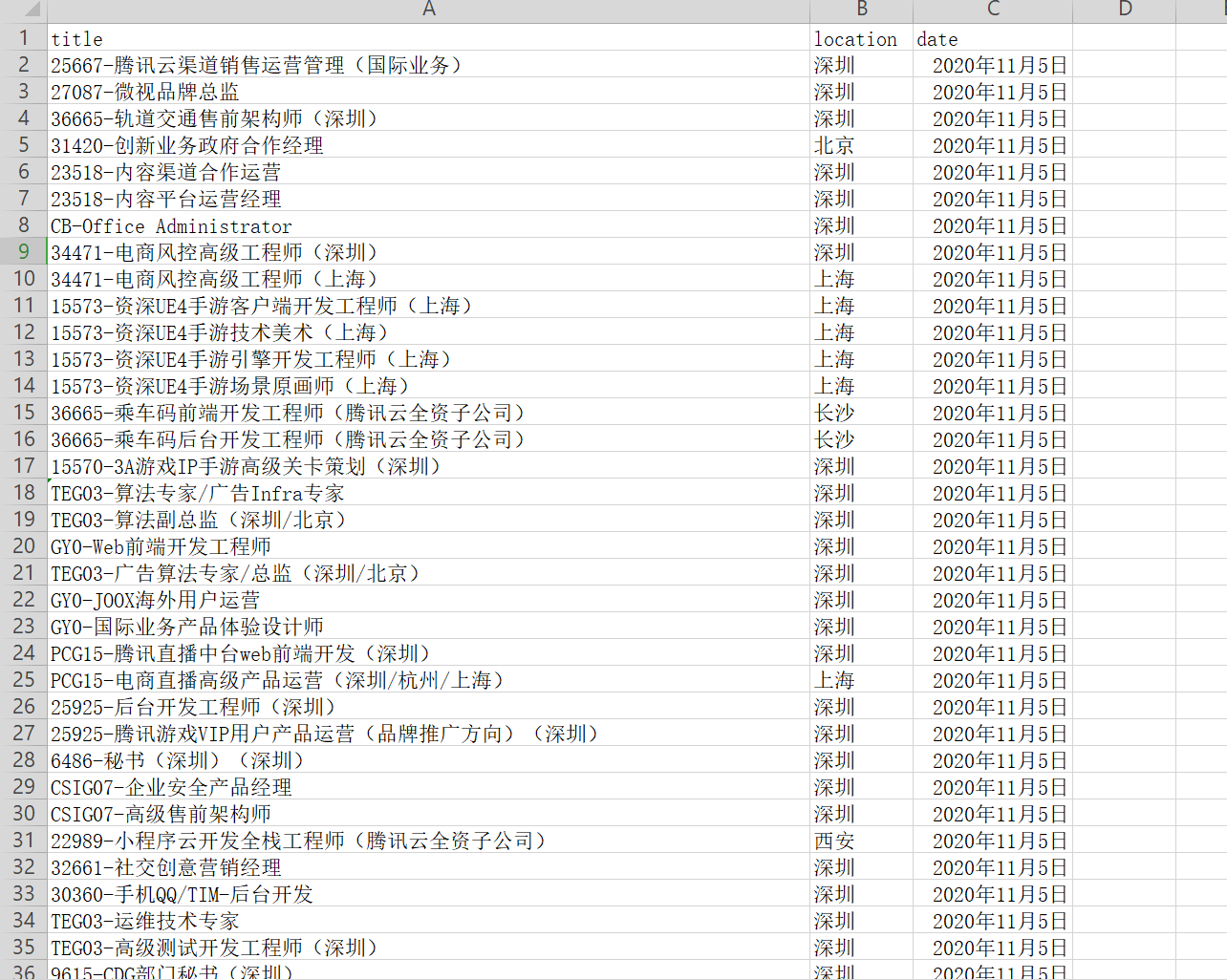
【项目目标】
通过爬取腾讯招聘网站的招聘信息(https://careers.tencent.com/search.html)练习Scrapy框架的使用
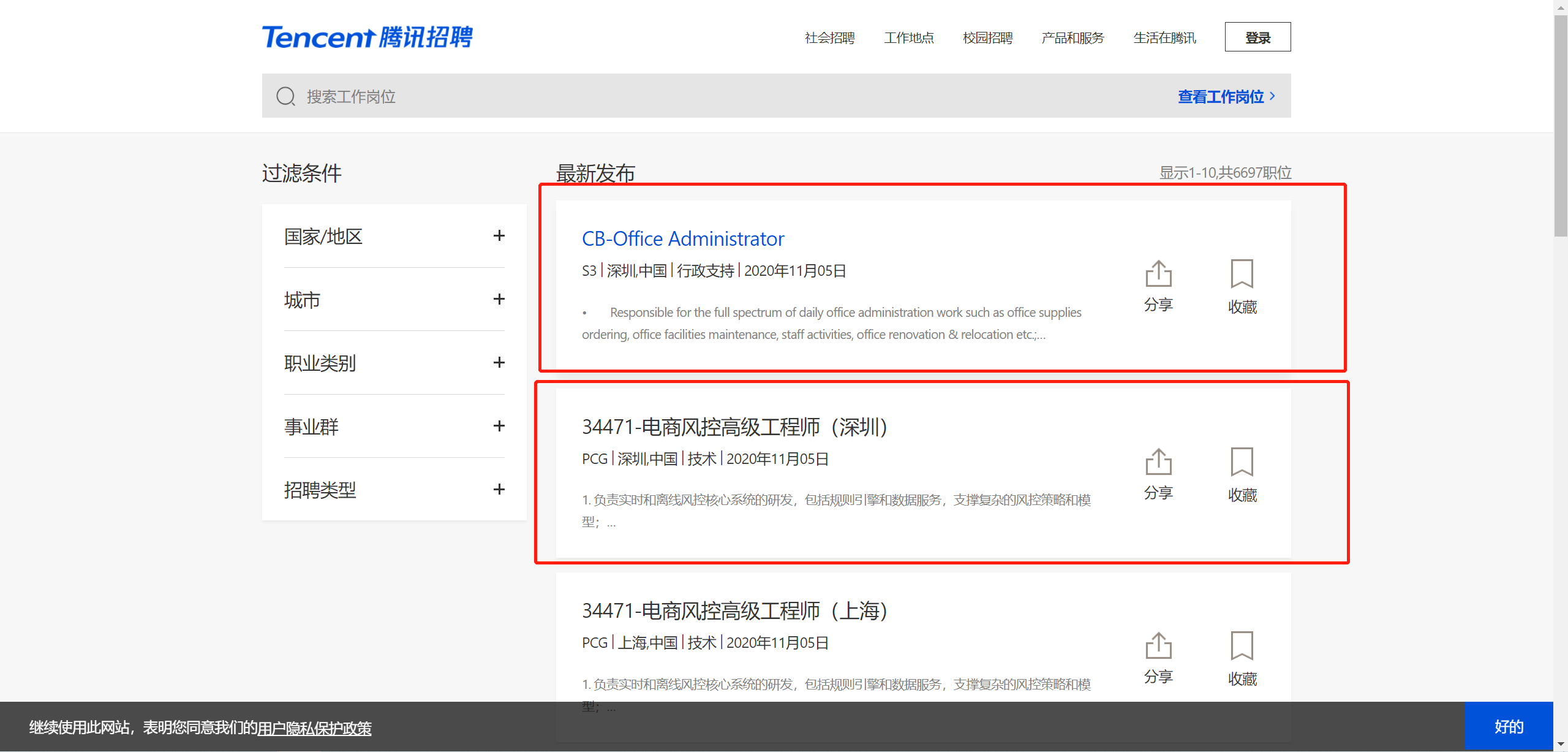
【项目过程】
1、通过抓包确认要抓取的内容是否在当前url地址中,测试发现内容不在当前url中并且数据格式为json字符串
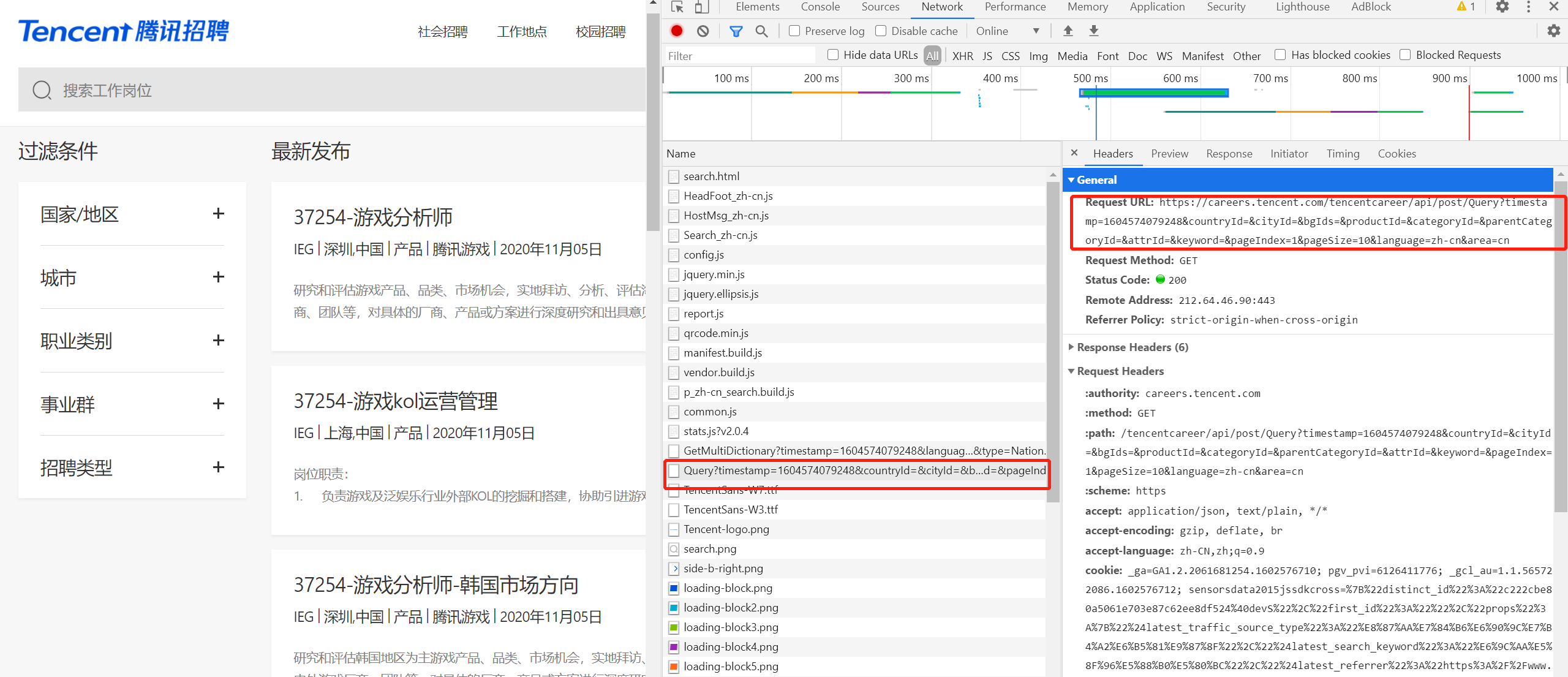
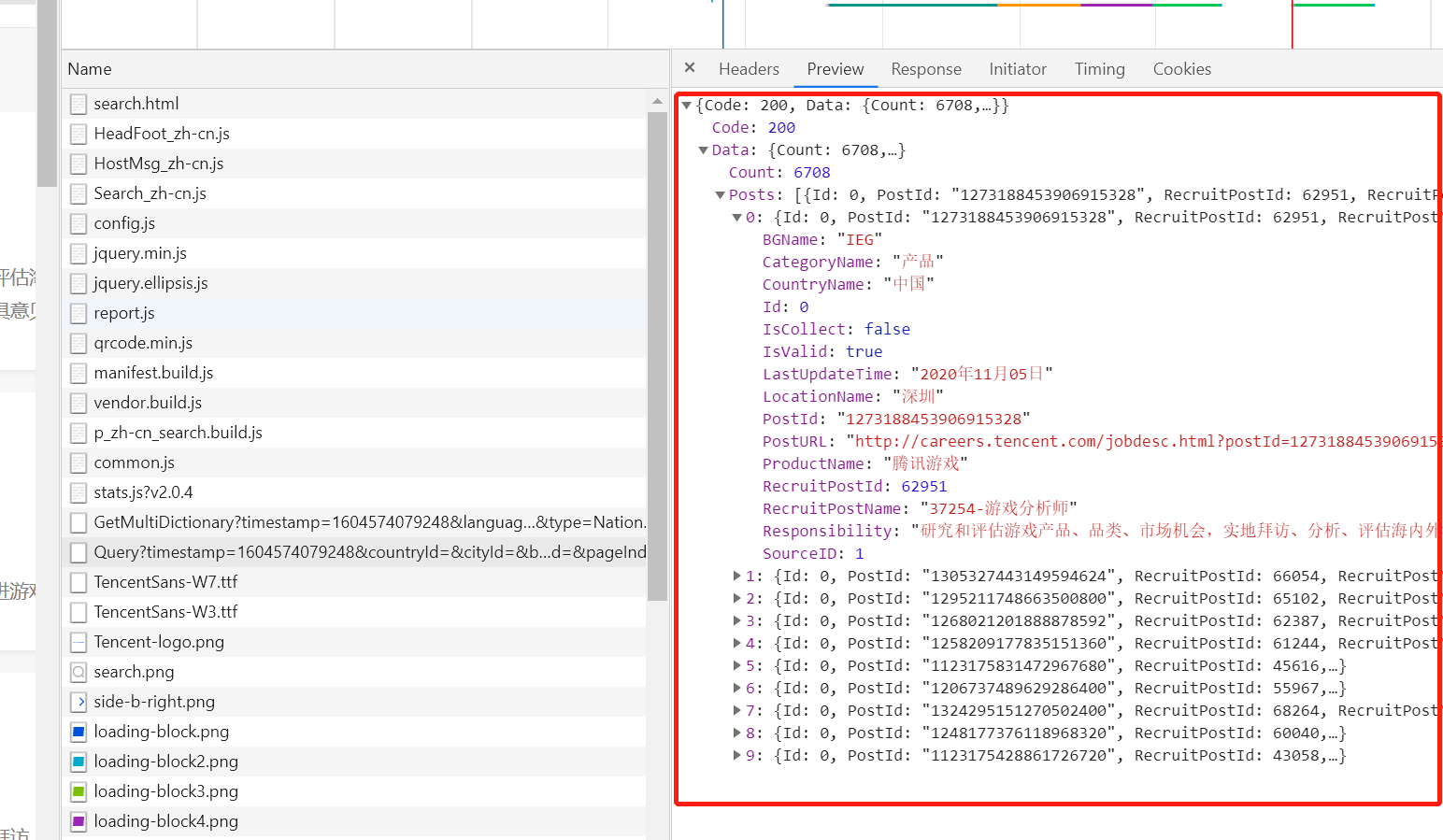
2、请求url地址过长,考虑去除某些部分,经测试得到
https://careers.tencent.com/tencentcareer/api/post/Query?keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn
3、寻找url地址,pageIndex=页码,可构造爬虫循环的URL列表
4、书写爬虫代码
- scrapy startproject tencent tencent.com
- cd tencent.com
- scrapy genspider hr tencent.com
5、保存为CSV文件
1 import scrapy
2 import json
3
4
5 class HrSpider(scrapy.Spider):
6 name = 'hr'
7 allowed_domains = ['tencent.com']
8 start_urls = ['https://careers.tencent.com/tencentcareer/api/post/Query?keyword=&pageIndex=1&pageSize=10&language'
9 '=zh-cn&area=cn']
10 url = 'https://careers.tencent.com/tencentcareer/api/post/Query?keyword=&pageIndex={'
11 '}&pageSize=10&language=zh-cn&area=cn '
12 pageIndex = 1
13
14 def parse(self, response):
15 json_str = json.loads(response.body)
16 for content in json_str["Data"]["Posts"]:
17 content_dic = {"title": content["RecruitPostName"], "location": content["LocationName"],
18 "date": content["LastUpdateTime"]}
19 print(content_dict)20
yield content_dic
21
23 if self.pageIndex < 10:
24 self.pageIndex += 1
25 next_url = self.url.format(self.pageIndex)
26 yield scrapy.Request(url=next_url, callback=self.parse)
运行爬虫
- scrapy crawl hr
保存命令 - scrapy crawl hr -o tencent.csv