支付对账系统是支付清结算体系中具体基础性意义的一个环节,是确保支付平台与各类第三方支付渠道数据一致性的关键系统,是商户资金结算、资金划拨、资金报表等逻辑准确运行的重要前提。通过阅读本次内容来了解,支付对账系统如何在数据不断增长的情况下演进。
对于不同公司会根据业务复杂程度对接多个支付渠道,各个渠道的账单接口下载形式,账单数据格式等会存在不同的差异,为了实现账单数据的统一格式化,我们需要将各渠道原始的账单文件进行统一标准化转化,同时也需要设计一张相对通用的渠道账单数据表来存储不同渠道账单格式化后的数据。如下图:
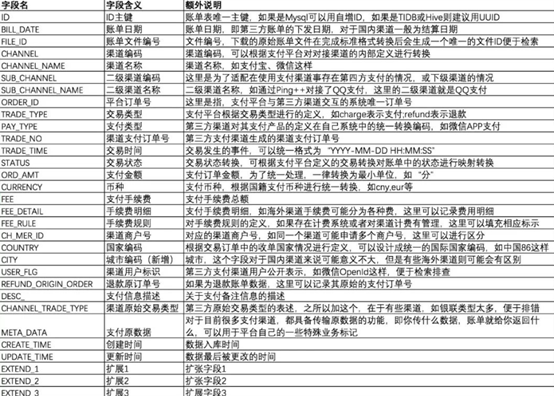
在进行账单数据存储时为了提高效率,需要将标准账单文件格式设计得与表结构一致,这样在完成数据转换后可以直接将文件load/copy到数据库中,这样速度会快很多;而考虑数据规模会增长得超级大,可以存储在hive中。
此外,对于账单的下载逻辑同样需要考虑防重逻辑的,即同一个渠道账号的同一天的账单数据不能重复下载和入库,所以除了存储具体的账单数据外,也需要设计一张账单下载记录表,用于存储那个渠道账号哪一天的下载情况,并在账单下载任务启动起根据该表进行防重复下载逻辑判断。为了统一集中管理这些账单文件、也为了数据安全需要采用统一文件存储服务,或者自己搭建一个文件夹共享服务。账单下载记录中也需要存储原始账单文件及标准账单文件的下载位置,方便日后用于数据问题排查,需要检索原始文件时,方便查找及数据重新加载。
对于对账,相当于两个数据集的交集,以平台订单号作为关联条件,将账单表中的数据与支付平台订单表的数据进行full join得到一个集合全量,得到的集合会是一个交集、两个补集。处于交集部分的数据集说明根据订单号是可以对应上的,还需对订单金额对比,如果一致则无差错,对平的数据集按照结算数据要求取账单数据+平台订单数据业务字段全集,直接生成对账明细表,不平则计入对账差错数据表。
从系统拆分的角度看,一般不会将对账处理与在线支付订单放一个库中,可能影响实时支付系统的稳定性,另外这些表数据是不断增长的,随着数据的积累会导致查询变慢,通过清洗到两个中间表,通过这两张表进行full join操作,得到的结果集,数据比较大,使用分布式关系型数据库合理。
对于对账差错一般分为三类,长款、短款、金额错误。根据具体的差错类型及原因,结合整个支付系统的流程来保证系统间数据的一致性。
对于对账系统的演变主要需要从考虑数据的增长、任务资源的合理配置以及系统监控这几个方向去考虑。如果数据量持续增长到传统方式已无法处理,可以采用Spark Streming+Hive+Tidb等组合技术方案进行改进。
此外对账系统是一个以定时任务为主的系统,对于定时任务处理框架的选择可以采用分布式任务框架(推荐elasticjob/saturn)+自定义任务逻辑的方式综合处理(如有些任务存在先后顺序,如果框架本身不提供这类处理功能,则需要通过业务规则限制)。
而从系统监控角度,由于任务系统不同于实时交易流程,具有执行时间长、数据操作范围广泛的特点,除了进行正常的进程级别的监控外,对于各个任务的执行情况,也需要进行比较细致的监控,这部分可以通过监控打点等方式综合解决;而对于业务异常日志的监控则可以通过Sentry等日志监控工具进行监控。