摘要: 本文结合《Spring源码深度解析》来分析Spring 5.0.6版本的源代码。若有描述错误之处,欢迎指正。
目录
一、processPropertyPlaceHolders属性的处理
二、根据配置属性生成过滤器
三、扫描Java文件
我们在applicationContext.xml中配置了userMapper供需要时使用。但如果需要用到的映射器较多的话,采用这种配置方式就显得很低效。为了解决这个问题,我们可以使用MapperScannerConfigurer,让它扫描特定的包,自动帮我们成批地创建映射器。这样一来,就能大大减少配置的工作量,比如我们将applicationContext.xml文件中的配置改成如下:
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <!-- 配置数据源 --> <bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close" lazy-init="true"> <property name="driverClassName" value="${jdbc.driverClassName}"/> <property name="url" value="${jdbc.url}"/> <property name="username" value="${jdbc.username}"/> <property name="password" value="${jdbc.password}"/> <!-- 配置连接池初始化大小、最小、最大 --> <property name="initialSize" value="${jdbc.initialSize}"/> <property name="minIdle" value="${jdbc.minIdle}"/> <property name="maxActive" value="${jdbc.maxActive}"/> <!-- 配置获取连接等待超时的时间,单位是毫秒 --> <property name="maxWait" value="${jdbc.maxWait}"/> <!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 --> <property name="timeBetweenEvictionRunsMillis" value="${jdbc.timeBetweenEvictionRunsMillis}"/> <!-- 配置一个连接在池中最小生存的时间,单位是毫秒 --> <property name="minEvictableIdleTimeMillis" value="${jdbc.minEvictableIdleTimeMillis}"/> <property name="validationQuery" value="select 1"/> <property name="testWhileIdle" value="${jdbc.testWhileIdle}"/> <property name="testOnBorrow" value="${jdbc.testOnBorrow}"/> <property name="testOnReturn" value="${jdbc.testOnReturn}"/> <!-- 打开PSCache,并且指定每个连接上PSCache的大小 --> <property name="poolPreparedStatements" value="${jdbc.poolPreparedStatements}"/> <property name="maxPoolPreparedStatementPerConnectionSize" value="${jdbc.maxPoolPreparedStatementPerConnectionSize}"/> <!-- 统计sql filter --> <property name="proxyFilters"> <list> <bean class="com.alibaba.druid.filter.stat.StatFilter"> <property name="mergeSql" value="true"/> <property name="slowSqlMillis" value="${jdbc.slowSqlMillis}"/> <property name="logSlowSql" value="true"/> </bean> </list> </property> </bean> <bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"> <property name="dataSource" ref="dataSource"/> <property name="configLocation" value="classpath:mybatis-config.xml"/> </bean> <bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> <property name="basePackage" value="org.cellphone.uc.repo.mapper"/> <property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/> </bean> </beans>
在上面的配置中,我们屏蔽掉了最原始的代码(userMapper的创建)而增加了MapperScannerConfigurer的配置,basePackage属性是让你为映射器接口文件设置基本的包路径。你可以使用分号或逗号作为分隔符设置多于一个的包路径。每个映射器将会在指定的包路径中递归地被搜索到。被发现的映射器将会使用Spring对自动侦测组件默认的命名策略来命名。也就是说,如果没有发现注解,它就会使用映射器的非大写的非完全限定类名。但是如果发现了@Component 或 JSR-330@Named 注解,它会获取名称。
通过上面的配罝,Spring就会帮助我们对org.cellphone.uc.repo.mapper下面的所有接口进行自动的注入,而不需要为每个接口重复在Spring配置文件中进行声明了。那么,这个功能又是如何做到的呢? MapperScannerConfigurer 中又有哪些核心操作呢?同样,首先査看类的层次结构图,如下图所示。
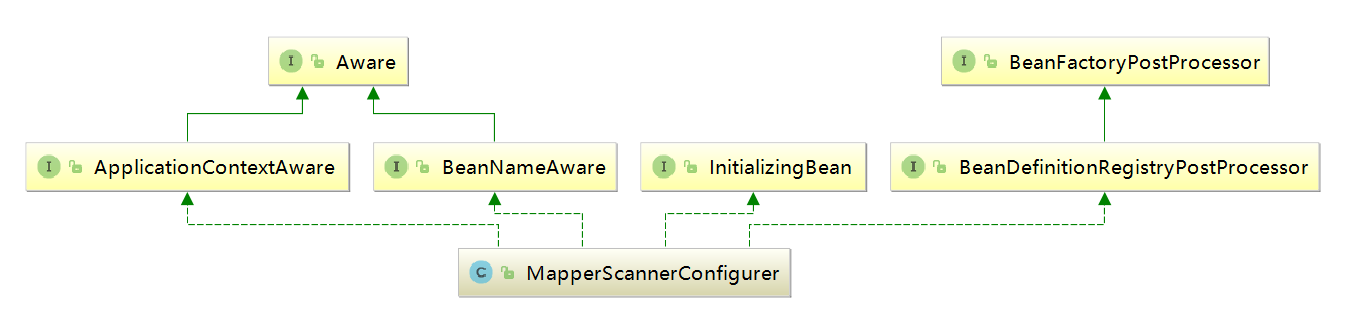
我们又看到了令人感兴趣的接口InitializingBean,马上査找类的afterPropertiesSet方法来看看类的初始化逻辑。
@Override public void afterPropertiesSet() throws Exception { notNull(this.basePackage, "Property 'basePackage' is required"); }
很遗憾,分析并没有像我们之前那样顺利,afterPropertiesSet()方法除了一句对basePackage属性的验证代码外并没有太多的逻辑实现。好吧,让我们回过头再次査看MapperScannerConfigurer类层次结构图中感兴趣的接口。于是,我们发现了BeanDefinitionRegistryPostProcessor与BeanFactoryPostProcessor,Spring在初始化的过程中同样会保证这两个接口的调用。
首先査看 MapperScannerConflgurer 类中对于 BeanFactoryPostProcessor 接口的实现:
@Override public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) { // left intentionally blank }
没有任何逻辑实现,只能说明我们找错地方了,继续找,査看MapperScannerConfigurer 类中对于 BeanDefinitionRegistryPostProcessor 接口的实现。
@Override public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) { if (this.processPropertyPlaceHolders) { processPropertyPlaceHolders(); } ClassPathMapperScanner scanner = new ClassPathMapperScanner(registry); scanner.setAddToConfig(this.addToConfig); scanner.setAnnotationClass(this.annotationClass); scanner.setMarkerInterface(this.markerInterface); scanner.setSqlSessionFactory(this.sqlSessionFactory); scanner.setSqlSessionTemplate(this.sqlSessionTemplate); scanner.setSqlSessionFactoryBeanName(this.sqlSessionFactoryBeanName); scanner.setSqlSessionTemplateBeanName(this.sqlSessionTemplateBeanName); scanner.setResourceLoader(this.applicationContext); scanner.setBeanNameGenerator(this.nameGenerator); scanner.registerFilters(); scanner.scan(StringUtils.tokenizeToStringArray(this.basePackage, ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS)); }
Bingo!这次找对地方了。大致看一下代码实现,正是完成了对指定路径扫描的逻辑。那么,我们就以此为入口,详细地分析MapperScannerConfigurer 所提供的逻辑实现。
一、processPropertyPlaceHolders属性的处理
首先,难题就是processPropertyPlaceHolders属性的处理。或许读者并未过多接触此属性,我们只能查看processPropertyPlaceHolders()函数来反推此属性所代表的功能。
/* * BeanDefinitionRegistries are called early in application startup, before * BeanFactoryPostProcessors. This means that PropertyResourceConfigurers will not have been * loaded and any property substitution of this class' properties will fail. To avoid this, find * any PropertyResourceConfigurers defined in the context and run them on this class' bean * definition. Then update the values. */ private void processPropertyPlaceHolders() { Map<String, PropertyResourceConfigurer> prcs = applicationContext.getBeansOfType(PropertyResourceConfigurer.class); if (!prcs.isEmpty() && applicationContext instanceof ConfigurableApplicationContext) { BeanDefinition mapperScannerBean = ((ConfigurableApplicationContext) applicationContext) .getBeanFactory().getBeanDefinition(beanName); // PropertyResourceConfigurer does not expose any methods to explicitly perform // property placeholder substitution. Instead, create a BeanFactory that just // contains this mapper scanner and post process the factory. DefaultListableBeanFactory factory = new DefaultListableBeanFactory(); factory.registerBeanDefinition(beanName, mapperScannerBean); for (PropertyResourceConfigurer prc : prcs.values()) { prc.postProcessBeanFactory(factory); } PropertyValues values = mapperScannerBean.getPropertyValues(); this.basePackage = updatePropertyValue("basePackage", values); this.sqlSessionFactoryBeanName = updatePropertyValue("sqlSessionFactoryBeanName", values); this.sqlSessionTemplateBeanName = updatePropertyValue("sqlSessionTemplateBeanName", values); } }
不知读者是否悟出了此函数的作用呢?或许此函数的说明会给我们一些提示:BeanDefinitionRegistries会在应用启动的时候调用,并且会早于BeanFactoryPostProcessors的调用,这就意味着PropertyResourceConfigurers还没有被加载所有对于属性文件的引用将会失效。为避免此种情况发生,此方法手动地找出定义的PropertyResourceConfigurers并进行提前调用以保证对于属性的引用可以正常工作。
我想读者已经有所感悟,结合之前讲过的PropertyResourceConfigurer的用法,举例说明一 下,如要创建配置文件如test.properties,并添加属性对:
basePackage = org.cellphone.uc.repo.mapper
然后在Spring配置文件中加入属性文件解析器:
<bean id="mesHandler" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer"> <property name="locations"> <list> <value>config/test.properties</value> </list> </property> </bean>
修改 MapperScannerConfigurer 类型的 bean 的定义:
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> <property name="basePackage" value="${basePackage}"/> <property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/> </bean>
此时你会发现,这个配置并没有达到预期的效果,因为在解析${basePackage}的时候 PropertyPlaceholderConfigurer还没有被调用,也就是属性文件中的属性还没有加载至内存中,Spring还不能直接使用它。为了解决这个问题,Spring提供了processPropertyPlaceHolders属性,你需要这样配置MapperScannerConfigurer类型的 bean。
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> <property name="basePackage" value="${basePackage}"/> <property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/> <property name="processPropertyPlaceHolders" value="true"/> </bean>
通过processPropertyPlaceHolders属性的配置,将程序引入我们正在分析的processPropertyPlaceHolders函数中来完成属性文件的加载。至此,我们终于理清了这个属性的作用,再次回顾这个函数所做的事情。
(1)找到所有已经注册的PropertyResourceConflgurer类型的bean。
(2)模拟Spring中的环境来用处理器。这里通过使用new DefaultListableBeanFactory()来 模拟Spring中的环境(完成处理器的调用后便失效),将映射的bean,也就是MapperScannerConfigurer类型bean注册到环境中来进行后理器的调用,处理器PropertyPlaceholderConfigurer调用完成的功能,即找出所有bean中应用属性文件的变量并替换。也就是说,在处理器调用后,模拟环境中模拟的MapperScannerConfigurer类型的bean如果有引入属性文件中的属性那么已经被替换了,这时,再将模拟bean中相关的属性提取出来应用在真实的bean中。
二、根据配置属性生成过滤器
在postProcessBeanDefinitionRegistry方法中可以看到,配置中支持很多属性的设定,但是我们感兴趣的或者说影响扫描结果的并不多,属性设置后通过在scanner.registerFilters()代码中生成对应的过滤器来控制扫描结果。
/** * Configures parent scanner to search for the right interfaces. It can search * for all interfaces or just for those that extends a markerInterface or/and * those annotated with the annotationClass */ public void registerFilters() { boolean acceptAllInterfaces = true; // if specified, use the given annotation and / or marker interface // 对于annotationClass属性的处理 if (this.annotationClass != null) { addIncludeFilter(new AnnotationTypeFilter(this.annotationClass)); acceptAllInterfaces = false; } // override AssignableTypeFilter to ignore matches on the actual marker interface // 对于markerInterface属性的处理 if (this.markerInterface != null) { addIncludeFilter(new AssignableTypeFilter(this.markerInterface) { @Override protected boolean matchClassName(String className) { return false; } }); acceptAllInterfaces = false; } if (acceptAllInterfaces) { // default include filter that accepts all classes addIncludeFilter((metadataReader, metadataReaderFactory) -> true); } // exclude package-info.java // 不扫描package-info.java文件 addExcludeFilter((metadataReader, metadataReaderFactory) -> { String className = metadataReader.getClassMetadata().getClassName(); return className.endsWith("package-info"); }); }
代码中得知,根据之前属性的配置生成了对应的过滤器。
(1)annotationClass 属性处理。
如果annotationClass不为空,表示用户设置了此属性,那么就要根据此属性生成过滤器以保证达到用户想要的效果,而封装此属性的过滤器就是AnnotationTypeFilter。AnnotationTypeFilter保证在扫描对应Java文件时只接受标记有注解为annotationClass的接口。
(2)markerlnterface 属性处理。
如果markerlnterface不为空,表示用户设置了此属性,那么就要根据此属性生成过滤器以保证达到用户想要的效果,而封装此属性的过滤器就是实现AssignableTypeFilter接口的局部类。表示扫描过程中只有实现markerlnterface接口的接口才会被接受。
(3)全局默认处理。
在上面两个属性中如果存在其中任何属性,acceptAllInterfaces的值将会改变,但是如果用户没有设定以上两个属性,那么,Spring会为我们增加一个默认的过滤器实现TypeFilter接口的局部类,旨在接受所有接口文件。
(4)package-info.java 处理。
对于命名为package-info的Java文件,默认不作为逻辑实现接口,将其排除掉,使用TypeFilter接口的局部类实现match方法。
从上面的函数我们看出,控制扫描文件Spring通过不同的过滤器完成,这些定义的过滤器记录在了includeFilters和excludeFilters属性中。
/** * Add an include type filter to the <i>end</i> of the inclusion list. */ public void addIncludeFilter(TypeFilter includeFilter) { this.includeFilters.add(includeFilter); } /** * Add an exclude type filter to the <i>front</i> of the exclusion list. */ public void addExcludeFilter(TypeFilter excludeFilter) { this.excludeFilters.add(0, excludeFilter); }
至于过滤器为什么会在扫描过程中起作用,我们在讲解扫描实现时候再继续深人研究。
三、扫描Java文件
设置了相关属性以及生成了对应的过滤器后便可以进行文件的扫描了,扫描工作是由ClassPathMapperScanner类型的实例 scanner 中的 scan 方法完成的。
/** * Perform a scan within the specified base packages. * @param basePackages the packages to check for annotated classes * @return number of beans registered */ public int scan(String... basePackages) { int beanCountAtScanStart = this.registry.getBeanDefinitionCount(); doScan(basePackages); // Register annotation config processors, if necessary. // 如果配置了includeAnnotationConfig, 则注册对应注解的处理器以保证注解功能的正常使用 if (this.includeAnnotationConfig) { AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry); } return (this.registry.getBeanDefinitionCount() - beanCountAtScanStart); }
scan是个全局方法,扫描工作通过doScan(basePackages)委托给了 doScan方法,同时,还包括了 includeAnnotationConfig 属性的处理,AnnotationConfigUtils.registerAnnotationConfigProcessors (this.registry)代码主要是完成对于注解处理器的简单注册,比如AutowiredAnnotationBeanPostProcessor、RequiredAnnotationBeanPostProcessor等,这里不再赞述,我们重点研究文件扫描功能的实现。
/** * Calls the parent search that will search and register all the candidates. * Then the registered objects are post processed to set them as * MapperFactoryBeans */ @Override public Set<BeanDefinitionHolder> doScan(String... basePackages) { Set<BeanDefinitionHolder> beanDefinitions = super.doScan(basePackages); if (beanDefinitions.isEmpty()) { // 如果没有扫描到任何文件发出警告 LOGGER.warn(() -> "No MyBatis mapper was found in '" + Arrays.toString(basePackages) + "' package. Please check your configuration."); } else { processBeanDefinitions(beanDefinitions); } return beanDefinitions; } private void processBeanDefinitions(Set<BeanDefinitionHolder> beanDefinitions) { GenericBeanDefinition definition; for (BeanDefinitionHolder holder : beanDefinitions) { definition = (GenericBeanDefinition) holder.getBeanDefinition(); String beanClassName = definition.getBeanClassName(); LOGGER.debug(() -> "Creating MapperFactoryBean with name '" + holder.getBeanName() + "' and '" + beanClassName + "' mapperInterface"); // the mapper interface is the original class of the bean // but, the actual class of the bean is MapperFactoryBean // 开始构造MapperFactoryBean类型的bean definition.getConstructorArgumentValues().addGenericArgumentValue(beanClassName); // issue #59 definition.setBeanClass(this.mapperFactoryBean.getClass()); definition.getPropertyValues().add("addToConfig", this.addToConfig); boolean explicitFactoryUsed = false; if (StringUtils.hasText(this.sqlSessionFactoryBeanName)) { definition.getPropertyValues().add("sqlSessionFactory", new RuntimeBeanReference(this.sqlSessionFactoryBeanName)); explicitFactoryUsed = true; } else if (this.sqlSessionFactory != null) { definition.getPropertyValues().add("sqlSessionFactory", this.sqlSessionFactory); explicitFactoryUsed = true; } if (StringUtils.hasText(this.sqlSessionTemplateBeanName)) { if (explicitFactoryUsed) { LOGGER.warn(() -> "Cannot use both: sqlSessionTemplate and sqlSessionFactory together. sqlSessionFactory is ignored."); } definition.getPropertyValues().add("sqlSessionTemplate", new RuntimeBeanReference(this.sqlSessionTemplateBeanName)); explicitFactoryUsed = true; } else if (this.sqlSessionTemplate != null) { if (explicitFactoryUsed) { LOGGER.warn(() -> "Cannot use both: sqlSessionTemplate and sqlSessionFactory together. sqlSessionFactory is ignored."); } definition.getPropertyValues().add("sqlSessionTemplate", this.sqlSessionTemplate); explicitFactoryUsed = true; } if (!explicitFactoryUsed) { LOGGER.debug(() -> "Enabling autowire by type for MapperFactoryBean with name '" + holder.getBeanName() + "'."); definition.setAutowireMode(AbstractBeanDefinition.AUTOWIRE_BY_TYPE); } } }
此时,虽然还没有完成介绍到扫描的过程,但是我们也应该理解了Spring中对于自动扫描的注册,声明MapperScannerConfigurer类型的bean目的是不需要我们对于每个接口都注册一个MapperFactoryBean类型的对应的bean,但是,不在配置文件中注册并不代表这个bean不存在,而是在扫描的过程中通过编码的方式动态注册。实现过程我们在上面的函数中可以看得非常清楚。
/** * Perform a scan within the specified base packages, * returning the registered bean definitions. * <p>This method does <i>not</i> register an annotation config processor * but rather leaves this up to the caller. * @param basePackages the packages to check for annotated classes * @return set of beans registered if any for tooling registration purposes (never {@code null}) */ protected Set<BeanDefinitionHolder> doScan(String... basePackages) { Assert.notEmpty(basePackages, "At least one base package must be specified"); Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>(); for (String basePackage : basePackages) { // 扫描basePackage路径下java文件 Set<BeanDefinition> candidates = findCandidateComponents(basePackage); for (BeanDefinition candidate : candidates) { // 解析scope属性 ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate); candidate.setScope(scopeMetadata.getScopeName()); String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry); if (candidate instanceof AbstractBeanDefinition) { postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName); } if (candidate instanceof AnnotatedBeanDefinition) { // 如果是AnnotatedBeanDefinition类型的bean,需要检测下常用注解如:Primary、Lazy 等 AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate); } // 检测当前bean是否已经注册 if (checkCandidate(beanName, candidate)) { BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName); // 如果当前bean是用于生成代理的bean那么需要进一步处理 definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry); beanDefinitions.add(definitionHolder); registerBeanDefinition(definitionHolder, this.registry); } } } return beanDefinitions; } /** * Scan the class path for candidate components. * @param basePackage the package to check for annotated classes * @return a corresponding Set of autodetected bean definitions */ public Set<BeanDefinition> findCandidateComponents(String basePackage) { if (this.componentsIndex != null && indexSupportsIncludeFilters()) { return addCandidateComponentsFromIndex(this.componentsIndex, basePackage); } else { return scanCandidateComponents(basePackage); } } private Set<BeanDefinition> scanCandidateComponents(String basePackage) { Set<BeanDefinition> candidates = new LinkedHashSet<>(); try { String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX + resolveBasePackage(basePackage) + '/' + this.resourcePattern; Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath); boolean traceEnabled = logger.isTraceEnabled(); boolean debugEnabled = logger.isDebugEnabled(); for (Resource resource : resources) { if (traceEnabled) { logger.trace("Scanning " + resource); } if (resource.isReadable()) { try { MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource); if (isCandidateComponent(metadataReader)) { ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader); sbd.setResource(resource); sbd.setSource(resource); if (isCandidateComponent(sbd)) { if (debugEnabled) { logger.debug("Identified candidate component class: " + resource); } candidates.add(sbd); } else { if (debugEnabled) { logger.debug("Ignored because not a concrete top-level class: " + resource); } } } else { if (traceEnabled) { logger.trace("Ignored because not matching any filter: " + resource); } } } catch (Throwable ex) { throw new BeanDefinitionStoreException( "Failed to read candidate component class: " + resource, ex); } } else { if (traceEnabled) { logger.trace("Ignored because not readable: " + resource); } } } } catch (IOException ex) { throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex); } return candidates; }
findCandidateComponents方法根据传人的包路径信息并结合类文件路径拼接成文件的绝对路径,同时完成了文件的扫描过程并且根据对应的文件生成了对应的bean,使用 ScannedGenericBeanDefinition 类型的 bean 承载信息,bean 中只记录了resource 和 source 信息。 这里,我们更感兴趣的是isCandidateComponent(metadataReader),此句代码用于判断当前扫描的文件是否符合要求,而我们之前注册的一些过滤器信息也正是在此时派上用场的。
/** * Determine whether the given class does not match any exclude filter * and does match at least one include filter. * @param metadataReader the ASM ClassReader for the class * @return whether the class qualifies as a candidate component */ protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException { for (TypeFilter tf : this.excludeFilters) { if (tf.match(metadataReader, getMetadataReaderFactory())) { return false; } } for (TypeFilter tf : this.includeFilters) { if (tf.match(metadataReader, getMetadataReaderFactory())) { return isConditionMatch(metadataReader); } } return false; }
我们看到了之前加入过滤器的两个属性excludeFilters、includeFilters,并且知道对应的文件是否符合要求是根据过滤器中的match方法所返回的信息来判断的,当然用户可以实现并注册满足自己业务逻辑的过滤器来控制扫描的结果,metadataReader中有你过滤所需要的全部文件信息。至此,我们完成了文件的扫描过程的分析。