页面解析过程
浏览器在接收到服务端的响应时,拿出其中的代码,将其渲染成网页,经历了以下步骤:

DOM
第一步:DOM解析
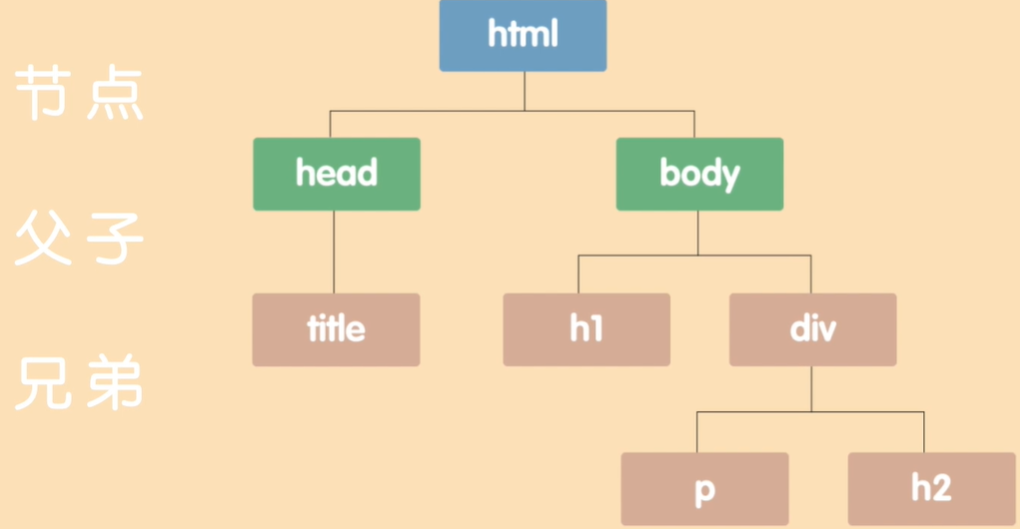
CSSDOM
第二步:将CSS填入DOM树中,得到一个带有样式的DOM树
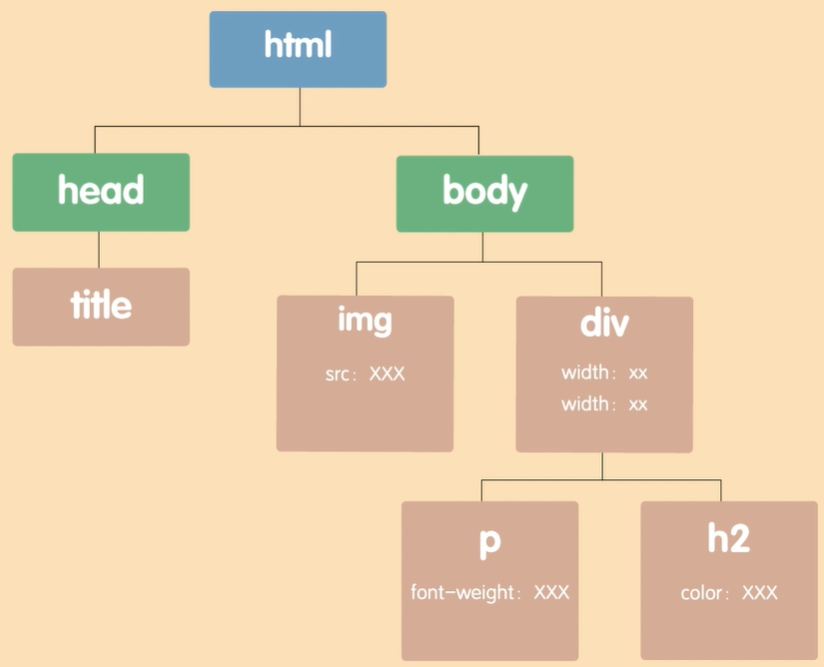
读取文档流
读取文档流,根据DOM树,从左到右的顺序读取,形成文档流

如果节点里有子节点,则直接套进去
接着,加载样式属性,作为节点的附加说明
页面元素摆放
然后将节点(盒子)在网页上一一摆放(注意:此时还没有进行渲染,元素还是不可见的)
如果节点是块级元素,它会独占一行
如果节点是行内元素,它会挨着摆放,知道一行中撑不下了,就会换到下一行继续开始
这种规则下形成的文档流,也叫做 标准文档流
页面渲染
将摆放好位置的元素,添加其他的样式属性,形成最后的网页效果
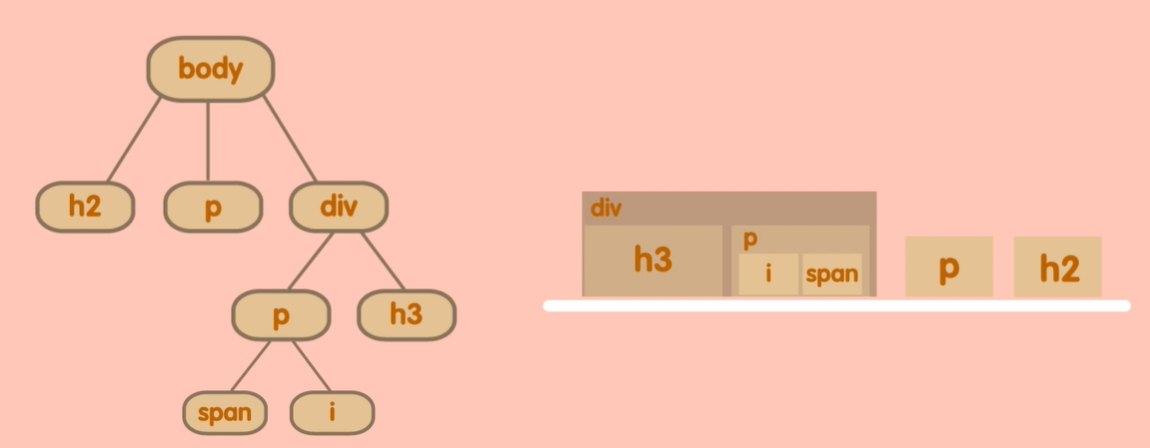
标准文档流
文档流中:内联元素默认从左到右流,遇到阻碍或者宽度不够自动换行,继续按照从左到右的方式布局。块级元素单独占据一行,并按照从上到下的方式布局。
基本特点
空白折叠现象
多个空格会被合并成一个空格显示到浏览器页面中。img标签换行写。会发现每张图片之间有间隙,如果在一行内写img标签,就解决了这个问题,但是我们不会这样去写我们的html结构。这种现象称为空白折叠现象。
高矮不齐,底边对齐
文字还有图片大小不一,都会让我们页面的元素出现高矮不齐的现象,但是在浏览器查看我们的页面总会发现底边对齐
自动换行,一行写不满,换行写
如果在一行内写文字,文字过多,那么浏览器会自动换行去显示我们的文字。
块级元素与行内元素
行内元素和块级元素的区别:(非常重要)
行内元素:
- 与其他行内元素并排;
- 不能设置宽、高。默认的宽度,就是文字的宽度。
块级元素:
- 霸占一行,不能与其他任何元素并列;
- 能接受宽、高。如果不设置宽度,那么宽度将默认变为父亲的100%。
块级元素和行内元素的分类:
在以前的HTML知识中,我们已经将标签分过类,当时分为了:文本级、容器级。
从HTML的角度来讲,标签分为:
- 文本级标签:p、span、a、b、i、u、em。
- 容器级标签:div、h系列、li、dt、dd。
PS:为甚么说p是文本级标签呢?因为p里面只能放文字&图片&表单元素,p里面不能放h和ul,p里面也不能放p。
现在,从CSS的角度讲,CSS的分类和上面的很像,就p不一样:
行内元素:除了p之外,所有的文本级标签,都是行内元素。p是个文本级,但是是个块级元素。
块级元素:所有的容器级标签都是块级元素,还有p标签。
相互转换
通过display属性将块级元素和行内元素进行相互转换。display即“显示模式”
标准流里面的限制非常多,导致很多页面效果无法实现。如果我们现在就要并排、并且就要设置宽高,那该怎么办呢?办法是:移民!脱离标准流!