前几天安装了Hadoop集群,还没有安装的参考:搭建集群hadoop - wanpi - 博客园 (cnblogs.com)
下载
官网下载链接:http://spark.apache.org/downloads.html
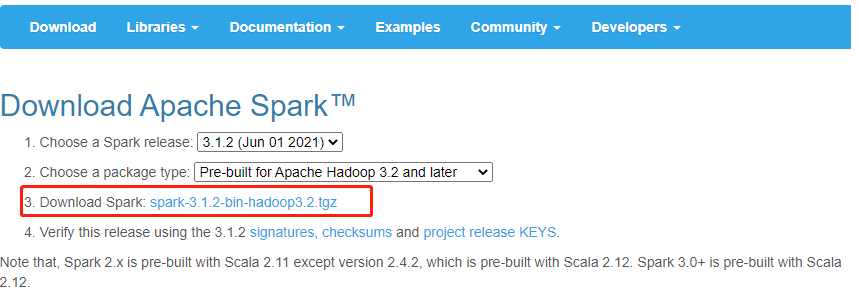
注意:可以选择hadoop,spark配套的安装包,如果之前安装过Hadoop,就不要选一套的了。我之前安装过Hadoop集群,所以我选择spark-2.4.7-bin-without-hadoop 这种不是一套的spark的安装包。存储在/home/hadoop目录下。
安装(四台机器都要执行)
下面的操作在四台机器上都要执行,我只以master节点为例。
在 /usr/local目录下,新建一个文件夹 spark-2.4.7。然后把spark-2.4.7-bin-without-hadoop目录下的东西复制到/usr/local/spark-2.4.7。
#创建文件夹
hadoop@master:$ sudo mkdir /usr/local/spark-2.4.7
#复制
hadoop@master:$ sudo cp -r /home/hadoop/spark-2.4.7-bin-without-hadoop/* /usr/local/spark-2.4.7
#把对/usr/local/spark-2.4.7的操作权限赋予hadoop用户
hadoop@master:$ sudo chown -R hadoop:hadoop /usr/local/hadoop
把spark的环境变量添加到 ~/.bashrc 中
hadoop@master:/usr/local/spark-2.4.7$ sudo vim ~/.bashrc
export SPARK_HOME=/usr/local/spark-2.4.7
export PATH=$JAVA_HOME/bin:$SPARK_HOME/bin:$PATH
#一定要更新,使~/.bashrc的生效
hadoop@master:/usr/local/spark-2.4.7$ source ~/.bashrc
配置(只在master节点执行)
下面的操作只在master节点进行。
进入/usr/local/spark-2.4.7/conf目录下
hadoop@master:/usr/local/spark-2.4.7$ cd ./conf
hadoop@master:/usr/local/spark-2.4.7/conf$ sudo vim ./spark-env,sh
#加入以下内容,第一个export重要!重要!重要!一定不要忘记修改
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export SPARK_MASTER_IP=10.60.238.130
export SPARK_WORKER_MEMORY=6g
export SPARK_WORKER_CORES=4
export SPARK_MASTER_PORT=7077
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/lib/jvm/java-8-openjdk-amd64/jre/lib/amd64
把slaves.template拷贝为slaves,并编辑 slaves文件
hadoop@master:/usr/local/spark-2.4.7/conf$ cp ./slaves.template slaves
hadoop@master:/usr/local/spark-2.4.7/conf$ sudo vim ./slaves
#加入以下内容
slave1
slave2
slave3
将配置文件/usr/local/spark-2.4.7/conf 下的内容同步到其他机器上,100%表示拷贝完毕
#scp -r ./conf hadoop@slave1:/usr/local/spark-2.4.7/
#注意@前面是hadoop用户,最后是/usr/local/spark-2.4.7/,不是/usr/local/spark-2.4.7/conf
hadoop@master:/usr/local/spark-2.4.7$ scp -r ./conf hadoop@slave1:/usr/local/spark-2.4.7/
spark-env.sh 100% 4630 2.7MB/s 00:00
docker.properties.template 100% 996 640.7KB/s 00:00
log4j.properties.template 100% 2025 1.7MB/s 00:00
fairscheduler.xml.template 100% 1105 1.2MB/s 00:00
slaves.template 100% 865 480.2KB/s 00:00
slaves 100% 888 548.8KB/s 00:00
metrics.properties.template 100% 7801 3.7MB/s 00:00
spark-defaults.conf.template 100% 1292 1.1MB/s 00:00
hadoop@master:/usr/local/spark-2.4.7$ scp -r ./conf hadoop@slave2:/usr/local/spark-2.4.7/
hadoop@master:/usr/local/spark-2.4.7$ scp -r ./conf hadoop@slave3:/usr/local/spark-2.4.7/
验证
jps命令验证:
进入到/usr/local/spark-2.4.7/sbin目录下,启动spark集群
#master节点
hadoop@master:/usr/local/spark-2.4.7/sbin$ ./start-all.sh
hadoop@master:/usr/local/spark-2.4.7/sbin$ jps
84437 Master
86214 Jps
#slave节点
hadoop@slave1:/usr/local/spark-2.4.7/conf$ jps
86164 Worker
86718 Jps
WEBUI界面验证:
浏览器输入:masterIP:8080
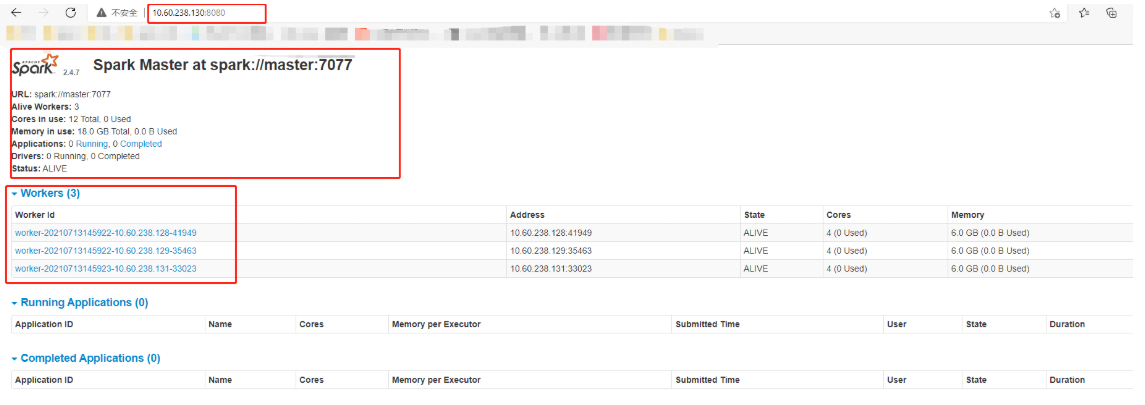
运行实例
hadoop@master:/usr/local/spark-2.4.7/bin$ spark-submit
--class org.apache.spark.examples.SparkPi
--master spark://master:7077
--executor-memory 1G
--total-executor-cores 2
/usr/local/spark-2.4.7/examples/jars/spark-examples_2.11-2.4.7.jar
结果
