,直到命中,得到Posting List。
但是,从Lucene4开始,为了实现范围查询、前缀、后缀等复杂的查询语句,以及减少内存使用,Lucene采用了FST(Finite State Transducer)来存储Term Index。
2.2.4 FST
FST(Finite State Transducer)直译为有限状态传感器。下面通过Alice和Alan这两个单词,来看下FST的构建过程。
插入“Alan”
插入“Alice”


这样就得到了一个加权有向无环图,每条路径上都有权重,权重相加,即得前缀在Term Dictionary上的起始位置。
FST通过前缀实现了对状态的压缩。实际的FST还可以开启后缀压缩,从而实现更快的后缀搜索。
FST在单个Term的查询相比HashMap没有明显优势,甚至会慢一些,但是在范围、前缀搜索以及压缩率方面优势明显。
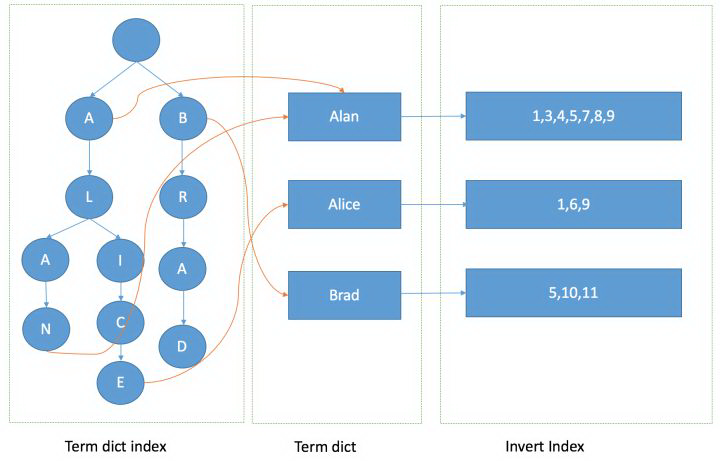
2.2.5 整体结构
有了FST之后,Lucene的整体倒排结构如下所示:
三、压缩技巧
对于TermIndex,FST其实已经是一种压缩技巧了,它使得Term Index足够小,以至于可以直接放入内存。
对于TermDictionary,有了Term Index之后,可以把公共前缀去掉,从而使一个磁盘块能够存储更多Term,这样磁盘一次随机读(Random Access)能够将更多的Term加载内存,从而减少了磁盘寻道时间,且提高了磁盘利用率。
对于Posting List,Elasticsearch也提供了数据压缩的方法。也是本节要重点介绍的,因为Elasticsearch中存储了海量的数据,所以每个Posting List都可能很大。
举个极端例子,如果Elasticsearch需要对性别这个Field进行索引,会出现什么情况呢,每个Posting List将几乎是文档总数的一半。
3.1 Frame of Reference
增量压缩编码,将大数变成小数,按字节存储
首先,Elasticsearch要求Posting List是有序的,这样的一个好处是方便压缩。一下是官网给出的一个例子:
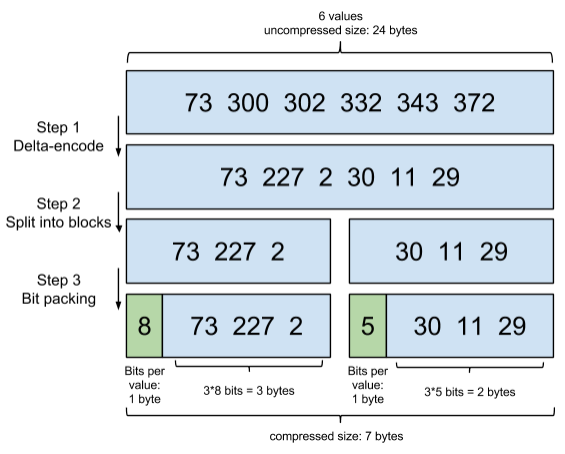
从上图可以看出:
-
原本占24字节的6个数,压缩之后只占7个字节
-
每个数的位置只存储相对前一个数的增量值
-
存储方式按字节分组存储,而不是一个很小的数也用32位去存储。
- 图中,第一组每个数用8bit存,第二组每个数用5bit存
3.2 Roaring Bitmap
Bitmap是大数据中常用的一种数据结构,由于使用bit作为单位来存储数据,因此可以大大节省存储空间。
假设某个Posting List是:[1, 3, 4, 7, 10],占用空间位5 * 32 = 160 bit.
那其对应是一个长度为10(也可能是11,看下标从0还是1开始)的bitmap就是:[1, 0, 1, 1, 0, 0, 1, 0, 0, 1],占空间为 10 bit.
但是Elasticsearch中的文档达到亿级时,一个长度为一亿的bitmap占内存125MB,这个消耗仍然是很奢侈的。
所以Lucene采用Roaring Bitmap这个数据结构。如下图所示:
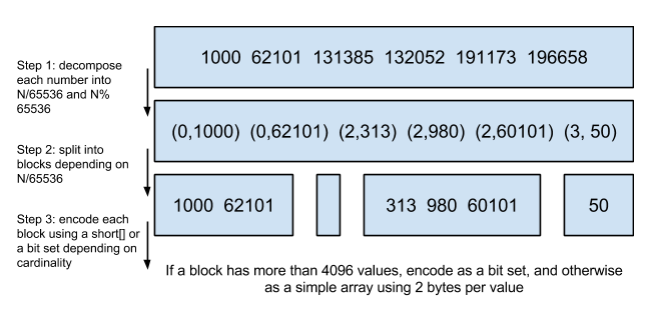
步骤如下:
- 第一步,将原数对65536求商,求余,记录成(商,余数)
- short能表示范围0-65535
- 第二步,通过的商,将余数分组(block)
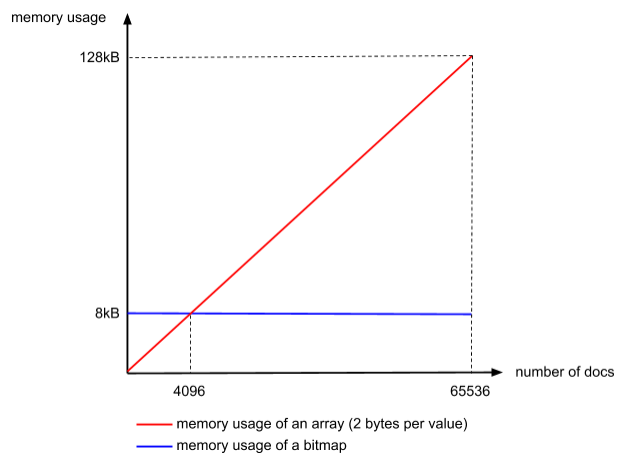
- 第三步,如果一个block中的元素个数大于4096, 则用bitset存储;否则用short数组存储。
为什么是是4096作为阈值呢?
- 仅仅因为在一个块中超过此数量的文档,位图就比数组更节省内存。
四、 联合查询
如果是多个Field上的联合查询,比如:age = 18 and sex = Female 。对于MySQL,如果在两个字段上都建立索引,查询仅能使用其中过滤性最好的一个,然后另个条件在内存中遍历过滤掉。而对于Lucene,直观的想法是分别查询出两个条件的Postint List, 将两个Postint List的合并做“与”操作,即求交集。
但是这个求交集的操作并不容易。因为Posting List可能会很大,好在我们通过上面的压缩方法,已经对Posting List进行了压缩,
对应上面提到的Posting List的两种压缩方法,即存储方式,这里分别介绍相应的合并方式。
4.1 利用SkipList合并
SkipList的结构如下:
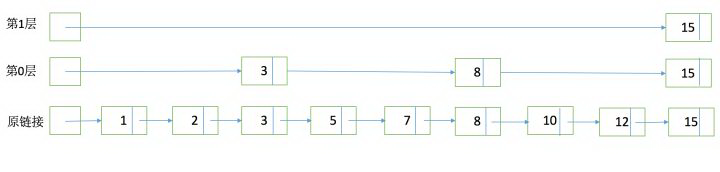
假设查询docid = 12,原先可能需要从头扫描原始链表,现在的过程是,首先访问第一层发现15大于12,然后进入第二层访问3,8,发现15大于12,进入原链表访问10,然后命中12.
引入SkipList之后 ,合并多个Posting List的过程如下:
- 以最短的Posting List 为基准,遍历。
- 在其他Posting List中,利用跳表,快速查找是否含有当前遍历值。
引入SkipList的优点:
- 能够快速跳过不需要比较的值,加快多个Posting List交集的操作
- 由于采用Frame of Reference压缩编码,有一定解压缩成本,跳过不需要比较的值,这些值不需要解压缩,也能节省cpu。
4.2 利用BitSet按位与
这种就没什么好说的了,直接将多个Posting List的Roaring Bitmap做位与操作即可,当然里面用short数组存储的部分还是要遍历的求交集的。
4.3 合并的效率对比
Elasticsearch对原始int数组、bitmap、Roaring Bitmap、FOR(Frame of Reference)四种方式的性能做了较为详细的对比。
结论如下:
- 首先没有一种特定的方法在各个指标上都比其他方法更好
- int数组虽然很快,但是在密集集上内存占用最大,被淘汰
- bitmap由于在稀疏集上的性能和内存使用上都很差,被淘汰
- Roaring Bitmap在各个指标上虽然不是最好的,但也不是最差的,较为均衡
- Frame of Reference因为编码高和跳表的结构,虽然Posting List存储在磁盘,而不是内存中,但是也保持了很快的速度。
五、总结
Elasticsearch的索引思路:
- 通过多级索引的方式减小最前端索引占用的空间,感觉与操作系统防止页表太大,而分为多级页表的思想类似
- 将索引放入内存,尽可能减少磁盘随机读,提高索引查找效率
- 在索引的各个结构Term Index、Term Dictionary、Postintg List上几乎都采用了一定的压缩技巧,一方面能够减少内存占用;另一方面一次磁盘IO也能读入更多的数据,从而侧面减少磁盘随机读。