简介
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
awk有3个不同版本: awk、nawk和gawk,未作特别说明,一般指gawk,gawk 是 AWK 的 GNU 版本。
awk其名称得自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母。实际上 AWK 的确拥有自己的语言: AWK 程序设计语言 , 三位创建者已将它正式定义为“样式扫描和处理语言”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表,还有无数其他的功能。
流程
awk工作流程是这样的:先执行BEGING,然后读取文件,读入有/n换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域,随后开始执行模式所对应的动作action。接着开始读入第二条记录······直到所有的记录都读完,最后执行END操作。
如图:
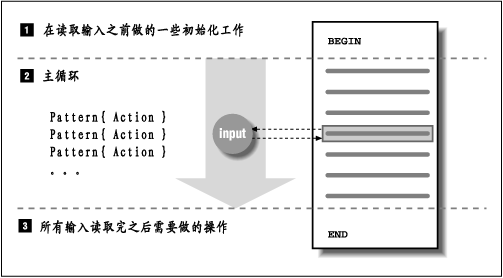
awk内置变量
awk有许多内置变量用来设置环境信息,这些变量可以被改变,下面给出了最常用的一些变量。
ARGC 命令行参数个数 ARGV 命令行参数排列 ENVIRON 支持队列中系统环境变量的使用 FILENAME awk浏览的文件名 FNR 浏览文件的记录数 FS 设置输入域分隔符,等价于命令行 -F选项 NF 浏览记录的域的个数 NR 已读的记录数 OFS 输出域分隔符 ORS 输出记录分隔符 RS 控制记录分隔符 ARGVIND 命令行参数索引(合并文件用过、)
FILENAME awk浏览的文件名NF 浏览记录的域的个数 NR 已读的记录数OFS 命令行参数索引(合并文件用过、)
Q1:打印目录下文件大小
A1:
[root@salt-node01 etc]# ls -al | awk -F " " 'BEGIN {filesize=0;print "[start]file size is",filesize;} {filesize=filesize+$5;} END{print "[end]file size is",filesize/1024,"K"}'
[start]file size is 0
[end]file size is 846.303 K
小结:
awk语法:-F配合“”指定分隔符,‘’用于指定pattern和action;BEGIN{}语句用于初始化变量和输出提示信息,第二个大括号{}中的内容,按照指定的分隔符,生成不同的域值,将field的内容进行对应的匹配和操作,最后END{}输出要表示的信息;如果在{}中需要进行for语句或者if语句,需要将循环条件或者判断条件用()进行包裹,后边紧跟{}进行statement语句。
此例中定义了一个变量filesize进行累计$5的操作,难度为1
Q2:打印奇数行
[root@salt-node01 awk_test]# seq 10 | awk 'i=!i'
等价于[root@salt-node01 ~]# seq 10 | awk 'BEGIN{}i=!i{print $0}END{}'
1
3
5
7
9
分析:seq 10进行数据模拟,输出1-10;awk处理流程,pattern和command的模式,此处无command,默认输出为$0,等价于seq 10 | awk '{i=!i;print $0}';此处只有pattern,pattern为i=!i; awk处理变量,对于未定义的变量,认为i是0,此处进行赋值i=1;1为真则匹配改行,打印$0;然后i=0,,,,,,所以只打印奇数行
验证:
[root@salt-node01 awk_test]# seq 10 | awk '{i=!i;print i}'
1 #打印
0 #不打印
1 #重复上述动作
0
1
0
1
0
1
0
Q3:如何打印偶数行?(BEGIN对i进行赋值即可)
[root@salt-node01 awk_test]# seq 10 | awk 'BEGIN{i=1} i=!i;'
2
4
6
8
10
Q4:行去重
进阶题:
[root@salt-node01 awk_test]# cat uniq.text bbb bbb bbb ccc ccc ccc aaa aaa aaa aaa aaa aaa aaa
请使用awk命令进行数据去重。
[root@salt-node01 awk_test]# awk '!a[$0]++' uniq.text bbb ccc aaa
分析:awk处理流程略,处理流程见上例;此处pattern是'!a[$0]++,C语言中++是先引用后赋值,此处a[bbb]是0,取反则是1,所以为真,awk读取第一行后,经过++运算(先引用后赋值)将a[bbb]设置为1,真则执行print $0,则打印第一行,第二行处理时a[bbb]为1,取反为0,所以为假,awk读取第二行后,经过++运算,将a[bbb]设置为2,,假则不进行action,第三行处理时,a[bbb]为2,同理不打印。
验证:
[root@salt-node01 awk_test]# awk '{!a[$0]++;print a[$0]}' uniq.text
1
2
3
1
2
3
1
2
3
4
5
6
7
Q5:分别计算每个字符串后面的数字总和
[root@salt-node01 awk_test]# cat uniq.text bbb 100 bbb 100 bbb 1 ccc 88 ccc 99 ccc 765 aaa 1 aaa 2 aaa 4 aaa 5 aaa 1008 aaa 876 aaa 123
答案:
[root@salt-node01 awk_test]# awk ' {a[$1]+=$2} END {for(i in a) print i,a[i]} ' uniq.text
aaa 2019
ccc 952
bbb 201
分析:awk问题该怎么做呢?归根到底是算法问题,比如在此例中,计算学生aaa的成绩总和,如果有个数组就方便很多,而shell外边向awk传变量也是一种思路,但是来回传递效率低,显得B格不够,此处用shell数组实现就很方便,awk是C语言的编程风格,+=是先加后赋值的语法,此处等同于a[$1]=a[$1]+$2;处理第一行,a[bbb]=0+100=100,处理第二行a[bbb]=100+100=200,处理第三行a[bbb]=200+1=201,同理,可以计算ccc bbb学生的成绩总和
Q6:计算学生成绩平均值及总和
要求输出格式:(average:平均成绩,total:总成绩)
name#######average#######total
zhangsan xxx xxx
lisi xxx xxx
wangwu xxx xxx
解法:
[root@localhost awk_test]# awk -F " " 'BEGIN{print "name#######average#######total"} {sum[$1]+=$2;total[$1]++} END {for (i in sum) print i,sum[i]/total[i],sum[i]}' 01.txt
name#######average#######total
zhangsan 85 255
wangwu 92.6667 278
lisi 87.1667 261.5
分析:此处BEGIN{}输出name等表头信息;{}用于域值的处理;END{}用for循环输出信息
Q7:假如把3列和4列的和值作为新的第5列,第5列的平均值为avg5,求第5列中大于avg5的行数
[root@localhost awk_test]# more 02.text 4 6 7 8 3 4 2 1 5 6 7 10 3 4 5 5 3 3 2 1 5 6 1 10
解法:
[root@localhost awk_test]# awk '{sum+=$3+$4;array[NR]=$3+$4}END{arg=sum/NR;for (i=1;i<=length(array);i++) {if (array[i]>arg) print i}}' 02.text
1
3
4
6
小结:
for语句和if语句进行循环处理时候,需要用()把条件进行包围,语法是C语言风格
if (expression) { statement; statement; ... ... }
此处是for语句的statement中嵌套了一个if语句
Q8:处理文件
02.text文件是
[root@salt-node01 awk_test.bak]# more 02.text 1.1.1.1 11 1.1.1.1 22 1.1.1.1 33 1.1.1.1 44 2.2.2.2 11 2.2.2.2 22 2.2.2.2 33 2.2.2.2 44
awk命令及输出结果:
[root@salt-node01 awk_test]# awk -F " " 'BEGIN{}{a[$1]=a[$1]" "$2}END{for (i in a){print i,a[i]}}' 02.text
1.1.1.1 11 22 33 44
2.2.2.2 11 22 33 44
分析:观察每次行读取处理后每行值的变化情况,第一次是1.1.1.1 11 第二次是1.1.1.1 11 22 ......应该是这样,用shell数组配合自增会是一个perfect的解决方案,array[$1]=array[$1]""[$2]
09:按照第三列进行排序:
[root@salt-node01 awk_test]# cat 03.text 12 34 56 78 90 12 34 56 89
方法01:sort命令
[root@salt-node01 awk_test]# cat 03.text |sort -t ' ' -k 3 78 90 12 12 34 56 34 56 89
方法02:awk方法
对于两个field的文件,用awk内置的asorti函数可以实现排序,三个field的文件,还需要进一步考虑,有时间看看。
10:连接2个文件,文件内容是:
[root@salt-node01 awk_test]# cat join.0* 100 wangyp 200 jack 300 tom 100 1000$ 200 1010$ 300 1100$
方法01:join
[root@salt-node01 awk_test]# join -a 1 join.01 join.02 100 wangyp 1000$ 200 jack 1010$ 300 tom 1100$
方法02:awk
[root@salt-node01 awk_test]# awk 'ARGIND==1{a[$1]=$0};ARGIND==2{print a[$1],$2}' join.01 join.02
100 wangyp 1000$
200 jack 1010$
300 tom 1100$
方法03:paste
[root@salt-node01 awk_test]# paste join.01 join.02 | awk '{print $1,$2,$NF}'
100 wangyp 1000$
200 jack 1010$
300 tom 1100$
方法04:
[root@salt-node01 awk_test]# awk 'NR==FNR{a[$1]=$0};NR>FNR{print a[$1],$2}' join.01 join.02
100 wangyp 1000$
200 jack 1010$
300 tom 1100$