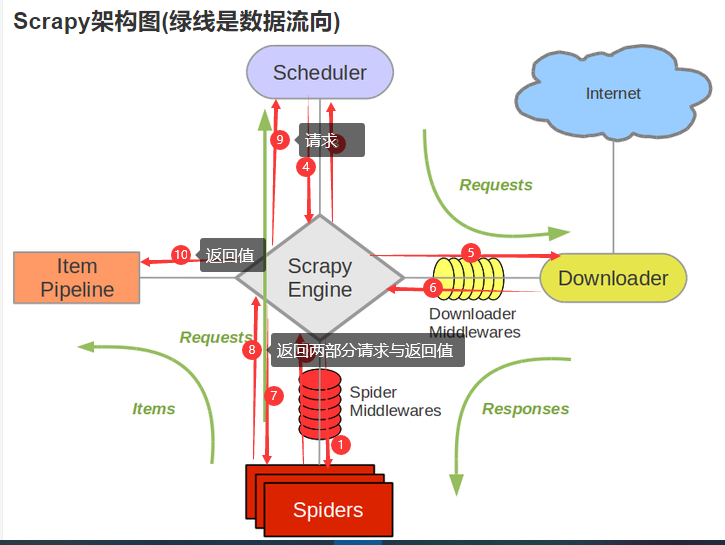
- 1 引擎:Hi!Spider, 你要处理哪一个网站?
- 2 Spider:老大要我处理xxxx.com。
- 3 引擎:你把第一个需要处理的URL给我吧。
- 4 Spider:给你,第一个URL是xxxxxxx.com。
- 5 引擎:Hi!调度器,我这有request请求你帮我排序入队一下。
- 6 调度器:好的,正在处理你等一下。
- 7 引擎:Hi!调度器,把你处理好的request请求给我。
- 8 调度器:给你,这是我处理好的request
- 9 引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求
- 10 下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)
- 11 引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)
- 12 Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
- 13 引擎:Hi !管道 我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
- 14 管道调度器:好的,现在就做!