JDK中的集合框架分为两大类:Collection和Map。Collection以一组Object的形式保存元素,Map以Key-Value对的形式保存元素。
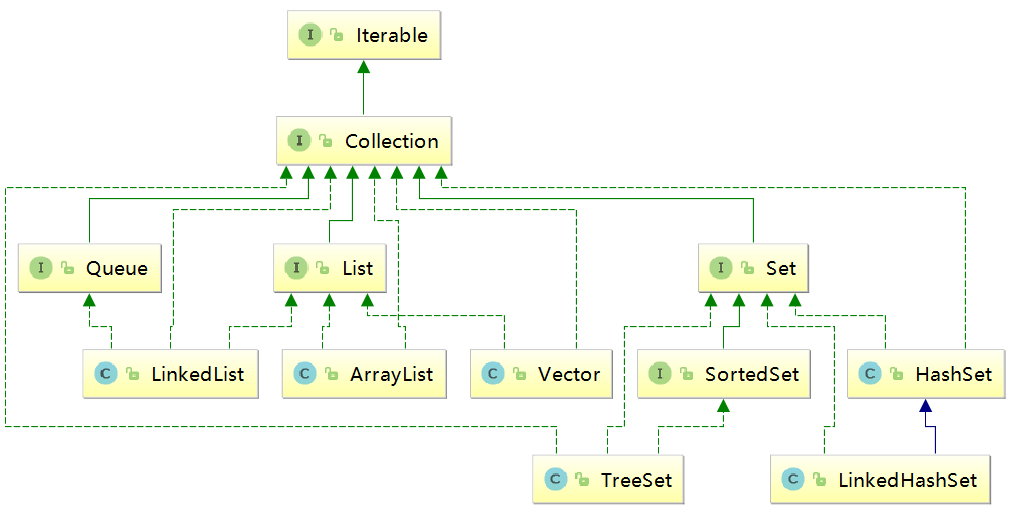
上图列出的类并不完整,只列举了平时比较常用的类。
基本接口和类型
Collection集合
该接口是Set和List的父接口,主要提供了下面的方法:
| boolean add(E e) | 往集合中添加新元素。添加成功,返回true,否则返回false |
| Iterator<E> iterator() | 返回Iterator对象,这样就可以遍历集合中的所有元素了 |
| boolean contains(Object o) | 判断集合中是否包含指定的元素 |
| int size() | 取得集合中元素的个数 |
| void clear() | 删除集合中的所有元素 |
Collection是最基本的集合接口,一个Collection代表一组Object,即Collection的元素(Elements)。一些Collection允许相同的元素而另一些不行。一些能排序而另一些不行。Java SDK不提供直接继承自Collection的类,JavaSDK提供的类都是继承自Collection的子接口,如List和Set。
所有实现Collection接口的类都必须提供两个标准的构造函数:无参数的构造函数用于创建一个空的Collection,有一个Collection参数的构造函数用于创建一个新的Collection,这个新的Collection与传入的Collection有相同的元素。后一个构造函数允许用户复制一个Collection。
如何遍历Collection中的每一个元素?不论Collection的实际类型如何,它都支持一个iterator()的方法,该方法返回一个迭代对象,使用该迭代对象即可逐一访问Collection中每一个元素。典型的用法如下:
Iterator it = collection.iterator(); // 获得一个迭代对象 while(it.hasNext()) { Object obj = it.next(); // 得到下一个元素 }
Set集合
Set是最简单的集合,集合中的对象不按照特定的方式排序。主要有如下两个实现:HashSet和TreeSet。
HashSet
HashSet类按照哈希算法来存取集合中的对象,具有很好的存取性能。当HashSet向集合中加入一个对象时,会调用对象的hashCode()方法获取哈希码,然后根据这个哈希码进一步计算出对象在集合中的存放位置。
TreeSet
TreeSet实现了SortedSet接口,可以对集合中的元素排序。如何排序的内容请参考其他文档,这里不做详述。
List集合
List继承自Collection接口。List是一种有序集合,List中的元素可以根据索引(顺序号:元素在集合中处于的位置信息)进行取得/删除/插入操作。
跟Set集合不同的是,List允许有重复元素。对于满足e1.equals(e2)条件的e1与e2对象元素,可以同时存在于List集合中。当然,也有List的实现类不允许重复元素的存在。同时,List还提供一个listIterator()方法,返回一个ListIterator接口对象,和Iterator接口相比,ListIterator添加元素的添加,删除,和设定等方法,还能向前或向后遍历,具体的方法往下看。List接口的实现类主要有ArrayList,LinkedList,Vector,Stack等。
List算法
Collections提供的多数多态方法都适用于List,在这里给出这些算法概览(以后会详谈):
| sort | 使用合并排序算法排序List,默认为升序排列 |
| shuffle | 使用随机源对指定列表进行置换。(洗牌) |
| reverse | 反转指定列表中元素的顺序 |
| rotate | 根据指定的距离轮换指定列表中的元素 |
| swap | 交换指定位置上的元素 |
| replaceAll | 使用一个值替换列表中出现的所有某一指定值 |
| fill | 使用指定元素替换列表中的所有元素 |
| copy | 将所有元素从一个列表复制到另一个列表 |
| binarySearch | 使用二分搜索法搜索指定列表,以获得指定对象 |
| indexOfSubList | 返回指定列表中第一次出现指定目标列表的起始位置;如果没有出现这样的目标,则返回-1 |
| lastIndexOfSubList | 返回指定源列表中最后一次出现指定目标列表的起始位置;如果没有出现这样的目标,则返回-1 |
ArrayList
ArrayList实现了可变大小的数组。它允许所有元素,包括null。ArrayList没有同步。size,isEmpty,get,set方法运行时间为常数。但是add方法开销为分摊的常数,添加n个元素需要O(n)的时间。其他的方法运行时间为线性。
每个ArrayList实例都有一个容量(Capacity),即用于存储元素的数组的大小。这个容量可随着不断添加新元素而自动增加,但是增长算法并没有定义。当需要插入大量元素时,在插入前可以调用ensureCapacity方法来增加ArrayList的容量以提高插入效率。
主要方法:
| public boolean add(E e) | 添加元素 |
| public void add(int index, E element) | 在指定位置添加元素 |
| public Iterator<E> iterator() | 取得Iterator对象便于遍历所有元素 |
| public E get(int index) | 根据索引获取指定位置的元素 |
| public E set(int index, E element) | 替换掉指定位置的元素 |
排序方法:
| Collections.sort(java.util.List<T>) | 对List的元素进行自然排序 |
| Collections.sort(java.util.List<T>, java.util.Comparator<? super T>) | 对List中的元素进行自定义排序 |
LinkedList
LinkedList实现了List接口,允许null元素。此外LinkedList提供额外的get,remove,insert方法在LinkedList的首部或尾部。这些操作使LinkedList可被用作堆栈(stack),队列(queue)或双向队列(deque)。
注意LinkedList没有同步方法。如果多个线程同时访问一个List,则必须自己实现访问同步。一种解决方法是在创建List时构造一个同步的List:
List list = Collections.synchronizedList(new LinkedList(...));
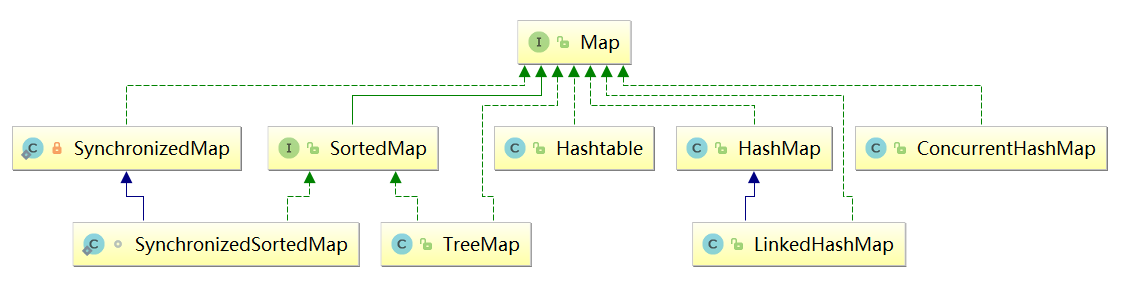
Map
- Map是一种把键对象和值对象进行映射的集合,它的每一个元素都包含一对键对象和值对象;
- 向Map添加元素时,必须提供键对象和值对象;
- 从Map中检索元素时,只要给出键对象,就可以返回对应的值对象;
- 键对象不能重复,但值对象可以重复;
- Map有两种常见的实现类:HashMap和TreeMap。
| V put(K key, V value) | 插入元素 |
| V get(Object key) | 根据键对象获取值对象 |
| Set<K> keySet() | 取得所有键对象集合 |
| Collection<V> values() | 取得所有值对象集合 |
| Set<Map.Entry<K, V>> entrySet() | 取得Map.Entry对象集合,一个Map.Entry代表一个Map中的元素 |
HashMap
HashMap按照哈希算法来存取键对象,有很好的存取性能。和HashSet一样,要求当两个键对象通过equals()方法比较为true时,这两个键对象的hashCode()方法返回的哈希码也一样。
TreeMap
TreeMap实现了SortedMap接口,能对键对象进行排序。同TreeSet一样,TreeMap也支持自然排序和客户化排序两种方式。
如果涉及到堆栈,队列等操作,应该考虑用List,对于需要快速插入,删除元素,应该使用LinkedList,如果需要快速随机访问元素,应该使用ArrayList。尽量返回接口而非实际的类型,如返回List而非ArrayList,这样如果以后需要将ArrayList换成LinkedList时,客户端代码不用改变。这就是针对抽象编程。