Linux命令三剑客
1.awk
基础知识
AWK是一种处理文本文件的语言,是一个强大的文本分析工具。
之所以叫AWK是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
语法
awk [选项参数] 'script' var=value file(s)
或
awk [选项参数] -f scriptfile var=value file(s)
选项参数说明:
-F fs or --field-separator fs
指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。
-v var=value or --asign var=value
赋值一个用户定义变量。
-f scripfile or --file scriptfile
从脚本文件中读取awk命令。
-mf nnn and -mr nnn
对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。
-W compact or --compat, -W traditional or --traditional
在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。
-W copyleft or --copyleft, -W copyright or --copyright
打印简短的版权信息。
-W help or --help, -W usage or --usage
打印全部awk选项和每个选项的简短说明。
-W lint or --lint
打印不能向传统unix平台移植的结构的警告。
-W lint-old or --lint-old
打印关于不能向传统unix平台移植的结构的警告。
-W posix
打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符**和**=不能代替^和^=;fflush无效。
-W re-interval or --re-inerval
允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。
-W source program-text or --source program-text
使用program-text作为源代码,可与-f命令混用。
-W version or --version
打印bug报告信息的版本。
-
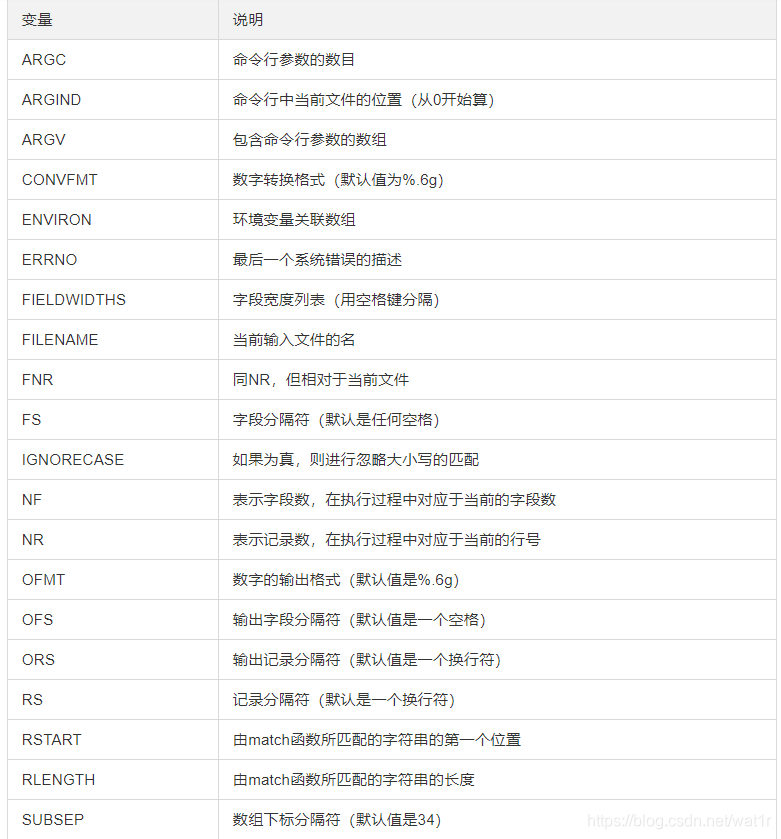
变量与说明
-
查询
interventions.txt文件的制定的第三个字段的类型
awk -F'|' ' {if($3 ~"Drug|Other|Biological|Genetic") {print $2,$3 }}' interventions.txt OPS=" " | less -
查询
interventions.txt的各个统计
awk -F'|' 'NR!=1{a[$3]++;} END {for (i in a) print i ", " a[i];}' interventions.txt -
对文件的按
.分隔后取第一个,去重后输出,源数据举例dw.XXXXXdm.XXXXX
awk -F'.' '{print $1}' hive_tables.txt | awk '!x[$0]++' | less -
对文件按
.分隔够取第一个,去重后输出
$ awk -F'.' '{a[$1]++;} END {for (i in a ) print i ", " a[i];}' hive_tables.txt
dm, 642
dw, 14338
-
根据
"分割,取字段 :awk -F'"' '{print $6}' cartridge_msg | head -7 -
看看统计每个用户的进程的占了多少内存(注:sum的RSS那一列)
ps aux | awk 'NR!=1{a[$1]+=$6;} END { for(i in a) print i ", " a[i]"KB";}' -
awk去重:
awk '!x[$0]++' file1awk > file2 -
sh脚本中杀死进程:
ps -ef | grep java | grep -v consumer |awk '{print $2}' | xargs -p kill -9 -
查询行数相关:
awk 'FNR==16000' file -
查询需要的信息并且加上第一行:
awk 'NR==1;/205613/{print}' Submissions.txt -
查看所有行的记录:
awk '//{print}' passwd.txt -
过滤到
localhost:awk '/localhost/{print}' /etc/hosts -
按
~分隔后,取field后,去重:awk -F'~' '!($12 in a){a[$12];print $12}' products_1.txt -
按
~分隔后,取field后,去重(去掉第一行):awk -F'~' '{if(NR!=1 && !($12 in a) ) {a[$12];print $12}}' products_1.txt
funtions.awk:计算从1到100的和
#! /bin/awk -f
#add
function Add(firstNum, secondNum) {
sum = 0
for (i = firstNum; i <= secondNum; i++) {
sum = sum + i;
}
return sum
}
function main(num1, num2) {
result = Add(num1, num2)
print "Sum is:", result
}
#execute
function
BEGIN {
main(1, 100)
}
passwd.awk:以: 分割,打印出想要的field,$NF表示选定每一行的最后一列
#! /bin/awk -f
BEGIN {FS=":"}
/root/ {print "Username is:"$1,"UID is:"$3,"GID is:"$4,"Shell is:"$NF}
passwd.txt:文件截取,
执行命令: awk -f passwd.awk passwd.txt OR ./passwd.awk passwd.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
2.sed
基础知识
语法
sed [-hnV][-e<script>][-f<script文件>][文本文件]
参数说明:
-e<script>或--expression=<script> 以选项中指定的script来处理输入的文本文件。
-f<script文件>或--file=<script文件> 以选项中指定的script文件来处理输入的文本文件。
-h或--help 显示帮助。
-n或--quiet或--silent 仅显示script处理后的结果。
-V或--version 显示版本信息。
动作说明:
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
- 查看文件的第1到第5行:
sed -n '1,5p' passwd.txt - 查看文件的第1到结尾:
sed -n '1,$p' passwd.txt - 去除文件的空行:
sed -i '/^$/d' passwd.txt慎用-i,原地修改 - 去除文件的空行:
cat passwd.txt | awk '{if($0!="") print }' - 在文件的每行结尾处添加字符串:
sed -i 's/$/_MODIFY/' file - 在文件的每行开头处添加字符串:
sed -i 's/^/HEAD_/g' passwd.txt - 替换文件的
_MODIFY为_UPDATE:sed -e 's/_MODIFY/_UPDATE/' passwd.txt > passwd_update.txt - 替换文件的字符串:
sed -i "s/my/Hao Chen's/g" pets.txt其中/g是全局模式表示每一行出现的符合规则的都被替换掉 - 删除第2行到末尾行:
sed '2,$d' my.txt
找到access.log文件中/req/v2/fetch的 请求,拿到7 14 15列,然后按 "切分, 选取大于1s的输出
cat access.log | awk -F' ' '/req/v2/fetch/{print $7, $14, $NF}' | awk -F '"' '$4>1' | awk -F' ' '{print $0}' | less
cat hiveassistant3-server-prod-https_access.log | awk -F' ' '/job/engine/result/{print $7}' | less > ../hadoop/hive_server_access_job_engine_result.log
awk '/(jobid=)(.*)(&que)/{print $1}' hive_server_access_job_engine_result.log | less
提取两个字符之间的字符串
sed -E 's/.*jobid=(.*)&id=.*/1/' hive_server_access_job_engine_result.log | less
- 统计机器中网络连接各个状态个数
^tcp 表示以tcp开头的行,也就是tcp类型的网络连接
$NF 表示的最后一个Field(列),即输出最后一个字段的内容
++S[$NF] 表示自增了
{ for(a in S ) print a, S[a] } 对结果进行for loop 给出状态的类型已经条数
$ netstat -a | awk '/^tcp/ {++S[$NF]} END { for(a in S ) print a, S[a] } '
LISTEN 75
CLOSE_WAIT 38
ESTABLISHED 377
TIME_WAIT 144
实际案例
分析nginx日志
access.log:
10.1.9.112 - - [29/Sep/2020:00:00:01 +0800] "POST /api/pre/10177/schemaAction HTTP/1.1" 200 5 "-" "okhttp/3.14.2" "-" "0.051" "0.051"
10.1.9.112 - - [29/Sep/2020:00:00:01 +0800] "POST /api/pre/10177/schemaAction HTTP/1.1" 200 5 "-" "okhttp/3.14.2" "-" "0.052" "0.052"
10.1.9.112 - - [29/Sep/2020:00:00:01 +0800] "POST /api/pre/10177/schemaAction HTTP/1.1" 200 5 "-" "okhttp/3.14.2" "-" "0.078" "0.078"
10.1.9.112 - - [29/Sep/2020:00:00:01 +0800] "POST /api/pre/10177/schemaAction HTTP/1.1" 200 5 "-" "okhttp/3.14.2" "-" "0.079" "0.079"
10.1.9.112 - - [29/Sep/2020:00:00:01 +0800] "POST /api/pre/10177/schemaAction HTTP/1.1" 200 5 "-" "okhttp/3.14.2" "-" "0.085" "0.085"
10.1.9.112 - - [29/Sep/2020:00:00:01 +0800] "POST /api/pre/10177/schemaAction HTTP/1.1" 200 5 "-" "okhttp/3.14.2" "-" "0.065" "0.065"
10.1.9.112 - - [29/Sep/2020:00:00:01 +0800] "POST /api/pre/10177/schemaAction HTTP/1.1" 200 5 "-" "okhttp/3.14.2" "-" "0.081" "0.081"
10.1.9.112 - - [29/Sep/2020:00:00:01 +0800] "POST /api/pre/10177/schemaAction HTTP/1.1" 200 5 "-" "okhttp/3.14.2" "-" "0.079" "0.079"
10.1.9.112 - - [29/Sep/2020:00:00:02 +0800] "POST /api/pre/10177/schemaAction HTTP/1.1" 200 5 "-" "okhttp/3.14.2" "-" "0.080" "0.080"
10.1.9.112 - - [29/Sep/2020:00:00:02 +0800] "POST /api/pre/10177/schemaAction HTTP/1.1" 200 5 "-" "okhttp/3.14.2" "-" "0.087" "0.087"
需求1:列出日志中访问最多的10个ip
a[$1]++ 创建数组a,以第一列作为下标,使用运算符++作为数组元素,元素初始值为0。处理一个IP时,下标是IP,元素加1,处理第二个IP时,下标是IP,元素加1,如果这个IP已经存在,则元素再加1,也就是这个IP出现了两次,元素结果是2,以此类推
sort 命令 中 -r 按倒序来排列熟悉, -n 按数值的大小排序
-k 可以按多列进行排序 如sort -k 1 -k 2 test.txt,那么就会根据test.txt文件中的第一列和第二列进行排序
$ awk '{a[$1]++}END{for(i in a)print a[i],i | " sort -k1 -nr | head -n10"}' access.log
72259 10.XXX.113.22
...
另外一种方法:
awk '{print $1} ' access.log | sort | uniq -c | sort -k1 -nr | head -10
89721 10.XXX.113.22
...
需求2:统计日志中访问次数超过1000次的ip
将结果保存a数组后,输出时判断符合要求的IP
$ awk '{ a[$1]++} END {for (i in a ){ if (a[i] > 1000) print i, a[i]}} ' access.log
10.1.XXX.109 6717
另外一种方法:
是将结果保存a数组时,并判断符合要求的IP放到b数组,最后打印b数组的IP
awk '{a[$1]++;if(a[$1]>100){b[$1]++}}END{for(i in b){print i,a[i]}}' access.log
需求3:统计访问最多的前10个页面($request)
$ awk '{a[$7]++}END{for(i in a)print a[i],i|"sort -k1 -nr|head -n10"}' access.log
34453 /tasks/req/XXXX?token=XXXX
需求4:统计每个IP访问状态码数量($status)
1 是ip 9对应的是状态码 用 "--->"来连接
$ awk '{a[$1"--->"$9]++} END {for( i in a) print i, a[i]}' access.log | head -10
10.1.XXX.109--->500 3