盘点3种Python网络爬虫过程中的中文乱码的处理方法
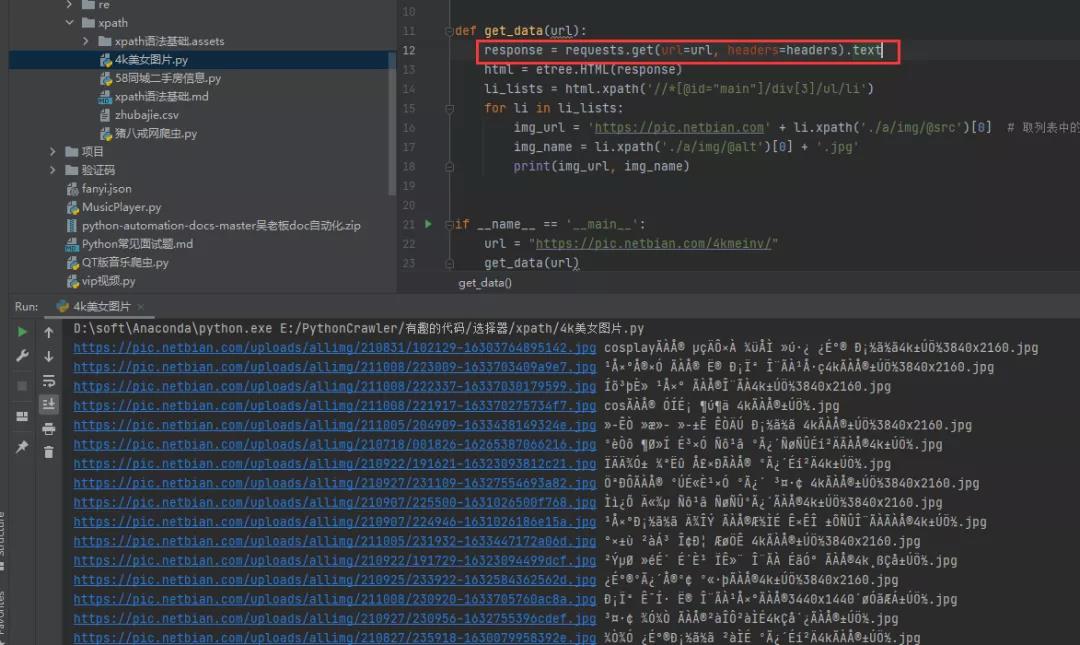
1)方法一:将requests.get().text改为requests.get().content 我们可以看到通过text()方法获取到的源码,之后进行打印输出的话,确实是会存在乱码的,如下图所示。
如果觉得上面的方法很难记住,或者你可以尝试直接指定gbk编码也可以进行处理,如下图所示:
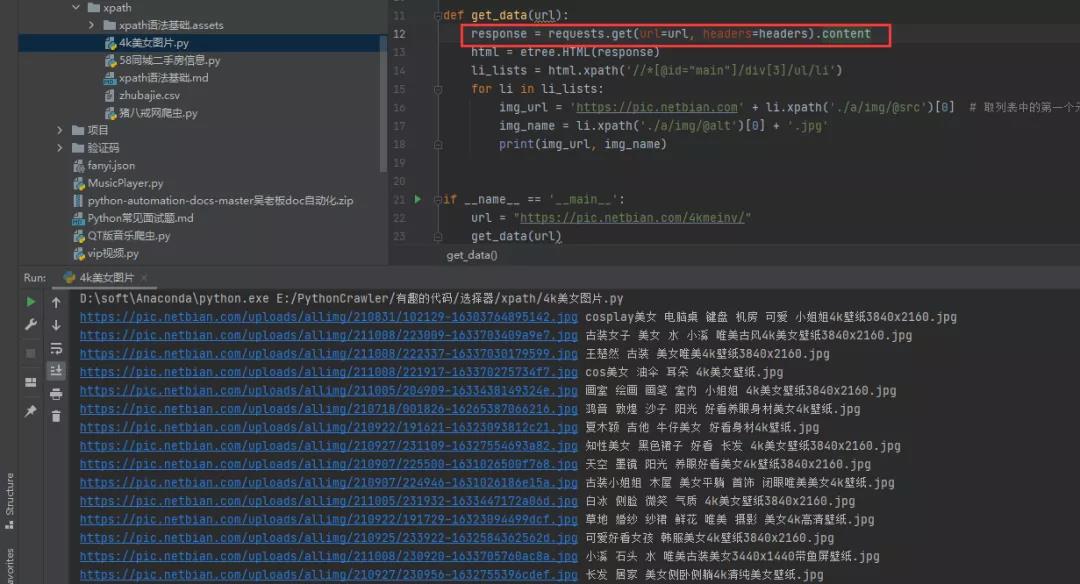
此时可以考虑将请求变为.content,得到的内容就是正常的了。
2)方法二:手动指定网页编码
# 手动设定响应数据的编码格式response.encoding = response.apparent_encoding
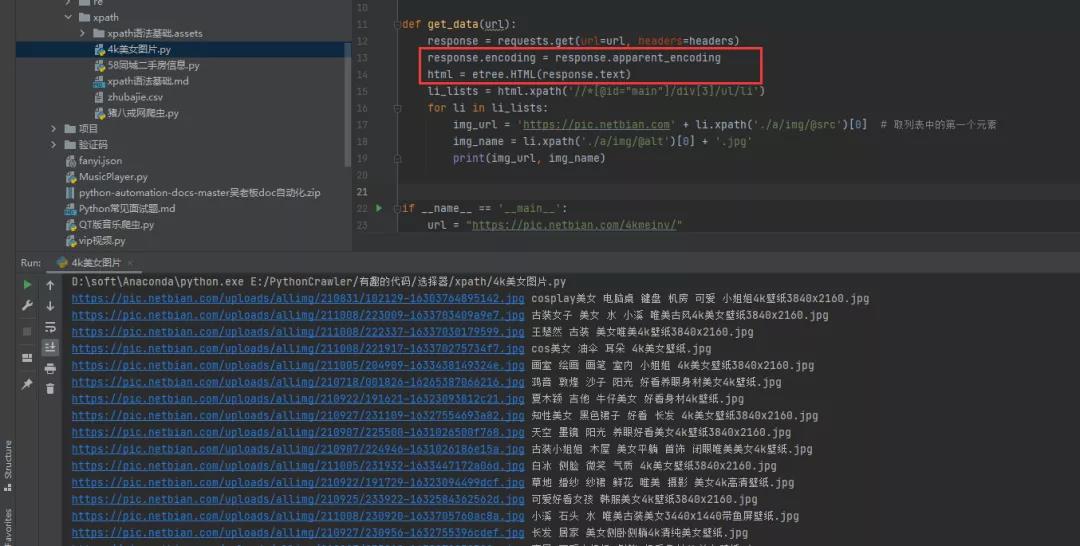
这个方法稍微复杂一些,但是比较好理解,对于初学者来说,还是比较好接受的。
如果觉得上面的方法很难记住,或者你可以尝试直接指定gbk编码也可以进行处理,如下图所示:
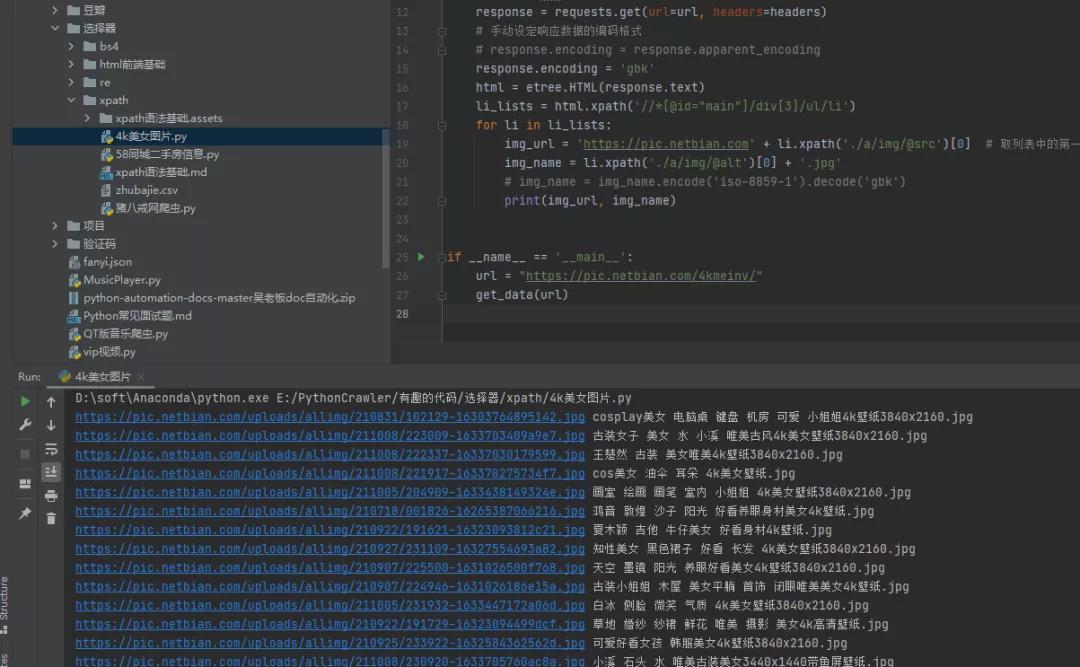
上面介绍的两种方法都是针对网页进行整体编码,效果显著,接下来的第三种方法就是针对中文局部乱码部分使用通用编码方法进行处理。
3)方法三:使用通用的编码方法img_name.encode('iso-8859-1').decode('gbk')使用通用的编码方法,对中文出现乱码的地方进行编码设定即可。还是当前的这个例子,针对img_name进行编码设定,指定编码并进行解码,如下图所示。
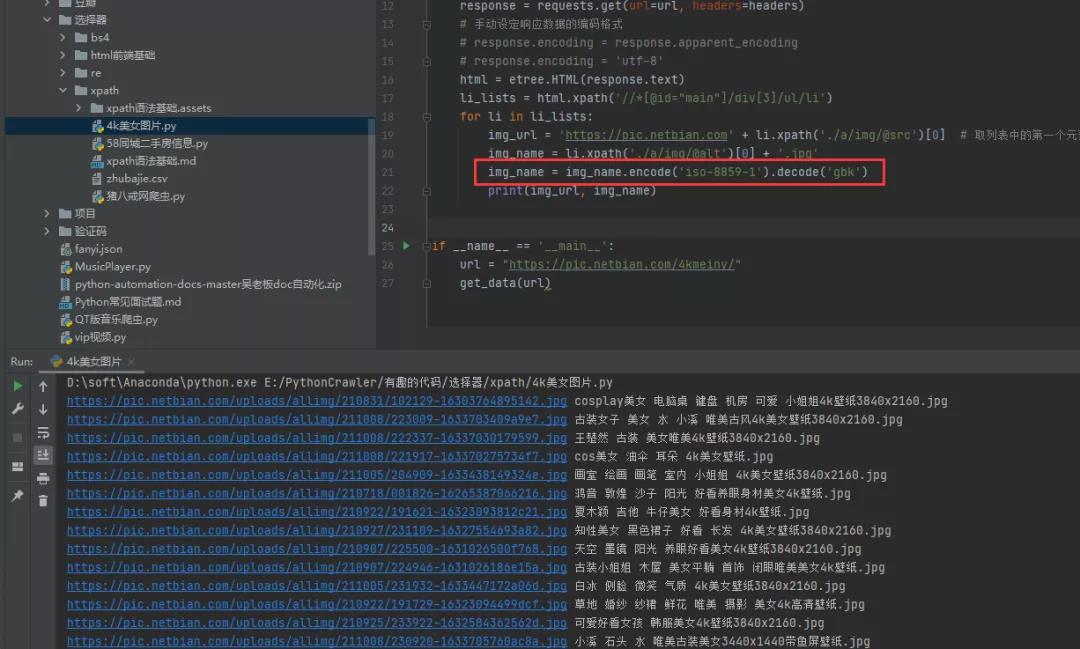
如此一来,中文乱码的问题就迎刃而解了。