storm --流式处理框架
storm是个实时的、分布式以及具备高容错的计算系统
- storm 进程常驻内存
- storm 数据不经过磁盘,在内存中处理
Twitter开源的分布式实时大数据处理框架,最早开源于github
storm 架构 -Nimbus -Supervisor -Worker
编程模型: - DAG -Spout -Bolt
数据传输: - ZMQ (Twitter早起的产品)
- ZeroMQ 开源的消息传递框架,并不是一个MessageQueue
-Netty Netty是基于NIO的网络框架,更加高效 (之所以storm0.9版本之后使用netty,是因为ZMQ的license和storm的licemse不兼容)
高可靠性: -异常处理 -消息可靠性保障机制(ACK)
可维护性: -stormUI图形化监控接口
流式处理(同步与异步):客户端提交数据进行计算,并不会等待数据计算结果
逐条处理:例如ETL(数据清洗)
统计分析: 例如计算pv、uv、访问热点以及某些数据的聚合、加和、平均等
--客户端提交数据之后,计算完成结果存储到redis、Hbase、Mysql或者其他的MQ当中
客户端并不关心最终的计算结果是多少
实时请求应答服务(同步) -客户端提交数据请求之后,立刻取得计算结果并返回给客户端
DRPC:
实时请求处理:
storm : 进程 、线程常驻内存运行,数据不仅如此磁盘,数据通过网络进行传递
MapReduce: 为TB、PB级别数据设计 的批处理计算框架
storm与mapreduce的比较:
storm: 流式处理、毫秒级、DAG模型、常驻运行
MapReduce: 批处理、分钟级、map+reduce模型 、反复启停
storm:纯流式处理
- 专门为流式处理设计
- 数据传输模式更为简单,很多地方也更为高效
-并不是不能做批处理,它也可以用来做微批处理,来提高吞吐
Spark Streaming :微批处理
-- 将RDD做的很小来用小的批处理来接近流式处理
--基于内存和DAG处理任务做的很快
storm: 流式处理,毫秒级,已经很稳定,独立系统专门流式计算设计
SparkStreaming: 微批处理、秒级、稳定性改进中、spark核心之上的一种计算模型,能与其他的组件进行很好的结合
storm计算模型:
Topology-DAG 有向无环图的实现
--对于strom实时计算逻辑的封装
--即、由一系列通过数据流相互关联的spout、bolt所组成的拓扑结构
--生命周期:此拓扑只要启动就会一直在集群中运行,直到手动将其kill,否则不会终止
tuple --元祖
---storm中最小的数据组成单元
stream --数据流
--从spout中源源不断传递数据给bolt、以及上一个bolt传递给下一个bolt,所形成的这些数据通道即叫做stream
--stream声明时需给其指定一个ID
spout -数据源
-拓扑中数据流的来源。一般会从指定外部的数据源读取元祖(tuple)发送到拓扑(Topology)中
-一个spout可以发送多个数据流(stream)
--可先通过OutputFieldsDeclear中的declear方法声明定义的不同数据流,发送数据时SpoutOutPutCollector中的emit方法指定数据流的参数将数据发送出去
--spout中最核心的方法是nextyouple,该方法会被storm线程不断对的调用、主动从数据源拉取数据,在通过emit方法将数据生成元祖(tuple)发送给只有的bolt计算
-bolt 数据流处理组件
- 拓扑中数据处理均有bolt完成。对于简单的任务或者数据流转换,单个bolt可以简单的实现;更加复杂的场景往往需要多个bolt分多个步骤处理完成
-一个bolt可以发送多个数据流(Stream)
--可以先通过outputFiledDeclear中的declear方法生命定义的不同数据流,发送数据时通过spoutOutputcollector中的emit方法指定数据流id参数将数据发送出去
--bolt最核心的方法是executor方法,该方法负责接收一个元祖数据、真正实现核心的业务逻辑
stream Grouping --数据流分组
用storm 实现wordcount单词统计
数据发送类
package com.storm.spout; import java.util.List; import java.util.Map; import java.util.Random; import backtype.storm.spout.SpoutOutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichSpout; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Values; import backtype.storm.utils.Utils; public class Wdcspout extends BaseRichSpout{ private SpoutOutputCollector collector; String[] text = { "nihao hello ok", "nice to meet hello", "where are you ok", "where is you home" }; Random r = new Random(); @Override public void nextTuple() { // TODO Auto-generated method stub List line = new Values(text[r.nextInt(3)]); this.collector.emit(line); System.out.println("line==============="+line); Utils.sleep(1000); } @Override public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) { // TODO Auto-generated method stub this.collector = collector; } /** * * */ @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { // TODO Auto-generated method stub declarer.declare(new Fields("line")); } }
数据处理类:
package com.storm.bolt; import java.util.List; import java.util.Map; import backtype.storm.task.OutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichBolt; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Tuple; import backtype.storm.tuple.Values; public class Wcdbolt extends BaseRichBolt{ private OutputCollector collector; @Override public void execute(Tuple input) { // TODO Auto-generated method stub //1、获取数据,并对获取的数据进行切分 String[] words = input.getString(0).split(" "); //2、发送数据 for(String word: words) { List tuple = new Values(word); this.collector.emit(tuple); } } @Override public void prepare(Map conf, TopologyContext context, OutputCollector collector) { // TODO Auto-generated method stub this.collector = collector; } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { // TODO Auto-generated method stub declarer.declare(new Fields("tuple")); } }
第二个处理数据的bolt
package com.storm.bolt; import java.util.HashMap; import java.util.Map; import backtype.storm.task.OutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichBolt; import backtype.storm.tuple.Tuple; public class wcdsbolt extends BaseRichBolt{ private OutputCollector collector; Map<String, Integer> map = new HashMap<>(); @Override public void execute(Tuple input) { // TODO Auto-generated method stub //对接受到的数据进行处理 String word = input.getStringByField("tuple"); int count = 1; //如果单词不存在,则把单词的统计数添加到map中,否则,在原址value的基础之上加1 if(map.containsKey(word)) { count = map.get(word)+1; } map.put(word, count); System.err.println(word+"----------------------------"+count); } @Override public void prepare(Map conf, TopologyContext context, OutputCollector collector) { // TODO Auto-generated method stub this.collector = collector; } @Override public void declareOutputFields(OutputFieldsDeclarer arg0) { // TODO Auto-generated method stub } }
对处理结果提交到本地运行
package com.storm.test; import org.jgrapht.alg.TarjanLowestCommonAncestor.LcaRequestResponse; import com.storm.bolt.Wcdbolt; import com.storm.bolt.wcdsbolt; import com.storm.spout.Wdcspout; import backtype.storm.LocalCluster; import backtype.storm.topology.TopologyBuilder; import backtype.storm.tuple.Fields; import backtype.storm.Config;; public class test1 { public static void main(String[] args) { TopologyBuilder tm = new TopologyBuilder(); //单线程处理 /*tm.setSpout("wcdspout", new Wdcspout()); tm.setBolt("wcdbolt", new Wcdbolt()).shuffleGrouping("wcdspout"); tm.setBolt("wcdsbolt", new wcdsbolt()).shuffleGrouping("wcdbolt");*/ //多线程处理 tm.setSpout("wcdspout", new Wdcspout()); tm.setBolt("wcdbolt", new Wcdbolt(),3).shuffleGrouping("wcdspout"); tm.setBolt("wcdsbolt", new wcdsbolt(),3).fieldsGrouping("wcdbolt", new Fields("tuple")); LocalCluster lm = new LocalCluster(); lm.submitTopology("w", new Config(), tm.createTopology()); } }
注: 当用多线程处理的时候,注意对于分发策略的选择。 否则会发生数据统计异常的错误 。分发策略主要由grouping方法来进行处理的。
storm grouping --数据流分组;(即数据的分发策略)
1、 shuffle grouping
--随机分组,随机派发stream里面的tuple,保证每个bolt task 接受到的tuple数目大致相同 。
--轮询,平均分配。
2、 Fields grouping
--按字段分组,比如,按“user-id”这个字段来进行分组,那么具有同样“user-id”的tuple会被分到相同的bolt里面的一个task,而不同的"user-id"则可能会被分到不同的task
--
3、 All grouping
-- 广播分发,对于每一个tuple,所有的bolt都会收到
4、Global Grouping
--全局分组,把tuple分配给task id 最低的task
5、None grouping
-- 不分组,这个分组的意思是说storm不关心到底是怎样进行分组的,目前这种分组和shufflegrouping 的分组效果是一样的。有一点不同的地方就是storm会把使用none grouping 的这个bolt放到这个bolt的订阅者的同一个线程中区,(未来storm如果可能的话,会进行这样的设计)
6、direct grouping
--指向型分组,这是一种比较特殊的分组方法,用这种分组意味着消息(tuple)的发送者指定由消息接受者的那个task处理这个消息。只要被声明为Direct stream 的消息流可以声明这种分组方法。而且这种消息的tuple必须使用emitDirect方式来发送。消息处理着可以通过TopologyContext来获取处理它的消息的task的id
7、Local or shuffle grouping
--本地或随机分组。如果目标bolt有一个或者多个task与源bolt的task在同一个工作进程中,tuple将会被随机发送给这些同进程中的task,否则,和普通的shuffle grouping 行为一致
8、 customgrouping
--自定义,相当于mapreduce哪里自己去实现一个partition一样。
storm 架构设计
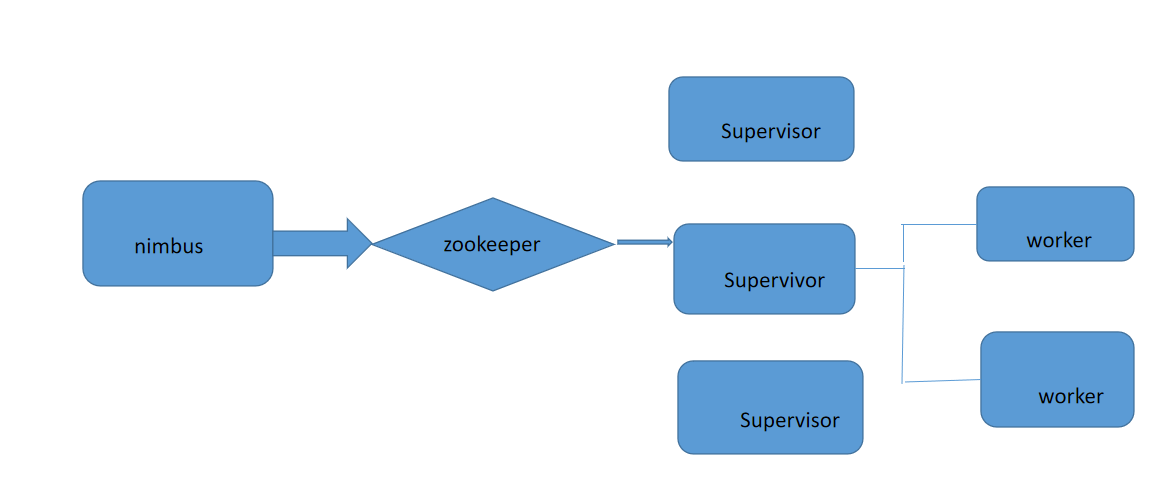
Nimbus: --资源调度 --任务分配 --接受jar包
Supervisor: --接受Nimbus分配的任务
-- 启动、停止自己管理的worker进程(当前supervisor上worker数量由配置文件设定)
--Worker
--运行具体处理运算组件的进程(每个worker对应执行一个Topology的子集)
--worker任务类型,即spout,bolt任务两种
--启动executor(executor即worker JVM进程中的一个java线程,一般默认每个executor负责执行一个task任务 )
--zookeeper:
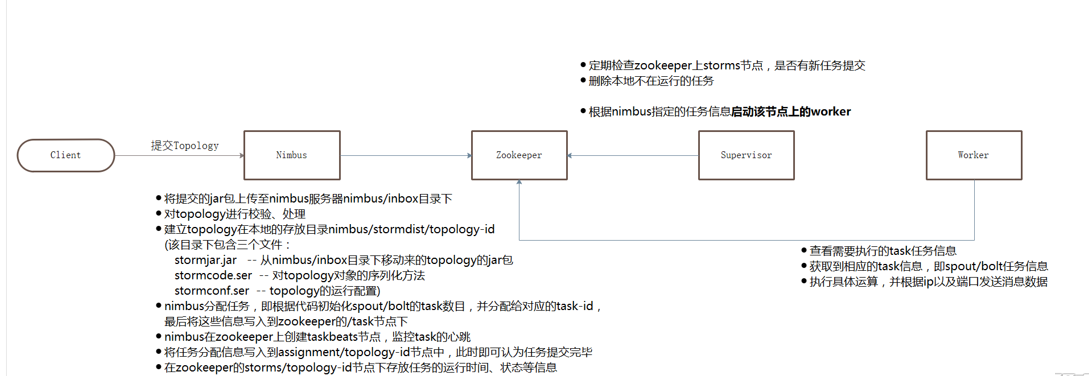
storm 提交任务流程: 1、将提交的jar包上传至nimbus服务器numbus/inbox目录下 2、对topology进行检验处理 3、建立Topology在本地的存放目录nimbusstormdist opology-id(该目录下包含三个文件)
stormjar.jar: --从nimbus/inbox目录下移动来的Topology的jar包
stormcode.ser: --对Topology对象序列化法
stormconf.ser: --topology的运行配置
nimbus任务分配:即根据代码初始化spout/bolt的task数目,并分配给对应的task-id,最后将这些信息写入到zookeeper的/task节点下
nimbus在zookeeper上创建taskbeats节点,监控task的心跳
将任务分配信息写入到assignment/topology-id节点中,此时即可认为任务提交完毕
在zookeeper的/storms/topology-id节点下存放任务运行的时间、状态等信息
定期检查zookeeper上storm节点,是否有新任务提交,删除本地不在运行的任务
根据nimbus指定的任务信息启动该节点上的worker
查看需要执行的task任务信息,获取到相应的task信息,即spout/bolt任务信息,执行具体的运算,并根据IP以及端口发送消息数据
storm的安装:
伪分布式的安装:
1、 上传安装压缩包 2、将安装压缩包解压 3、配置环境变量 4、启动storm相关命令
storm dev-zookeeper >> ./logs/zk.out 2>&1 & (将启动日志重定向到logs目录中,2>&1代表将标准的错误输出重定向到标准的正确输出中)
在伪分布式环境上运行wordcount步骤:
1、将wordcount代码打成jar包
2、将打好的jar包上传到linux服务器
3、运行上传的jar 包
运行jar包的命令: storm jar tq.jar com.storm.wordcount.Main (最后面写的是jar包文件在eclipse中所在的jar位置和类名称)--这种方式是本地模式来运行的
如果不打算用本地模式来运行那么就添加一个参数来运行
storm jar tq.jar com.storm.wordcount.Main ec
ack: 线程保障机制,监控线程的运行情况,并将监控的结果发送给spout,如果ack监控到线程运行出现了问题,那么就让spout将数据重新发送一遍
结束运行任务的命令: storm kill 任务名称 -w 时间长短
注:关闭storm所有已经启动的任务命令: killall java
storm 完全分布式的搭建: 1、准备环境 jdk python 2.6.6
2、 部署zookeeper : 3、上传安装包并解压 4、在storm中创建logs目录 5、修改配置文件 -conf/storm.yaml
在配置文件中指定对应的zookeeper: storm.zookeeper.servers: - "node2" - "node3" - "node4"
nimbus.host: "node1" (指定nimbus所在的节点)
storm.local.dir: "/tmp/storm"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
然后将配置好的文件分发到其他的节点 scp -r ./storm node2:/opt/
完全分布式的启动:node1上面启动主节点
./bin/storm nimbus >> ./logs/nimbus.out 2>&1 &
./bin/storm ui >> ./logs/ui.out 2>&1 &
node2、node3上面启动从节点
./bin/storm supervisor >> ./logs/supervisor.out 2>&1 &
storm的并发机制:
worker: --进程
一个Topology拓扑会包含一个或者多个worker(每个worker只能从属于一个特定的Topology)
这些Worker进程会并行跑在集群中不同的服务器上,即一个Topology拓扑其实是由并行运行在storm集群中多台服务器上的进程所组成
Executor --线程
--executor是由Worker进程中生成的一个线程
--每个worker进程中会运行一个或多个拓扑当中的executor线程
--一个executor线程中可以执行一个或多个task任务(默认每个executor只执行一个task任务),但是这些task任务都是对应着同一个组件
Task
--实际执行数据处理的最小单元
--每个task即为一个spout或者一个bolt
task数量在整个Topology生命周期中保持不变,executor数量可以变化或者手动调整
(默认情况下,task数量和executor是相同的,即每个executor线程中默认运行一个task任务)
设置worker 进程数: -Config.setNumWorkers(Int workers)
设置Executor线程数
- TopologyBuilder.setspout()
--TopologyBuilder.setbolt()
设置task数量:
--componentConfigurationDeclare.setNumTasks(Number val)
rebalance --再平衡
--即,动态调整Topology拓扑的worker进程数、以及executor的线程数
支持两种调整方式: 1、通过storm ui 2、通过storm cli
通过storm CLI 动态调整:
用shell命令调整并行度:
./bin/storm rebalance wc -w 30 -n 2 -e 组件名称=(调整的并行度)
storm的通信机制:
worker进程之间的通信:
-ZMQ -zeroMQ开源的消息传递框架,并不是一个MessageQueue
-Netty -netty是基于NIO的网络框架,更加高效。
Worker内部的数据通信:
-Disruptor --实现队列的功能 --可以理解为一种事件监听或者消息处理机制,即在队列中一边由生产者放入消息数据,另一边由消费者并行去除消息数据处理
storm的容错机制: 1、集群节点宕机 -Nimbus服务器 单点故障
--非Nimbus服务器 故障时,该节点上所有的task任务都会超时,Nimbus会将这些task任务重新分配到其他服务器上运行
2、 进程挂掉
--worker
挂掉时,Supervisor会重启这个进程,如果启动过程中任然一直失败,并且无法向nimbus发送心跳,Nimbus会将该worker重新分配到其他服务器上
--Supervisor
无状态(所有的状态信息都放在zookeeper中进行管理)
快速失败 (每当遇到异常情况,都会自动毁灭)
--Nimbus
无状态(所有的状态信息都存放在zookeeper中来管理)
快速失败(每当遇到任何的异常情况都会自动毁灭)
3、消息的完整性
acker --消息完整性的实现机制
-- storm 的拓扑当中 特殊的一些任务
-- 负责跟踪每个spout发出的tuple的DAG(有向无环图)
注:容错机制无法保证数据只被处理一次 ,但可以保证所有的数据都被处理
storm -DRPC
客户端通过向DRPC服务器发送待执行函数的名臣以及该函数的参数来获取处理结果。实现该函数的拓扑使用一个DRPspout从DRPC服务器中接受一个函数的调用流。DRPC会为每一个函数调用都标记一个唯一的id,随后拓扑会执行函数来计算结果,并在拓扑的最后使用一个名为returnResult的bolt连接到DRPC服务器,根据函数调用的id来将函数调用的结果返回。
DRPC (Distributed RPC) --分布式远程调用
DRPC 是通过一个DRPC服务端(DRPC server)来实现分布式RPC功能
DRPC server 负责接收RPC请求,并将该请求发送到Strom中运行的Topology,等待接收Topology发送的处理结果,并将该结果返回给发送请求的客户端
DPRC设计目的:
为了充分利用Storm的计算能力实现高密度的并行实时计算
DRPC在集群中运行,首先需要配置配置文件,添加DRPC运行的节点,其次需要将启动DRPC服务器。
./bin/storm drpc >> ./logs/drpc.out 2>&1 &
flume整合kafka: 安装flume 和 kafka ,启动zookeeper+kafka+flume
flume的安装:
1、加压安装包 2、修改配置文件名称: mv flume-env.sh.propertise flume-env.sh 3、在配置文件中配置java_home路径
启动三个节点kafka:bin/kafka-server-start.sh config/server.properties
启动flume:bin/flume-ng agent -n a1 -c conf -f conf/fk.conf -Dflume.root.logger=DEBUG,console
添加flume启动的配置文件:
a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = avro a1.sources.r1.bind = node01 a1.sources.r1.port = 41414 # Describe the sink a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.topic = testflume a1.sinks.k1.brokerList = node1:9092,node2:9092,node3:9092 a1.sinks.k1.requiredAcks = 1 a1.sinks.k1.batchSize = 20 a1.sinks.k1.channel = c1 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000000 a1.channels.c1.transactionCapacity = 10000 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
Flume+Kafka+Storm架构设计:
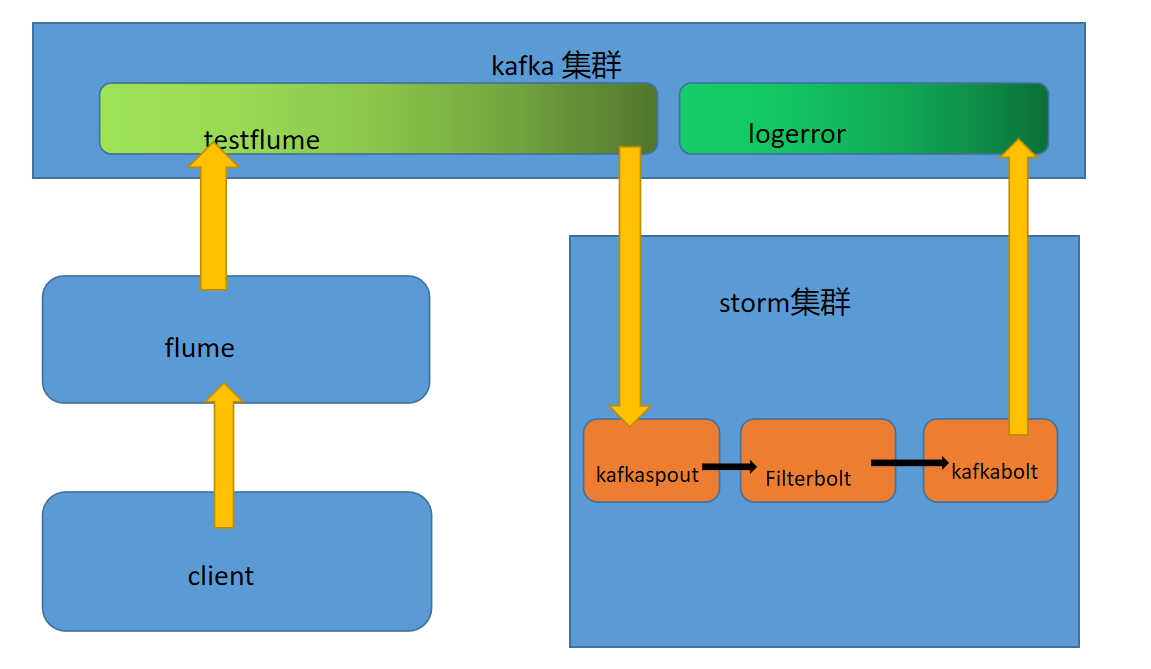
package com.storm.flume; /** * Licensed to the Apache Software Foundation (ASF) under one * or more contributor license agreements. See the NOTICE file * distributed with this work for additional information * regarding copyright ownership. The ASF licenses this file * to you under the Apache License, Version 2.0 (the * "License"); you may not use this file except in compliance * with the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ import java.util.ArrayList; import java.util.Arrays; import java.util.List; import java.util.Properties; import backtype.storm.Config; import backtype.storm.LocalCluster; import backtype.storm.spout.SchemeAsMultiScheme; import backtype.storm.topology.BasicOutputCollector; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.TopologyBuilder; import backtype.storm.topology.base.BaseBasicBolt; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Tuple; import backtype.storm.tuple.Values; import storm.kafka.KafkaSpout; import storm.kafka.SpoutConfig; import storm.kafka.StringScheme; import storm.kafka.ZkHosts; import storm.kafka.bolt.KafkaBolt; import storm.kafka.bolt.mapper.FieldNameBasedTupleToKafkaMapper; import storm.kafka.bolt.selector.DefaultTopicSelector; /** * This topology demonstrates Storm's stream groupings and multilang * capabilities. */ public class LogFilterTopology { public static class FilterBolt extends BaseBasicBolt { @Override public void execute(Tuple tuple, BasicOutputCollector collector) { String line = tuple.getString(0); System.err.println("Accept: " + line); // 包含ERROR的行留下 if (line.contains("SUCCESS")) { System.err.println("Filter: " + line); collector.emit(new Values(line)); } } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { // 定义message提供给后面FieldNameBasedTupleToKafkaMapper使用 declarer.declare(new Fields("message")); } } public static void main(String[] args) throws Exception { TopologyBuilder builder = new TopologyBuilder(); // https://github.com/apache/storm/tree/master/external/storm-kafka // config kafka spout,话题 String topic = "testflume"; ZkHosts zkHosts = new ZkHosts("node1:2181,node2:2181,node3:2181"); // /MyKafka,偏移量offset的根目录,记录队列取到了哪里 SpoutConfig spoutConfig = new SpoutConfig(zkHosts, topic, "/MyKafka", "MyTrack");// 对应一个应用 List<String> zkServers = new ArrayList<String>(); System.out.println(zkHosts.brokerZkStr); for (String host : zkHosts.brokerZkStr.split(",")) { zkServers.add(host.split(":")[0]); } spoutConfig.zkServers = zkServers; spoutConfig.zkPort = 2181; // 是否从头开始消费 spoutConfig.forceFromStart = true; spoutConfig.socketTimeoutMs = 60 * 1000; // StringScheme将字节流转解码成某种编码的字符串 spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme()); KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig); // set kafka spout builder.setSpout("kafka_spout", kafkaSpout, 3); // set bolt builder.setBolt("filter", new FilterBolt(), 8).shuffleGrouping("kafka_spout"); // 数据写出 // set kafka bolt // withTopicSelector使用缺省的选择器指定写入的topic: LogError // withTupleToKafkaMapper tuple==>kafka的key和message KafkaBolt kafka_bolt = new KafkaBolt().withTopicSelector(new DefaultTopicSelector("LogError")) .withTupleToKafkaMapper(new FieldNameBasedTupleToKafkaMapper()); builder.setBolt("kafka_bolt", kafka_bolt, 2).shuffleGrouping("filter"); Config conf = new Config(); // set producer properties. Properties props = new Properties(); props.put("metadata.broker.list", "node1:9092,node2:9092,node3:9092"); /** * Kafka生产者ACK机制 0 : 生产者不等待Kafka broker完成确认,继续发送下一条数据 1 : * 生产者等待消息在leader接收成功确认之后,继续发送下一条数据 -1 : * 生产者等待消息在follower副本接收到数据确认之后,继续发送下一条数据 */ props.put("request.required.acks", "1"); props.put("serializer.class", "kafka.serializer.StringEncoder"); conf.put("kafka.broker.properties", props); conf.put(Config.STORM_ZOOKEEPER_SERVERS, Arrays.asList(new String[] { "node1", "node2", "node3" })); // 本地方式运行 LocalCluster localCluster = new LocalCluster(); localCluster.submitTopology("mytopology", conf, builder.createTopology()); } }
storm --事务
强顺序流(强有序)
--引入事物(transaction)的概念,每个transaction关联一个transaction id。
--transaction id从1开始,每个tuple会按照顺序加1
--在处理tuple时,将处理成功的tuple结果以及transaction同时写入数据库中进行存储
--两种情况
1、当前transaction id 与数据库中的transaction id 不一致
2、两个transaction id 相同
缺点:一次只能处理一个tuple,无法实现分布式计算
将Topology拆分成两个阶段:
1、Processing phase : 允许并行处理多个batch
2、commit phase : 保证batch的强有序,一次只能处理一个batch
Design details
Manages state -状态管理
--storm 通过 Zookeeper 存储所有的transaction相关信息 (包含了: 当前transaction id 以及 batch的元数据信息 )
Coordinates the transaction --事物协调
--storm会管理决定transaction应该处理什么阶段(processing,committing)
Fault detection --故障检测
--storm 内部通过ACKER 机制保障消息被正常处理(用户不需要手动区维护)
First class batch processing API : storm 提供的batch bolt接口
三种事物:
1、普通事物 2、 partition transaction --分区事物 3、 opaque transaction --不透明分区事物
事务性拓扑(transaction topoligies) 保证消息(tuple)被且仅被处理一次