最近在学习多线程,题目源自 MoreWindows先生的 《秒杀多线程第一篇》(http://blog.csdn.net/morewindows/article/details/7392749)
题目摘录:
第五题(Google面试题)
有四个线程1、2、3、4。线程1的功能就是输出1,线程2的功能就是输出2,以此类推.........现在有四个文件ABCD。初始都为空。现要让四个文件呈如下格式:
A:1 2 3 4 1 2....
B:2 3 4 1 2 3....
C:3 4 1 2 3 4....
D:4 1 2 3 4 1....
请设计程序。
代码实现如下:
1 #include <iostream> 2 #include <string> 3 #include <thread> 4 #include "Semaphore.h" 5 6 constexpr unsigned MAX_COUNT = 10; 7 constexpr unsigned MAX_THREAD = 4; 8 9 unsigned getNext(unsigned current, bool order) { 10 if (order) { 11 unsigned next = current + 1; 12 return next % MAX_THREAD; // //正序 13 } else { 14 unsigned next = current - 1; 15 return next % MAX_THREAD; //反序 16 } 17 } 18 19 class File 20 { 21 public: 22 File(const std::string& name = "0") 23 :m_name(name) 24 ,m_buffer(MAX_COUNT, '0') 25 ,m_pos(0){ 26 27 } 28 29 void write(char c) { 30 m_buffer.at(m_pos++) = c; 31 } 32 33 std::string getName() const { 34 return m_name; 35 } 36 std::string getData() const { 37 return m_buffer; 38 } 39 private: 40 std::string m_name; 41 std::string m_buffer; 42 size_t m_pos; 43 }; 44 45 Semaphore t1(1), t2(1), t3(1), t4(1); 46 Semaphore* semaphoreArray[MAX_THREAD] = { &t1, &t2, &t3, &t4 }; 47 File files[MAX_THREAD] = { File("A"), File("B"), File("C"), File("D") }; 48 unsigned currentFile[MAX_THREAD] = { 0, 1, 2, 3 }; //每个线程当前应该写入的文件id 49 50 void write(unsigned threadId) { 51 const char c = '1' + threadId; 52 auto& fid = currentFile[threadId]; 53 //auto fid = threadId; 54 auto nextThreadId = getNext(threadId, true); //正序 55 unsigned count = 0; 56 while (MAX_COUNT != count) { 57 semaphoreArray[threadId]->wait(); 58 //写文件 59 files[fid].write(c); 60 //将文件传递给下一个线程。 61 semaphoreArray[nextThreadId]->signal(); 62 //更新要写入的文件id 63 fid = getNext(fid, false); //逆序 64 ++count; 65 } 66 } 67 68 69 int main() { 70 std::cout << "hello" << std::endl; 71 72 //create thread 73 std::thread threads[MAX_THREAD]; 74 for (unsigned i = 0; i != MAX_THREAD; ++i) { 75 threads[i] = std::thread(write, i); 76 } 77 78 //join 79 for (auto& thread : threads) { 80 thread.join(); 81 } 82 83 //output 84 for (const auto& file: files) { 85 std::cout << file.getName() << ": " << file.getData() << std::endl; 86 } 87 88 std::cout << "bye" << std::endl; 89 return 0; 90 }
其中Semaphore.h的代码见:http://www.cnblogs.com/waterfall/p/7966116.html
运行结果截图:
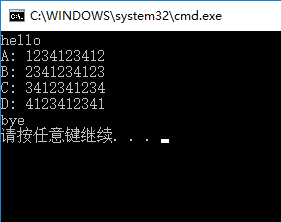
代码解析:
简单分析:
本问题也可以认为是生产者与消费者。只不过线程既生产又消费。按文件的角度,比如A文件的内容为1 2 3 4 1…… 相当于每个线程生产完之后交个下一个线程。
所以对于每一个线程,设置好其初始文件,调用自身信号量的wait()进行生产,生产完毕则调用下一个线程的signal()。将完成的文件交给下一个线程,形成流水作业。
啰里八嗦:
首先,本代码用File类模拟文件写入,方便打印调试。void File::write(char c) 方法即在文件结尾追加字符c。
根据题目要求可以看出,当文件(比如文件A)被线程1写入结束后,需要被下一个线程即线程2写入。因此会有A: 1 2 3 4 1... B,C,D文件同理,只不过初始写入线程不同。
在代码中利用 :
unsigned currentFile[MAX_THREAD] = { 0, 1, 2, 3 }; //每个线程当前应该写入的文件id
指定每个线程初始写入哪个文件。如果不想配置也可以用threadId作为线程初始写入的文件id(write函数中被注释掉的那一句),他们刚好相等。
代码中用信号量表示线程可执行写入的次数。write函数会在写入完一个文件后,自动计算下一个要写入的文件。顺序为A,D,C,B,A....,逆序。
Semaphore t1(1), t2(1), t3(1), t4(1); //用于设置信号量 Semaphore* semaphoreArray[MAX_THREAD] = { &t1, &t2, &t3, &t4 }; //放入数组只是为了方便调用
如果只是给线程1的信号量设为1,其他都设为0。线程的运行状况可以看作:
step1: 线程1 信号量1 A->D 线程2 信号量0 B 阻塞 线程3 信号量0 C 阻塞 线程4 信号量0 D 阻塞
step2: 线程1 信号量0 D 阻塞 线程2 信号量1 B->A 线程3 信号量0 C 阻塞 线程4 信号量0 D 阻塞
step3: 线程1 信号量0 D 阻塞 线程2 信号量0 A 阻塞 线程3 信号量1 C->B 线程4 信号量0 D 阻塞
step4: 线程1 信号量0 D 阻塞 线程2 信号量0 A 阻塞 线程3 信号量0 B 阻塞 线程4 信号量1 D->C
第一轮运行结束:线程1在文件A中写入了1,线程2在文件B中写入了2,线程3在文件C中写入了3,线程4在文件D中写入了4。
之后第二轮开始:线程1在文件D中写入了1,线程2在文件A中写入了2……
以此类推,相当于同一时间只有1个线程在工作。每当线程工作时,将字符写入自己当前要写入的文件中,并计算出下一个要写入的文件。
这种情况显然是不会出现冲突的。
如果将线程1的初始信号量置为2:
step1: 线程1 信号量2 A->D 线程2 信号量0 B 阻塞 线程3 信号量0 C 阻塞 线程4 信号量0 D 阻塞
step2: 线程1 信号量1 D->C 线程1 信号量1 B->A 线程3 信号量0 C 阻塞 线程4 信号量0 D 阻塞
可以看出文件D中被写入了字符1,出现错误。原因在于文件D当前期待被线程4写入,在4写入之前处于未就绪状态。此时被任何其他线程写入都是错误的。
如果假设线程1和线程4的初始信号量各为1,其他为0。且假设线程4先运行
step1.1: 线程1 信号量1 A 就绪 线程2 信号量0 B 阻塞 线程3 信号量0 C 阻塞 线程4 信号量1 D->C
step1.2: 线程1 信号量2 A->D 线程2 信号量0 B 阻塞 线程3 信号量0 C 阻塞 线程4 信号量0 C 阻塞
step2.1: 线程1 信号量1 D->C 线程1 信号量1 B->A 线程3 信号量0 C 阻塞 线程4 信号量0 D 阻塞
文件D先被线程4写入字符4,之后再被线程1写入字符1便符合题目要求了。(D的序列应该为:4 1 2 3 4……)
也就是说,线程1的信号量的增加,是基于前一个线程已经完成文件写入了。此时文件处于就绪状态,可以被下一个线程使用,也即把文件传递给下一个线程。
所以最终的代码中,将每一个线程的初始信号量设置为1。可满足题目要求。哪怕任何线程在执行中出现阻塞(可用sleep模拟),也不影响其他线程运行。
假设在线程1中执行一个长时间的sleep。可能的运行情况如下
step0: 线程1 信号量1 A 就绪 线程2 信号量1 B 就绪 线程3 信号量1 C 就绪 线程4 信号量1 D 就绪
一段时间后……
step1:线程1 信号量4 A 就绪 线程2 信号量0 A 阻塞 线程3 信号量0 A 阻塞 线程4 信号量0 A 阻塞
所有的线程都在等待将数据写入文件A中。但只有线程1先在文件A中写入字符1,之后释放信号,B才能继续写入。之后是C,D。依然没有冲突。文件A也满足1,2,3,4的字符顺序。
其他:
目前网上搜到的很多代码,同一时间只允许一个线程进行文件的写入,或者是通过计数,一轮结束后才进行下一轮写入。本代码真正实现了线程间的并行。只有无文件可写时才会进行等待。
谢谢。