测试环境
- 节点:
2 台主节点,6台计算节点
- 机器配置:
16个物理核
128G内存
12*3T磁盘
- 操作系统:
redhat 7.2
- 版本:
CDH 5.7.1-1.cdh5.7.1.p0.11
impala_kudu 2.7.0-1.cdh5.9.0.p0.23
kudu 0.9.1-1.kudu0.9.1.p0.32
spark 2.0.0
- 对照组:
Spark on Parquet
Impala on Parquet
Impala on Kudu
测试数据、语句、场景
TPC-DS,是用于评测决策支持系统(或数据仓库)的标准SQL测试集。这个测试集包含对大数据集的统计/报表生成/联机查询/数据挖掘等复杂应用,测试用的数据和值是有倾斜的,与真实数据一致。可以说TPC-DS是与真实场景非常接近的一个测试集,也是难度较大的一个测试集。
TPC-DS支持指定不同的数据大小。本次测试选择的数据大小分别为10GB、100GB、1TB、10TB。数据大小与表rows的关系如下图所示:

TPC-DS一共99个测试案例,遵循SQL'99和SQL 2003的语法标准,SQL案例比较复杂.分析的数据量大,并且测试案例是在回答真实的商业问题.测试案例中包含各种业务模型(如分析报告型,迭代式的联机分析型,数据挖掘型等).本次测试使用了大部分的query,某些query由于语法错误、语法不兼容,或者在Hive、Spark、Impala下面都无法跑过,因此这些query不纳入性能测试的范围。
参数配置
本次测验基本上使用了CDH的默认配置。一些重要配置有:
- Hadoop: 使用非安全模式,不带kerberos认证。
- Impala: 使用自带的Resource Management,而非YARN;Catalog Server设置内存为32gb;impalad内存设置为64gb。
- Kudu: 使用data disks的第一块磁盘作为WAL磁盘(也就是使用SATA盘);Kudu Tablet Server内存设置为32gb。
- Spark: 配置如下
spark.serializer org.apache.spark.serializer.KryoSerializer spark.driver.memory 10g spark.executor.memory 10g spark.executor.instances 36 spark.executor.cores 5 spark.yarn.executor.memoryOverhead 2g spark.sql.autoBroadcastJoinThreshold 209715200
测试步骤
- 通过tpcds-gen在hdfs上生成parquet数据
- 利用impala将tpcds数据从hdfs上导入到kudu
- 测试impala on kudu的性能
- 测试impala on parquet性能
- 测试spark on parquet的性能
测试结果
Kudu数据导入速度

如图所示,kudu在导入小表时速度非常快,当导入大表时,速度反而变慢,性能严重下降。为了避免表字段类型、字段数目、大小造成的速度差异。我们根据同一张表store_sales进行比较,其结果为

(单位rows/秒, 越大越好)
由于kudu一开始先将数据插入到memRowSet,因此在数据集较小时插入速度非常快。当插入的数据达到10亿条级别以上时,性能开始出现严重的downgrade。根据Todd在slack上的解释是,impala插入数据时采用了随机的顺序,如果先将数据排序,再用impala导入可改善插入性能。目前社区正在改善此问题。
Kudu 查询性能
首先我们比较一下100GB下impala on kudu 和impala on parquet的性能

(单位second, 越小越好)
如图所示,在小数据集的查询性能上,kudu普遍比parquet慢了2倍~10倍。
如果我们再比较一下1TB下的性能,可以发现

Kudu比parquet慢了10倍~100倍。这其中很可能是由于impala对kudu缺少优化导致的。因此我们再来比较基本查询kudu的性能

如图所示,单从简单查询来看,kudu的性能和imapla差距不是特别大,其中出现的波动是由于缓存导致的。和impala的差异主要来自于impala的优化。
Spark 2.0 / Impala查询性能
查询速度

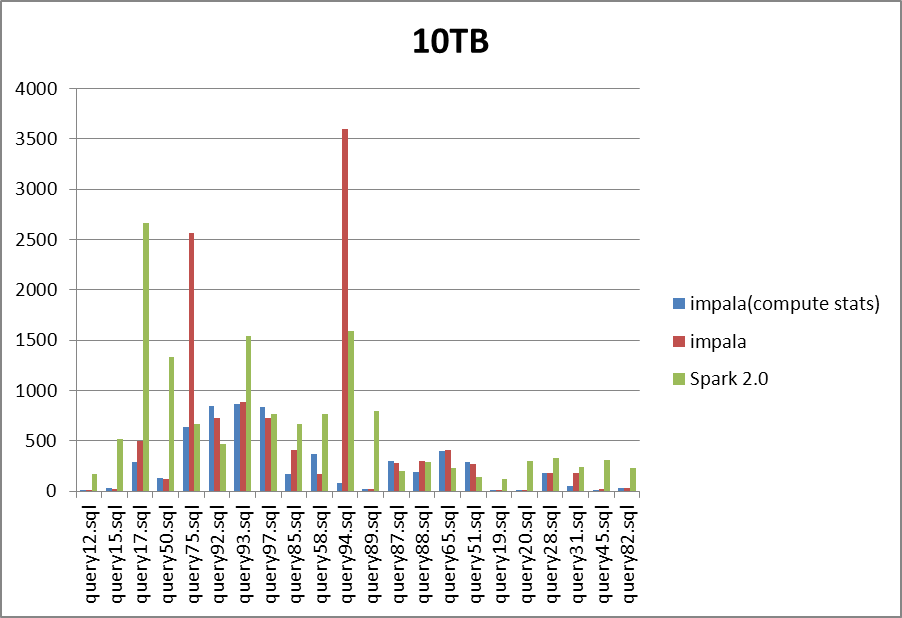
(单位second, 越小越好)
从数据大小分析, 1TB和10TB下的差异不大。
从语句进行分析,Impala对于query75、query94下的性能较差,很可能是语句优化,join顺序导致的异常。Spark对于query17、query50性能较差。
综合分析,可以发现impala的速度普遍比Spark快一倍以上。Impala经过compute stats之后,消除了query75、query94这两个语句的异常,在其它语句上的速度提升达到了一倍以上,在某些语句上compute stats后速度反而下降,如query58,然而这种情况很少见。
资源使用情况
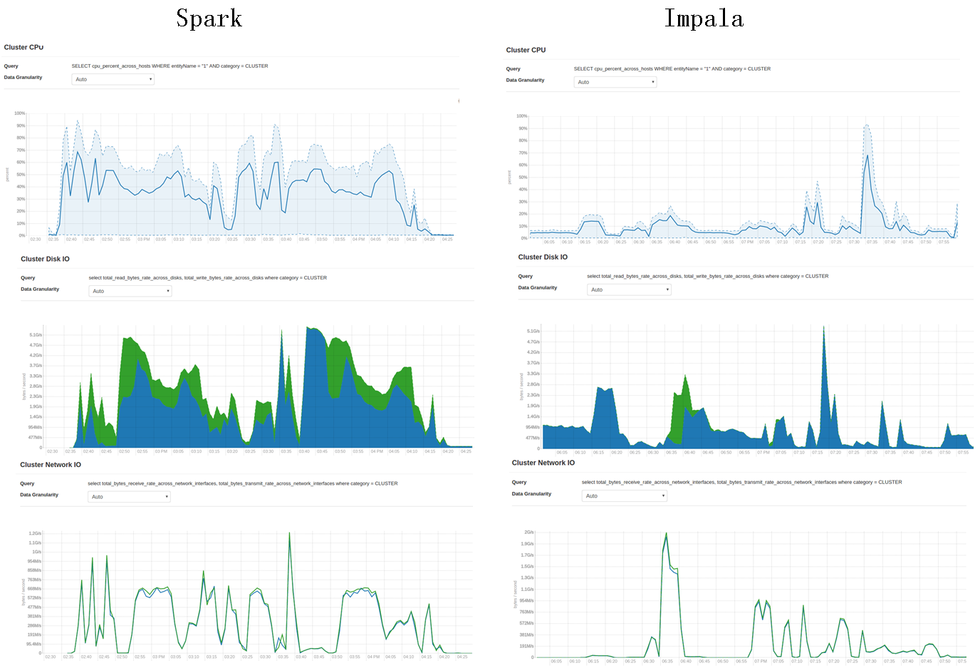
Impala的资源使用整体少于Spark,磁盘的数据读取少于Spark,这对于速度的提高至关重要,这与其语句的优化有关。Impala的CPU一直维持在较低的水平,说明其C++的实现比JAVA高效。
Spark的CPU占用较高,但是维持在50%的水平,可见CPU并没有成为其瓶颈。Spark的磁盘写入(绿色)非常多,这也许是其速度的主要瓶颈。从网络IO上来看Spark也多余Impala,这一点可能与语句的优化、join、shuffle的实现方式有关。
--------
By 浴雨青山
商业转载请联系作者获得授权,非商业转载请注明出处