安装Anaconda,Anaconda是一个集成环境(基于机器学习和数据分析的开发环境)
jupyter notebook
基于浏览器的一种可视化开发工具
安装Anaconda并配置环境变量后在工作目录进入终端中,输入jupyter notebook即可启动服务,并在浏览器中打开。浏览器中的根目录即工作目录。
new python3 后可得一个以.ipynb为后缀名文件,是ipython notebook的缩写。

配置Jupyter Noteb默认启动目录
- 在开始菜单找到 jupyter notebook 快捷键,右键->更多->打开文件所在位置,找打快捷方式在文件中的位置,右键->属性->目标,去掉最后的 %USERPROFILE%
- 在cmd下使用
jupyter notebook --generate-config命令找到配置文件的位置 - 打开配置文件,搜索
The directory to字段。 - 修改默认打开路径。把字段下一行前面的注释符号
#去掉,然后在引号中加入想要保存的路径。

- 在任意目录重启Jupyter Notebook即可进入工作目录。
cell模式
cell分为四种模式,常用模式:code模式(python代码),markdown模式(笔记)。
常用快捷键:
- esc 失去当前cell的焦点,cell输入框会从绿色变为蓝色。Jupyter笔记本有两种不同的键盘输入模式。 编辑模式允许将代码或文本输入到一个单元格中,并通过一个绿色的单元格来表示 。命令模式将键盘与笔记本级命令绑定在一起,并通过一个灰色的单元格边界显示,该边框为蓝色的左边框。
- 添加cell
- a 当前在cell上方添加一个新cell
- b 当前在cell上方添加一个新cell
- 删除cell
x - 执行cell
- 执行cell后并新建cell:`shift+enter`
- 只执行cell: `ctrl+enter`
- 切换cell模式
- m 切换为Markdown模式
- y 切换为code模式
- 打开帮助文档:
shift+tab,若查看模块中对象的帮助文档要先运行import语句,加载至缓存中才能查看。 - 代码补全:tab
查看更多快捷键或更改快捷键,菜单栏help——>Keyboard Shortcuts
cell的code模式写代码不分先后,但执行分先后。同一个python3文件的全部cell用同一个缓存,执行代码即加载进缓存中。

Morkdown模式实例


爬虫
- 通过编写程序模拟浏览器上网,然后去互联网上爬取数据的过程。
- 模拟:浏览器就是一个天然的爬虫工具。可以使用requests模块实现。
- 爬取:只抓取想要的数据,可以是整个页面也可以是局部页面,需要数据解析。
爬虫的分类
- 通用爬虫:
- 抓取互联网中的一整张页面的数据
- 聚焦爬虫:
- 抓取页面中的局部数据
- 增量式爬虫:
- 用来监测网站数据更新的情况,以便爬取到网站最新更新出来的数据。
反爬机制:网站门户通过制定的策略或机制阻止第三方爬取网站中的重要数据。
反反爬策略:破解网站门户的反派机制,从而获取想要的数据。
爬虫是否合法
爬虫作为一种计算机技术就决定了它的中立性,因此爬虫本身在法律上并不被禁制,但利用爬虫技术获取数据的行为是具有违法甚至是犯罪的风险的。 爬虫是用来批量获得网页上的公开信息(前端显示的数据),既然本身就是公开信息,爬虫只不过是批量下载而已,所以是合法的。但也有不合法的情况,如:配合爬虫,利用黑客技术攻击网站后台,窃取后台数据(比如用户数据等)等等。
爬虫非法风险主要体现在以下2个方面:
- 爬虫干扰了被访问网站的正常运营;
- 爬虫抓取了受到法律保护的特定类型的数据或信息
爬虫开发者应注意以下几点:
- 严格遵守网站设置的robots协议;
- 在规避反爬虫策略同时,需要优化自己的代码,避免干扰被访问网站的正常运行;
- 在使用、传播抓取到的信息时,应审查所抓取的内容。如发现属于用户的个人信息、隐私或者他人的商业秘密的,应及时停止并删除。
robots协议:直接在域名后加上/robots.txt即可查看。如:查看淘宝的robots协议,访问:www.taobao.com/robots,txt。该协议并没有使用硬性的策略阻止反爬,只是告诉爬虫开发者可以爬取网站中的页面。 协议中:
- User-agent:允许的请求载体的标识。
- Allow:允许访问的页面
- Disallow 不允许爬取的页面
就像拿水果刀切水果不犯法而那水果刀伤害他人犯法一样,爬虫也是具有两面性的。
requests模块
python中封装好的一个基于网络请求的模块。用来模拟浏览器发请求。 安装:pip install requests
requests模块的编码流程
- 指定url
- 发起请求
- 获取相应数据
- 持久化储存
# 爬取搜狗首页的页面源码数据
import requests
# 1. 指定url
url = "https://www.sogou.com"
# 2.发送请求 get
response = requests.get(url=url) # get返回值是Response对象
# 获取响应数据,响应数据在Response对象里
page_text = response.text # text返回字符串型式的响应数据
# 4.持久化储存
with open("sogou.html","w",encoding='utf-8') as fp:
fp.write(page_text)
项目:实现一个简易的网页采集器
要求:程序基于搜狗录入任意的关键字然后获取关键字对应的相关的整个页面。
# 1.指定url,需要让url携带的参数动态化
url = "https://www.sogou.com/web"
# 实现参数动态化,不推荐参数的拼接,参数如果太多就相当麻烦。
# requests模块实现了更为简便的方法
ky = input("enter a key")
params = {
'query':ky
}
# 将需要的请求参数对应的字典作用到get方法的params参数中,params参数接受一个字典
response = requests.get(url=url,params=params)
page_text = response.text
with open(f"{ky}.html","w",encoding='utf-8') as fp:
fp.write(page_text)
上述代码执行后:
- 出现了乱码
- 数据量级不对
# 解决乱码
url = "https://www.sogou.com/web"
ky = input("enter a key")
params = {
'query':ky
}
response = requests.get(url=url,params=params)
# print(response.encoding) 会打印原来response的编码格式
response.encoding = 'utf-8' # 修改响应数据的编码格式
page_text = response.text
with open(f"{ky}.html","w",encoding='utf-8') as fp:
fp.write(page_text)
上述代码执行后:
收到了错误页面(搜狗的反爬机制)
UA检测
- 绝大多数网站都有UA检查反爬机制
- 门户网站通过检测请求载体的身份标识判定该请求是否为爬虫发出的请求
反反爬策略:UA伪装 请求头增加User-Agent
打开浏览器请求搜狗页面,右键点击检查进入Network,点击Headers找到浏览器的User-Agent
注意:任意浏览器的身份标识都可以。
# 反反爬策略:请求头增加User-Agent
url = "https://www.sogou.com/web"
ky = input("enter a key")
params = {
'query':ky
}
# 请求头中增加User-Agent ,注意请求头的数据格式是键值对,且都是字符串。
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"
}
response = requests.get(url=url,params=params,headers=headers)
response.encoding = 'utf-8'
page_text = response.text
with open(f"{ky}.html","w",encoding='utf-8') as fp:
fp.write(page_text)
注意:get的参数headers是一个字典,且键值都是字符串形式
项目 爬取豆瓣电影中详情数据
豆瓣电影分类排行榜 - 爱情片:url:https://movie.douban.com/typerank?type_name=%E7%88%B1%E6%83%85&type=13&interval_id=100:90&action= ,type_name对应的值无法读其含义原因是由于编码问题
要求:电影的详情数据:电影名、时间、演员、评分等;其他数据不要。
分析:
- 当滚动条滑动到页面底部时,当前页面发生了局部刷新(浏览器发生了ajax请求)
- 想要获取动态加载的数据要分析ajax请求。
- 通过抓包工具,右键打开检查进入network
- 找到XHR一栏,网页发生的ajax请求全在这一类中
- 滑动滚动条,捕获ajax请求
- 点击捕获的请求,点击Response菜单栏
- 可以看到Response是一段Json数据,解析Json数据,可以看到数据中有电影的信息,并注意到数据中有title与电影的名称组合成键值对。
- 此Response就是想要爬取的数据
- 点击Hearders菜单栏,找到ajax的Request URL:
https://movie.douban.com/j/chart/top_list?type=13&interval_id=100%3A90&action=&start=20&limit=20
动态加载的数据
- 通过另一个单独的请求请求到的数据(ajax请求)
- 可能无法通过页面对应的url拿到当前页面的所有数据
# 试爬取分析出的ajax请求的url
url = "https://movie.douban.com/j/chart/top_list?type=13&interval_id=100%3A90&action=&start=20&limit=20"
# jupyter的缓存功能,上方代码已存在headers并已运行,内存中已有headers的数据
respones = requests.get(url=url,headers=headers)
# respones.text 返回字符串的json对象,还需要解析
page_text = respones.json() # json() 返回序列化好的实例对象,此处是列表中嵌套字典的数据
i = 1
for dic in page_text:
print(str(i) +":"+ dic['title'])
i+=1
分析:
- ajax请求的url域名后有参数,参数个数可在Headers中的Query String Parameters一栏查看。对应的的键是参数的键,值是参数的值
- Query String Parameters中有start与limit键
- 上方代码打印结果后20个电影名,对应limit;第一个电影名恰好与页面上的第20个电影对应
- 更改ajas参数,爬取数据
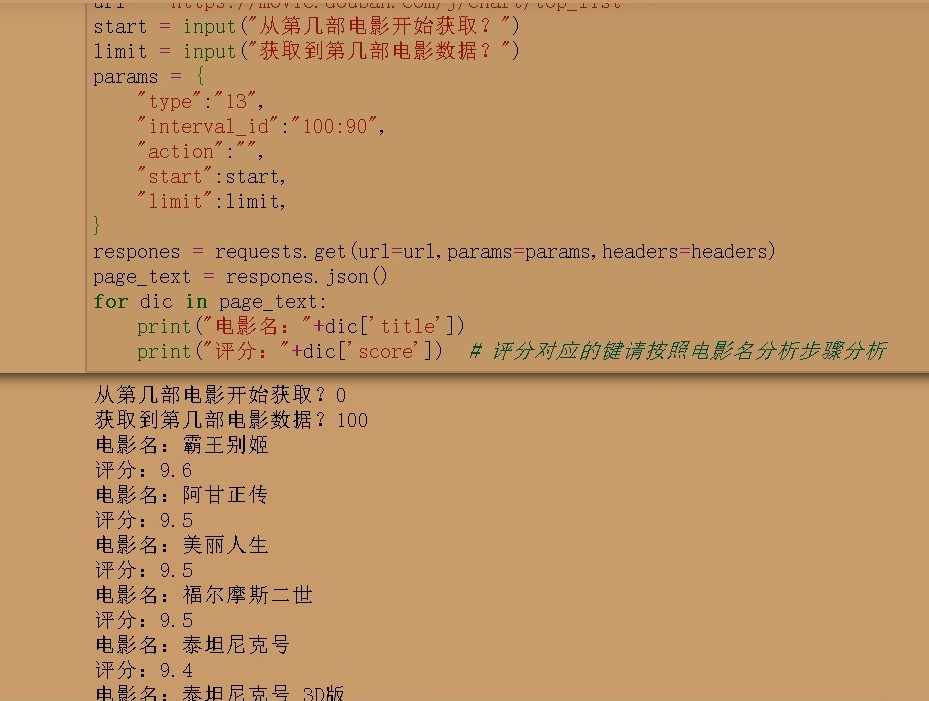
# https://movie.douban.com/j/chart/top_list?type=13&interval_id=100%3A90&action=&start=20&limit=20
# url中的interval_id=100%3A90其实是interval_id=100:90,是编码问题,可解码查看
# 将参数动态化
url = "https://movie.douban.com/j/chart/top_list"
start = input("从第几部电影开始获取?")
limit = input("获取到第几部电影数据?")
params = {
"type":"13",
"interval_id":"100:90",
"action":"",
"start":start,
"limit":limit,
}
respones = requests.get(url=url,params=params,headers=headers)
page_text = respones.json()
for dic in page_text:
print("电影名:"+dic['title'])
print("评分:"+dic['score']) # 评分对应的键请按照电影名分析步骤分析